The key is to use decision trees to partition the data space into clustered (or dense) regions and empty (or sparse) regions. In decision tree classification, we classify a new example by submitting it to a series of tests that determine the example’s class label. These tests are organized in a hierarchical structure called a decision tree.
Is decision tree a classification or regression model?
Whereas, classification is used when we are trying to predict the class that a set of features should fall into. A decision tree can be used for either regression or classification. It works by splitting the data up in a tree-like pattern into smaller and smaller subsets.
What are the uses of decision trees?
- Easy to use and understand - Trees are easy to create and visually simple to follow. ...
- Transparent - The diagrams for a decision clearly lay out the choices and consequences so that all alternatives can be challenged. ...
- Provides an evaluation framework - The value and likelihood of outcomes can be quantified directly on the tree chart.
What is a decision tree and how is it used?
Why do we need a Decision Tree?
- With the help of these tree diagrams, we can resolve a problem by covering all the possible aspects.
- It plays a crucial role in decision-making by helping us weigh the pros and cons of different options as well as their long-term impact.
- No computation is needed to create a decision tree, which makes them universal to every sector.
What are the advantages of decision trees?
What are the pros of decision trees?
- Easy to read and interpret. One of the advantages of decision trees is that their outputs are easy to read and interpret, without even requiring statistical knowledge.
- Easy to prepare.
- Less data cleaning required.
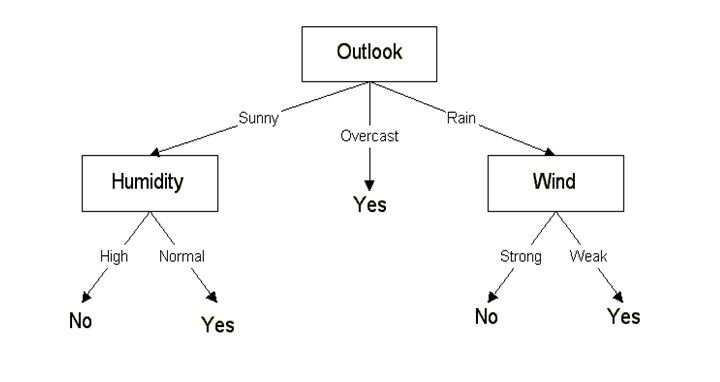
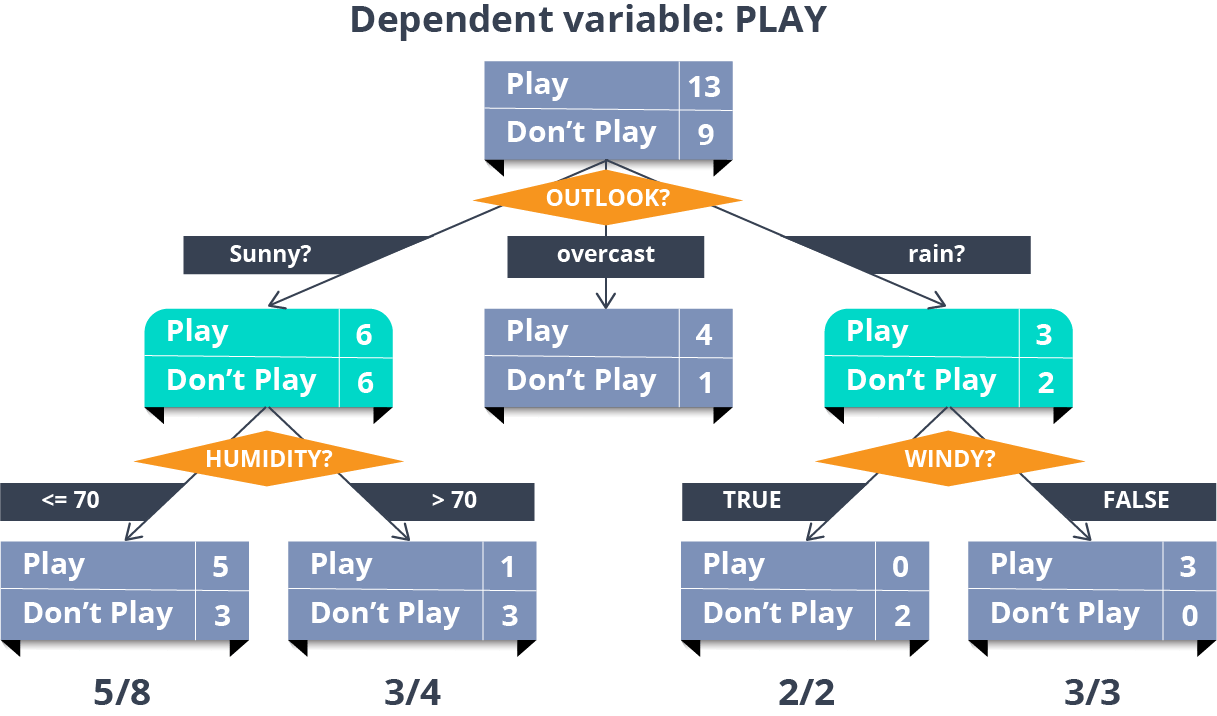
How decision tree is used for classification or regression?
A decision tree can be used for either regression or classification. It works by splitting the data up in a tree-like pattern into smaller and smaller subsets. Then, when predicting the output value of a set of features, it will predict the output based on the subset that the set of features falls into.
How does decision tree classification works explain with an example?
Decision tree uses the tree representation to solve the problem in which each leaf node corresponds to a class label and attributes are represented on the internal node of the tree. We can represent any boolean function on discrete attributes using the decision tree.
What is a decision tree how is it useful in classification with the help of an example explain the process of construction of a decision tree and its representation?
Decision Tree is the most powerful and popular tool for classification and prediction. A Decision tree is a flowchart-like tree structure, where each internal node denotes a test on an attribute, each branch represents an outcome of the test, and each leaf node (terminal node) holds a class label.
Which decision tree is used only for classification problem?
This methodology is more commonly known as learning decision tree from data and above tree is called Classification tree as the target is to classify passenger as survived or died. Regression trees are represented in the same manner, just they predict continuous values like price of a house.
Is it possible for a decision tree to classify all examples correctly?
This question is important because we need to find a decision tree that classifies all labeled examples correctly. This is always possible if decision trees can represent all Boolean functions. There might be many decision trees that are consistent with all labeled examples.
How do you explain a decision tree?
A decision tree is a type of supervised machine learning used to categorize or make predictions based on how a previous set of questions were answered. The model is a form of supervised learning, meaning that the model is trained and tested on a set of data that contains the desired categorization.
What is the difference between a classification tree and a decision tree?
The primary difference between classification and regression decision trees is that, the classification decision trees are built with unordered values with dependent variables. The regression decision trees take ordered values with continuous values.
What are the steps in making a decision tree?
How to create a decision treeStart with your idea. Begin your diagram with one main idea or decision. ... Add chance and decision nodes. ... Expand until you reach end points. ... Calculate tree values. ... Evaluate outcomes.
Are Decision Trees inclined to overfit?
Decision Trees fragment the complex data into simpler forms. A Decision Tree classification tries to divide data until it can’t be further divided....
Do Decision Trees need normalisation?
Decision Trees are the most common machine learning algorithm used for the classification and regression of data. This supervised mechanism splices...
How to splice Decision Trees?
Decision Trees are a reliable mechanism to classify data and predict solutions. Splicing in a Decision Tree requires precision; one slight mistake...
What are decision trees made of?
The answer to the question is straightforward. Decision trees are made of three essential things, the analogy to each one of them could be drawn to a real-life tree. All three of them are listed below:
Are Decision Trees inclined to overfit?
A clear chart of all the possible contents is then created, which helps in further analysis. While a vast tree with numerous splices gives us a straight path, it can also generate a problem when testing the data. This excessive splicing leads to overfitting, wherein many divisions cause the tree to grow tremendously. In such cases, the predictive ability of the Decision Tree is compromised, and hence it becomes unsound. Pruning is a technique used to deal with overfitting, where the excessive subsets are removed.
Do Decision Trees need normalisation?
Since this data will be split into categories based on the provided attributes, it will be evenly split. It conveys that both data that went through normalisation and data that didn’t would have the same number of splits. Therefore, normalisation is not a prerequisite for decision-based tree models.
How to splice Decision Trees?
Decision Trees are a reliable mechanism to classify data and predict solutions. Splicing in a Decision Tree requires precision; one slight mistake can compromise the Decision Tree’s integrity. Splicing in a Decision Tree occurs using recursive partitioning. Splitting data starts with making subsets of data through the attributes assigned to it. The data is split recursively in repetition until the spliced data at each node is deemed obsolete in predicting solutions. The subset can be similar to the value of the target variable as well. Splicing has to be methodical and repetitive for good accuracy.
How is decision tree classifier built?
It is apparent that the decision tree classifier is based and built by making use of a heuristic known as recursive partitioning, also known as the divide and conquer algorithm. It breaks down the data into smaller sets and continues to do so. Until it has determined that the data within each subset is homogenous, or if the user has defined another stopping criterion, that would put a stop to this algorithm.
How are decision trees constructed?
These types of trees are usually constructed by employing a process which is called binary recursive partitioning. The method of binary recursive partitioning involves splitting the data into separate modules or partitions, and then these partitions are further spliced into every branch of the decision tree classifier.
What is decision tree in machine learning?
Trees have made their impact on a considerable area of machine learning. They cover both the essential classification and regression. When analyzing any decision, a decision tree classifier could be employed to represent the process of decision making. So, basically, a decision tree happens to be a part of supervised machine learning where ...
What does lower partial impurity mean?
This will yield a value of 0.43622. A lower partial impurity means a node that is better at separating the classes.
What is the partial impurity of the right node?
The partial impurity for the right node is 0.5. Notice how it is higher because we have a tougher time when we want to separate the classes.
What is Random Forest?
Random Forest, XGBoost or LightGBM are some of the algorithms that lean on this simple, yet effective idea of building an algorithm based on if-else rules.
What is decision tree?
Decision trees are actually pretty simple and can be summarized in a “simple” sentence: “ decision trees are algorithms that recursively search the space for the best boundary possible, until we unable them to do so ”. Let’s cut the jargon and break this sentence down, mathematically.
What is the root node of a tree?
Root Node is the base of our tree, where we have all our boxes of eggs before the split.
Why do we want to select the split that will achieve minimum impurity?
By design, we will want to select the split that will achieve minimum impurity — because that split will translate into better dividing the classes.
What is the probability of a valid package?
If you look at the left node, the probability of a both valid or broken package is exactly the same, 5/10 or 50%. It’s harder for us to classify points below the 1.5 threshold because there is no difference between the number of examples in each class.
What is Gini index?
When performing classification tasks, the Gini index function is used. From Corrado Gini, this function informs us of how “pure” the leaf nodes in the tree are. The gini impurity will always be a value from 0 to 0.5, the higher the value, the more disordered the group is. To calculate the gini impurity:
What is decision tree?
Decision trees are great predictive models that can be used for both classification and regression. They are highly interpretable and powerful for a plethora of machine learning problems. While there are many similarities between classification and regression tasks, it is important to understand different metrics used for each. The hyperparameters for decision trees are helpful in combating their tendency to overfit to the training data. Something to note, while performing a grid search can help in finding optimal hyperparameters for a decision tree, they can also be very computationally expensive. You may have a grid search running for hours or even days depending on the possible parameters chosen.
What is the metric used to determine the entropy of a decision tree?
A widely used metric with decision trees is entropy. Shannon’s Entropy , named after Claude Shannon provides us with measures of uncertainty. When it comes to data, entropy tells us how messy our data is. A high entropy value indicates less predictive power, think of the entropy of a feature as the amount of information in that feature. Decision trees work to maximize the purity of the classes when making splits, providing more clarity of the classes in the leaf nodes. The entropy is calculated before and after each split. If the entropy increases, another split will be tried or the branch of the tree will stop, i.e., the current tree has the lowest entropy . If the entropy decreases, the split will be kept. The formula for calculating entropy of an entire dataset:
What is information gain?
Information gain uses entropy as a measure of impurity. It is the difference in entropy from before to after the split, and will give us a number to how much the uncertainty has decreased. It is also the key criterion used in the ID3 classification tree algorithm. To calculate the information gain:
What is the R-squared value?
When evaluated the performance of the model, we will be looking at the root mean squared error (RMSE). This is just the square root of the mean of squared errors. By taking the square root we can measure the size of error that weights large errors more than the mean. The metric we will use for evaluating the goodness of fit for our model is the R-squared value. The r-squared tells us the percentage of the variance in the dependant variables explain collectively (Frost et al., 2020).
What is the benefit of using crossvalidated grid search?
By running the cross-validated grid search, the best parameters improved our bias-variance tradeoff. The first model with default parameters performed 20% better on the train set than the test set, indicating low-bias and high variance in the tree. The decision tree with the hyperparameters set from the grid search shows the variance was decreased with a 5% drop-off in accuracy from the train and test sets.
How to describe decision trees?
The st r ucture of a decision tree can be thought of as a Directed Acyclic Graph, a sequence of nodes where each edge is directed from earlier to later. This graph flows in one direction and no object can be a child of itself. Take a look at the DAG above, we can see it starts with a root node, the best attributes become interior nodes, i.e., decision nodes. Then, the internal nodes check for a condition and perform a decision, partitioning the sample space in two. The leaf nodes represent a classification, when the record reaches the leaf node, the algorithm will assign the label of the corresponding leaf. This process is referred to as recursive partitioning of the sample space. Terminology when working with decision trees:
What is the blue decision node?
It is the node from which all other decision, chance, and end nodes eventually branch.
What is overfitting in decision tree?
Overfitting (where a model interprets meaning from irrelevant data) can become a problem if a decision tree’s design is too complex.
What is the lilac end node?
In the diagram above, the lilac end nodes are what we call ‘leaf nodes.’ These show the end of a decision path (or outcome). You can always identify a leaf node because it doesn’t split, or branch any further. Just like a real leaf!
Why is predictive analysis cumbersome?
In predictive analysis, calculations can quickly grow cumbersome, especially when a decision path includes many chance variables. When using an imbalanced dataset (i.e. where one class of data dominates over another) it is easy for outcomes to be biased in favor of the dominant class.
What is decision tree?
1. What is a decision tree? In its simplest form, a decision tree is a type of flowchart that shows a clear pathway to a decision. In terms of data analytics, it is a type of algorithm that includes conditional ‘control’ statements to classify data. A decision tree starts at a single point (or ‘node’) which then branches (or ‘splits’) ...
What is branching in biology?
Branching or ‘splitting’ is what we call it when any node divides into two or more sub-nodes. These sub-nodes can be another internal node, or they can lead to an outcome (a leaf/ end node.)
What is the purpose of decision trees in emergency room triage?
Emergency room triage might use decision trees to prioritize patient care (based on factors such as age, gender, symptoms, etc.)
What is the difference between classification and regression?
In the above example, regression is used to predict the student’s marks. Whereas, classification is used to predict whether the student has passed or failed the exams.
What is classification tree?
A classification tree splits the dataset based on the homogeneity of data. Say, for instance, there are two variables; salary and location; which determine whether or not a candidate will accept a job offer.
How does regression work in a tree?
In a regression tree, a regression model is fit to the target variable using each of the independent variables. The data is then split at several points for each independent variable.
How does a decision tree work?
A decision tree can be used for either regression or classification. It works by splitting the data up in a tree-like pattern into smaller and smaller subsets. Then, when predicting the output value of a set of features, it will predict the output based on the subset that the set of features falls into.
What is decision tree algorithm?
If we strip down to the basics, decision tree algorithms are nothing but a series of if-else statements that can be used to predict a result based on the data set. This flowchart-like structure helps us in decision-making.
When to use regression or classification?
Regression is used when we are trying to predict an output variable that is continuous. Whereas, classification is used when we are trying to predict the class that a set of features should fall into.
Why are decision trees easy to understand?
Amazing isn’t it! Such a simple decision-making is also possible with decision trees. They are easy to understand and interpret because they mimic human thinking.