
Set Up Sqoop
- In Cloudera Manager, in Clusters, select Add Service from the options menu.
- Select the Sqoop Client and click Continue.
- Choose a JDBC database driver, depending on the data source of the source or destination for a Sqoop import or export, respectively.
- Install the JDBC database driver in /var/lib/sqoop on the Sqoop node. ...
- In Cloudera Manager, click Actions > Deploy Client Configuration.
- Step 1: Verifying JAVA Installation. ...
- Step 2: Verifying Hadoop Installation. ...
- Step 3: Downloading Sqoop. ...
- Step 4: Installing Sqoop. ...
- Step 5: Configuring bashrc. ...
- Step 6: Configuring Sqoop. ...
- Step 7: Download and Configure mysql-connector-java. ...
- Step 8: Verifying Sqoop.
How do I install Sqoop on Ubuntu?
1. Custom Sqoop Installation Step 1: Download Sqoop Step 2: Start with the Sqoop installation Step 3: Configure bashrc file Step 4: Configure Sqoop now Step5: Configure MySQL Step 6: Verify Sqoop
How to set up Sqoop with Hadoop?
You have to set up the Sqoop environment by appending the following lines to ~/ .bashrc file − The following command is used to execute ~/ .bashrc file. To configure Sqoop with Hadoop, you need to edit the sqoop-env.sh file, which is placed in the $SQOOP_HOME/conf directory.
How to use Sqoop with JDBC and connectors?
Sqoop always requires “JDBC” and “Connectors”. Here JDBC, i.e. MySQL, Oracle, etc. and Connectors such as Oraoop or Cloudera. Here are the steps to follow the sqoop action, which are explained below: Step 1: It sends the request to RDBMS to send the return of the metadata information about the table (Metadata here is the data about the data).
What is set up Sqoop Cloudera runtime?
Set Up Sqoop Cloudera Runtime includes the Sqoop Client for bulk importing and exporting data from diverse data sources to Hive. You learn how to install the RDBMS connector and Sqoop Client in CDP.
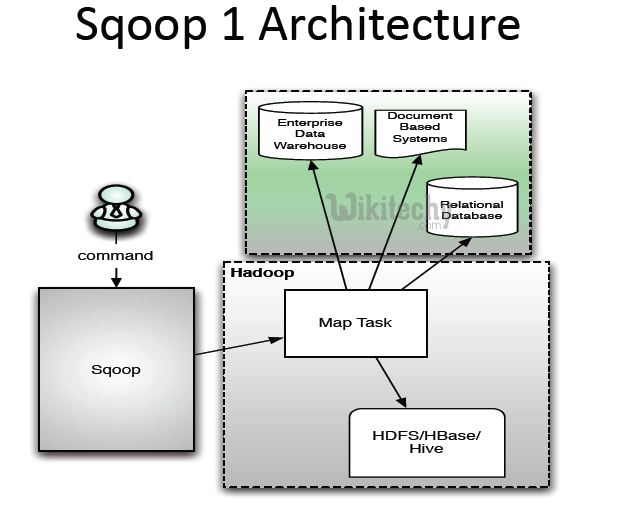
Can Sqoop run without Hadoop?
To run Sqoop commands (both sqoop1 and sqoop2 ), Hadoop is a mandatory prerequisite. You cannot run sqoop commands without the Hadoop libraries.
How do I use Apache Sqoop?
1:3728:51Sqoop Import Data From MySQL to HDFS | Simplilearn - YouTubeYouTubeStart of suggested clipEnd of suggested clipYour data filing system and that's where Skoob comes in so what exactly is scoop scoop is a toolMoreYour data filing system and that's where Skoob comes in so what exactly is scoop scoop is a tool used to transfer bulk of data between Hadoop. And external data stores such as relational databases.
Is Apache Sqoop still used?
Sqoop is a command-line interface application for transferring data between relational databases and Hadoop. The Apache Sqoop project was retired in June 2021 and moved to the Apache Attic.
What is Sqoop in Hadoop?
Sqoop is a tool designed to transfer data between Hadoop and relational database servers. It is used to import data from relational databases such as MySQL, Oracle to Hadoop HDFS, and export from Hadoop file system to relational databases.
Is Sqoop an ETL tool?
Apache Sqoop and Apache Flume are two popular open source etl tools for hadoop that help organizations overcome the challenges encountered in data ingestion.
How do I start Sqoop in Hadoop?
Follow the steps given below to install Sqoop on your system.Step 1: Verifying JAVA Installation. ... Step 2: Verifying Hadoop Installation. ... Step 3: Downloading Sqoop. ... Step 4: Installing Sqoop. ... Step 5: Configuring bashrc. ... Step 6: Configuring Sqoop. ... Step 7: Download and Configure mysql-connector-java. ... Step 8: Verifying Sqoop.
What replaced Sqoop?
Apache Spark, Apache Flume, Talend, Kafka, and Apache Impala are the most popular alternatives and competitors to Sqoop.
Why Sqoop is needed?
Apache Sqoop is designed to efficiently transfer enormous volumes of data between Apache Hadoop and structured datastores such as relational databases. It helps to offload certain tasks, such as ETL processing, from an enterprise data warehouse to Hadoop, for efficient execution at a much lower cost.
How do I know if Sqoop is installed?
The following steps are used to verify the Hadoop installation.Step 1: Name Node Setup. Set up the namenode using the command “hdfs namenode -format” as follows. ... Step 2: Verifying Hadoop dfs. ... Step 3: Verifying Yarn Script. ... Step 4: Accessing Hadoop on Browser. ... Step 5: Verify All Applications for Cluster.
What are the 2 main functions of Sqoop?
Using Sqoop, you can provision the data from an external system into HDFS, as well as populate tables in Hive and HBase. Similarly, Sqoop integrates with the workflow coordinator Apache Oozie (incubating), allowing you to schedule and automate import/export tasks.
Who uses Apache Sqoop?
Companies Currently Using Apache SqoopCompany NameWebsiteSub Level IndustryUnitedhealth Groupunitedhealthgroup.comInsurance & Managed CareBank of Americabankofamerica.comBankingCiticiti.comBankingWells Fargowellsfargo.comGeneral Financial Services & Insights2 more rows
What is in Sqoop command?
Sqoop – IMPORT Command with target directory -m property is used to specify the number of mappers to be executed. Sqoop imports data in parallel from most database sources. You can specify the number of map tasks (parallel processes) to use to perform the import by using the -m or –num-mappers argument.
How do I import data into Sqoop?
Importing data from MySQL to HDFSStep 1: Login into MySQL mysql -u root -pcloudera. ... Step 2: Create a database and table and insert data. ... Step 3: Create a database and table in the hive where data should be imported. ... Step 4: Run below the import command on Hadoop. ... Step 1: Create a database and table in the hive.More items...•
Where is Sqoop used?
Sqoop is used to transfer data from RDBMS (relational database management system) like MySQL and Oracle to HDFS (Hadoop Distributed File System). Big Data Sqoop can also be used to transform data in Hadoop MapReduce and then export it into RDBMS.
What is Sqoop command?
Sqoop – IMPORT Command Import command is used to importing a table from relational databases to HDFS. In our case, we are going to import tables from MySQL databases to HDFS. As you can see in the below image, we have employees table in the employees database which we will be importing into HDFS.
How do I know if Sqoop is installed?
The following steps are used to verify the Hadoop installation.Step 1: Name Node Setup. Set up the namenode using the command “hdfs namenode -format” as follows. ... Step 2: Verifying Hadoop dfs. ... Step 3: Verifying Yarn Script. ... Step 4: Accessing Hadoop on Browser. ... Step 5: Verify All Applications for Cluster.
How to configure Sqoop with Hadoop?
To configure Sqoop with Hadoop, you need to edit the sqoop-env.sh file, which is placed in the $SQOOP_HOME/conf directory. First of all, Redirect to Sqoop config directory and copy the template file using the following command −
How does a sqoop job work?
This chapter describes how to create and maintain the Sqoop jobs. Sqoop job creates and saves the import and export commands. It specifies parameters to identify and recall the saved job. This re-calling or re-executing is used in the incremental import, which can import the updated rows from RDBMS table to HDFS.
What is Sqoop import?
Sqoop tool ‘import’ is used to import table data from the table to the Hadoop file system as a text file or a binary file.
What is a Hadoop site.xml file?
The hdfs-site.xml file contains information such as the value of replication data, namenode path, and datanode path of your local file systems. It means the place where you want to store the Hadoop infrastructure.
How to import a subset of a table in Sqoop?
We can import a subset of a table using the ‘where’ clause in Sqoop import tool. It executes the corresponding SQL query in the respective database server and stores the result in a target directory in HDFS.
What is the default port number for Hadoop?
The default port number to access Hadoop is 50070. Use the following URL to get Hadoop services on your browser.
Where to find Hadoop configuration files?
You can find all the Hadoop configuration files in the location “$HADOOP_HOME/etc/hadoop”. You need to make suitable changes in those configuration files according to your Hadoop infrastructure.
How Do I Query In Sqoop?
SQL statements are passed from -table, -columns, and -where to -query instead of using the [ -table, -columns, and -where ], which would specify -table etc. The resulting results will only return tables if, with the *target-dir argument, we specify the destination directory.
How Do I Run A Sqoop Script?
In case you would like to write the sqoop eval command on the command line, you must create a vi sqoop_eval.sh file.
How Do You Check Sqoop Is Installed Or Not?
Set up your namenode using the command “hdfs namenode -format” as the key for setting it up…
What Is Sqoop Used For?
HDFS (Hadoop distributed file system) is used to distribute data from RDBMS (relational database management systems) like MySQL and Oracle to SQL Server on the fly using Sqoop. Data may be exported in RDBMS from Big Data Sqoop along with data transformed in Hadoop MapReduce.
Where Do I Put Mysql Connector?
For more information about the MySQL Connector and J drivers go to dev.mysql.com.
Can Sqoop Work On Windows?
Here are the necessary requirements: * I intend to use a 64-bit version of Windows 10 for the process. It is recommended that you check and download the version of all the software that’s supported by your system. According to my computer dictionary, I’m using Hadoop-2. In addition, all hadoop STABLE versions will work. The SQOOP system is also possible with any other STABLE version.
1. Sqoop Installation – Objective
In this Sqoop Tutorial, we study “Sqoop Installation” explains all the steps to install Sqoop on Linux. Since we know Sqoop is Hadoop’s sub-project. Thus, it can only work on a Linux operating system. Hence, at first, we will see the installation of some prerequisites to run Sqoop 1.4.5 Installation.
2. Java Installation
Before Sqoop installation – version 1.4.5 on Linux, at very first we need to have Java installed on our system. In order to install Java on our system, we need to follow various steps given below. Step 1 By visiting the following link, download Java (JDK <latest version> – X64.tar.gz). Hence, jdk-7u71-linux-x64.tar.gz will be downloaded on our system. Step 2 Basically, we find the downloaded Java file in the downloads folder.
3. Hadoop Installation
It is very important that before Sqoop installation, Hadoop is installed on our system. Follow these steps if Hadoop is not installed on your system: a.
4. Sqoop Download – Sqoop Installation
Basically, we can download the latest version of Sqoop from here: Download sqoop For this Sqoop Installation tutorial, we are using version 1.4.5, that is, sqoop-1.4.5.bin__hadoop-2.0.4-alpha.tar.gz.
5. Conclusion
Hence, in this Sqoop installation tutorial, we study how Sqoop download & install Sqoop by verifying Java Installation. At last, how to Download Hadoop and Verifying Hadoop Installation. Furthermore, if you feel any query regarding Sqoop installation, feel free to ask in the comment section. See Also- Sqoop Eval & Sqoop Codegen For reference
How to complete sqoop?
Here are the steps to follow the sqoop action, which are explained below: Step 1: It sends the request to RDBMS to send the return of the metadata information about the table (Metadata here is the data about the data). Step 2: From the received information, it will generate the java classes ...
What is Sqoop import?
Sqoop import command imports a table from an RDBMS to HDFS. Each record from a table is considered as a separate record in HDFS. Records can be stored as text files or in binary representation as Avro or SequenceFiles.
What is sqoop used for?
What is Sqoop? These are the basic points of sqoop, which are explained below: It is used to transfer the bulk of data between HDFS and Relational Database Servers. It is used to import the data from RDBMS to Hadoop and export the data from Hadoop to RDBMS. It uses Map Reduce for its import and export operation.
What are the advantages and disadvantages of sqoop?
Here are the advantage and disadvantages of sqoop, which are explained below: You need to restrict access to the password file. The Sqoop job will be executed with the permissions of the user running the –exec operation rather than the user who created the saved job.
What is the strength of Sqoop?
A significant strength of Sqoop is its ability to work with all major and minor database systems and enterprise data warehouses. It is a command-line tool that can be called from any shell implementation, such as bash. It also supports the Linux Operating System, which is very easy to deal with any of the operations.
How many types of scoops are there?
There are two types of scoop, which are explained below:
Can Apache Sqoop handle full load?
Apache Sqoop can handle the full load by just a single command which we can call it a Sqoop with full load power. It also has incremental load power; you can just load the path of the table where it is updated. It uses the Yarn framework to import and export the data, which provides fault tolerance on top of parallelism.
