- Training data. ...
- Choose appropriate activation functions. ...
- Number of Hidden Units and Layers. ...
- Weight Initialization. ...
- Learning Rates. ...
- Hyperparameter Tuning: Shun Grid Search - Embrace Random Search. ...
- Learning Methods. ...
- Keep dimensions of weights in the exponential power of 2.
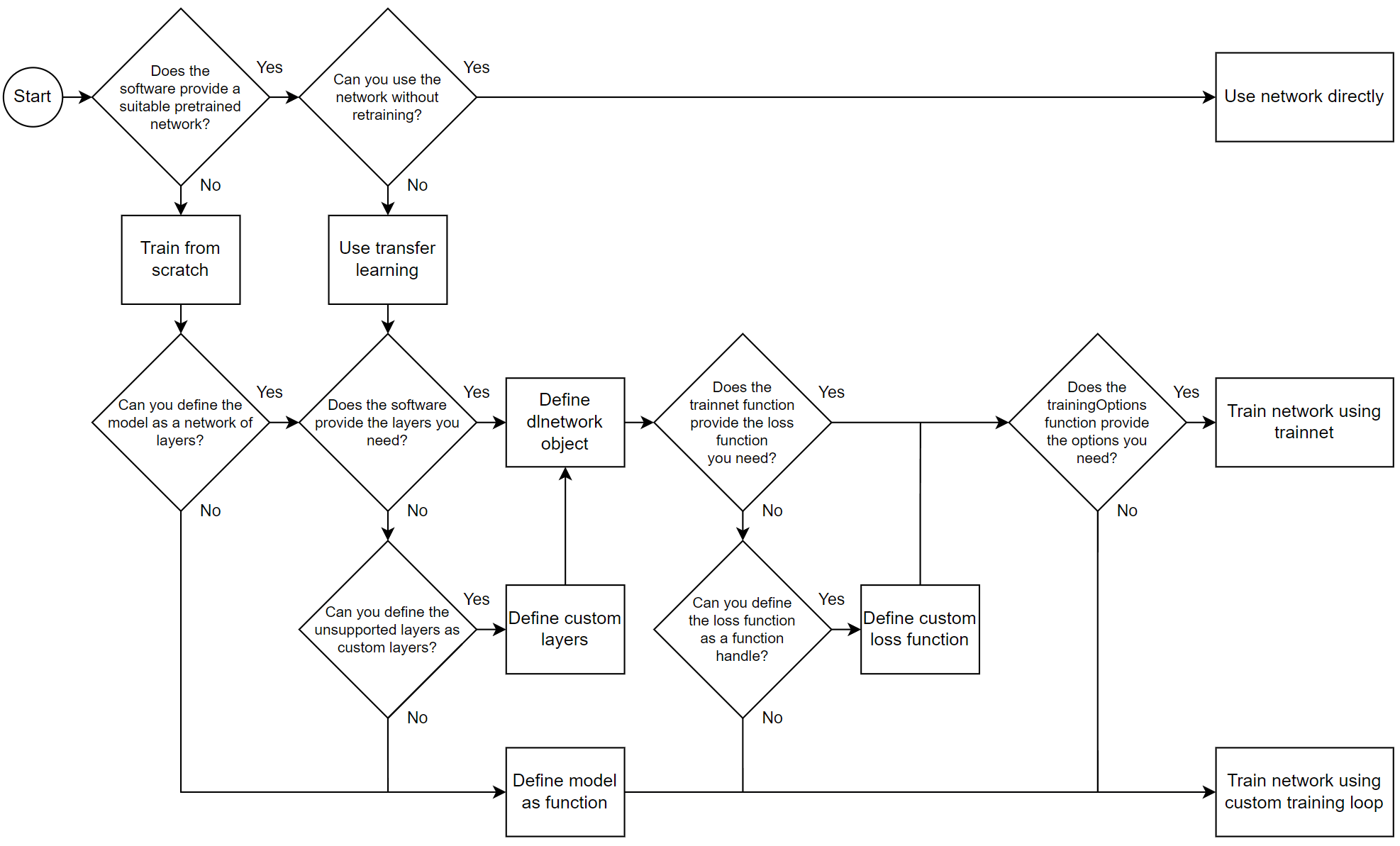
Which algorithm is used to train deep networks?
Generative Adversarial Networks (GANs) GANs are generative deep learning algorithms that create new data instances that resemble the training data. GAN has two components: a generator, which learns to generate fake data, and a discriminator, which learns from that false information.
Why is it hard to train a deep neural network?
Training a neural network involves using an optimization algorithm to find a set of weights to best map inputs to outputs. The problem is hard, not least because the error surface is non-convex and contains local minima, flat spots, and is highly multidimensional.
How do I start deep model training?
These five tips can help guide an enterprise into training deep models the right way.Gathering more data is the smart approach. ... When using limited data sets, focus on the approach. ... Decrease strain through federated deep learning. ... Consider reinforcement learning. ... Continue to retrain the model and build the right workflow.
Should I learn deep or AI first?
If you're looking to get into fields such as natural language processing, computer vision or AI-related robotics then it would be best for you to learn AI first.
Can I learn deep learning in 1 month?
you cannot learn Machine learning in one month and even if you did cover the topic, then also it wouldn't be fruitful to you as you might not have grasped the subject's depth and because of lack of practice, you will not be technically strong.
How long does it take to train an ML model?
Training usually takes between 2-8 hours depending on the number of files and queued models for training. In case you are facing longer time you can chose to upgrade your model to a paid plan to be moved to the front of the queue and get more compute resources allocated.
How much data do I need to train my model?
For example, if you have daily sales data and you expect that it exhibits annual seasonality, you should have more than 365 data points to train a successful model. If you have hourly data and you expect your data exhibits weekly seasonality, you should have more than 7*24 = 168 observations to train a model.
How many images do you need to train a model?
Usually around 100 images are sufficient to train a class. If the images in a class are very similar, fewer images might be sufficient. the training images are representative of the variation typically found within the class.
Are deeper networks more difficult to train?
Deeper networks are harder to train Various methods have been proposed to deal with this problem. He et al. [HE:2016] proposed the deep residual network (ResNet) architecture. ResNet uses a randomly initialised first order method to train neural networks with an order of magnitude more layers.
Is deep learning difficult to learn?
Deep learning is powerful exactly because it makes hard things easy. The reason deep learning made such a splash is the very fact that it allows us to phrase several previously impossible learning problems as empirical loss minimisation via gradient descent, a conceptually super simple thing.
How long does it take to train a deep neural network?
Training usually takes between 2-8 hours depending on the number of files and queued models for training. In case you are facing longer time you can chose to upgrade your model to a paid plan to be moved to the front of the queue and get more compute resources allocated.
What are the challenges of neural network?
Deep Neural Networks Addressing 8 Challenges in Computer VisionNetwork Compression. ... Pruning. ... Reduce the Scope of Data Values. ... Fine-Grained Image Classification. ... Bilinear CNN. ... Texture Synthesis and Style Transform. ... Face Verification/Recognition. ... Image Search and Retrieval.
The intuition behind finding the weights of a neural network, with an example
In this article, I will continue our discussion on artificial neural networks, and give an example of a very simple neural network written in python. The purpose of this series of articles I am writing is to give a full explanation of ANN’s from the ground up, with no hiding behind special libraries.
Mapping inputs to outputs
Say we have a list of inputs and their outputs. These could be anything, stock features and price, property features and sale price, student behaviors and average test scores, they could be whatever; but let’s keep things general and say we have some inputs and outputs.
Measuring how wrong we are, using an error function
So, let’s have some fun. How could we solve for the weights without treating this as a system of linear equations? Well, you have to start somewhere, so let’s first just throw a blind guess at what they could be. I’m going to guess that W1 = .2, W2 = 1.4, and W3 = 30.
Minimizing how wrong we are (minimizing our error)
When you change a weight by a very small amount (∂W), you get and change in error (∂E). So, if we wanted to find how much a change in this weight affects the error, we can take the ratio of the 2, ∂E/∂W.
Quick Summary
Let me summarize the past 2 pages. We have data and some outputs. We know there is some relationship between this data and the outputs. Inspired by the human brain, we can construct an artificial neural network. We initialize this neural network with random weights, then start testing it on the data and outputs we have.
What is the core of a neural network?
The core of any neural network is the optimizer. In order to determine the appropriate weights for prediction, each neural network optimises a loss function. There are several different types of optimizers, each with a somewhat different technique to identifying the optimal weights.
When does the nonlinear topology fail?
This paradigm fails when any of the layers in the stack have numerous inputs or outputs. Even if we want non-linear topology, it isn’t suitable.
What is the core layer class?
It also offers the Core Layers class, which contains the classes required to generate core layers such as Dense, Activation, and Embedding. Convolution Layers can be created in a variety of ways using the Convolution Layer class. The Pooling Layers class contains the methods required for Max Pooling, Average Pooling, Global Max Pooling, and Global Average Pooling, as well as other types of pooling.
What is a deep neural network?
At its simplest, a neural network with some level of complexity, usually at least two layers, qualifies as a deep neural network (DNN), or deep net for short. Deep nets process data in complex ways by employing sophisticated math modeling.
What is the deep net?
The Deep Net allows a model to make generalizations on its own and then store those generalizations in a hidden layer, the black box. The black box is hard to investigate. Even if the values in the black box are known, they don’t exist within a framework for understanding.
How many nodes are there in a deep net?
It doesn’t matter which ML platform you use; directing the model to use two or 2,000 no des in each layer is as simple as typing the characters 2 or 2000.
Do deep neural nets capitalize?
Deep neural nets, then, capitalize on the ANN component. They say, if that works so well at improving a model—because each node in the hidden layer makes both associations and grades importance of the input to determining the output—then why not stack more and more of these upon each other and benefit even more from the hidden layer?
What is the next step in building a convolutional neural network?
The next step in building our convolutional neural network is adding our flattening layer. As a quick refresher, the role of the flattening layer is to transform the output of the previous pooling layer (which is called the pooled feature map) into a one-dimensional vector.
What is the full connection step in a convolutional neural network?
As a refresher, the full connection step within a convolutional neural network is simply a standalone layer of an artificial neural network where every neuron is connected to each neuron in the previous layer.
What Python library is used for convolutional neural networks?
This convolutional neural network tutorial will make use of a number of open-source Python libraries, including NumPy and (most importantly) TensorFlow.
What does it mean to compile a CNN?
To compile a CNN means to connect it to an optimizer, a loss function, and some metrics. We are doing binary classification with our convolutional network, just like we did with our artificial neural network earlier in this course. This means that we can use the same optimizer, loss function, and metrics.
What is the output of our specific full connection step?
The output of our specific full connection step will be a binary cat/dog classification determined by a Sigmoid function.
Why do we add extra transformations to training data?
The reason for this is that to avoid overfitting, we will add an extra transformation to the training data images.
Do you need data to train a model?
To do this, you will need a data set to train the model. I have stored the data set for this tutorial in a GitHub repository. You can click here to access the repository.
Mapping Inputs to Outputs
- Say we have a list of inputs and their outputs. These could be anything, stock features and price, property features and sale price, student behaviors and average test scores, they could be whatever; but let’s keep things general and say we have some inputs and outputs. Our goal is to predict the output to that last input. To do this, we must find ...
Measuring How Wrong We Are, Using An Error Function
- So, let’s have some fun. How could we solve for the weights without treating this as a system of linear equations? Well, you have to start somewhere, so let’s first just throw a blind guess at what they could be. I’m going to guess that W1 = .2, W2 = 1.4, and W3 = 30. Now let’s see how good our guess was and test it on one of the inputs (using the same data in the table above). Recall, the c…
Minimizing How Wrong We Are
- When you change a weight by a very small amount (∂W), you get and change in error (∂E). So, if we wanted to find how much a change in this weight affects the error, we can take the ratio of the 2, ∂E/∂W. This can be recognized as the partial derivative of the error function with respect to this weight, or how a small change in this weight changes the error. How does this help us? Well, if y…
Quick Summary
- Let me summarize the past 2 pages. We have data and some outputs. We know there is some relationship between this data and the outputs. Inspired by the human brain, we can construct an artificial neural network. We initialize this neural network with random weights, then start testing it on the data and outputs we have. As we are testing, we quantify how wrong our network is by us…