
- Sign in to the AWS Management Console and open the CodePipeline console at http://console.aws.amazon.com/codesuite/codepipeline/home.
- On the Welcome page, choose Create pipeline. If this is your first time using CodePipeline, choose Get Started.
- On the Step 1: Choose pipeline settings page, in Pipeline name, enter the name for your pipeline. ...
- In Service role, do one of the following: Choose New service role to allow CodePipeline to create a new service role in IAM. ...
- (Optional) Expand Advanced settings.
- In Artifact store, do one of the following: Choose Default location to use the default artifact store, such as the S3 artifact bucket designated as the default, for your pipeline ...
- In Encryption key, do one of the following: To use the CodePipeline default AWS KMS key to encrypt the data in the pipeline artifact store (S3 bucket), choose Default AWS ...
- Step 1: Create a deployment environment. ...
- Step 2: Get a copy of the sample code. ...
- Step 3: Create your pipeline. ...
- Step 4: Activate your pipeline to deploy your code. ...
- Step 5: Commit a change and then update your app. ...
- Step 6: Clean up your resources.
How do I create an AWS CodePipeline?
You can use the AWS CodePipeline console or the AWS CLI to create a pipeline. Pipelines must have at least two stages. The first stage of a pipeline must be a source stage. The pipeline must have at least one other stage that is a build or deployment stage.
How do I create a CodePipeline pipeline?
For more information about the Regions and endpoints available for CodePipeline, see AWS CodePipeline endpoints and quotas. On the Welcome page, Getting started page, or the Pipelines page, choose Create pipeline. On the Step 1: Choose pipeline settings page, in Pipeline name, enter the name for your pipeline.
How do I change the name of my AWS pipeline?
On the Step 1: Choose pipeline settings page, in Pipeline name, enter the name for your pipeline. In a single AWS account, each pipeline you create in an AWS Region must have a unique name. Names can be reused for pipelines in different Regions. After you create a pipeline, you cannot change its name.
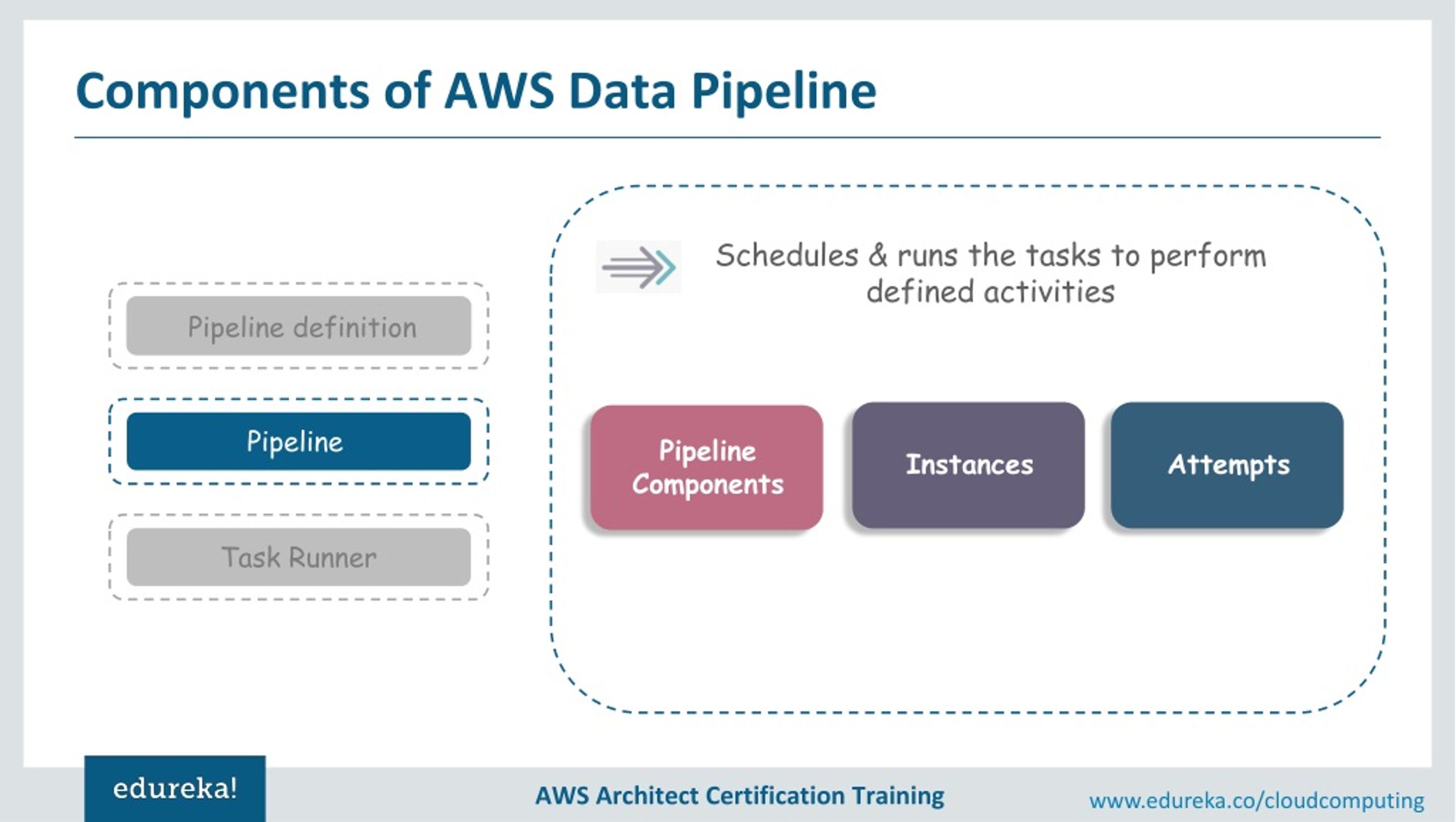
What is big data pipeline in AWS?
Big Data Blog. AWS Data Pipeline is a web service that helps you reliably process and move data between different AWS compute and storage services, as well as on-premises data sources, at specified intervals.
How do you create pipeline?
Go to the Pipelines tab, and then select Releases. Select the action to create a New pipeline. If a release pipeline is already created, select the plus sign ( + ) and then select Create a release pipeline. Select the action to start with an Empty job.
What is pipeline in AWS?
AWS Data Pipeline is a web service that helps you reliably process and move data between different AWS compute and storage services, as well as on-premises data sources, at specified intervals.
How do I start AWS data pipeline?
Open the AWS Data Pipeline console at https://console.aws.amazon.com/datapipeline/ . The first screen that you see depends on whether you've created a pipeline in the current region. If you haven't created a pipeline in this region, the console displays an introductory screen. Choose Get started now.
Which steps do we need to complete before configure a pipeline in AWS?
Step 1: Create an AWS account. ... Step 2: Create or use an IAM user. ... Step 3: Use an IAM managed policy to assign CodePipeline permissions to the IAM user. ... Step 4: Install the AWS CLI. ... Step 5: Open the console for CodePipeline.
What is S3 pipeline?
The pipeline has two stages: A source stage named Source, which detects changes in the versioned sample application stored in the S3 bucket and pulls those changes into the pipeline. A Deploy stage that deploys those changes to EC2 instances with CodeDeploy.
How does AWS code pipeline work?
With AWS CodePipeline, you model the full release process for building your code, deploying to pre-production environments, testing your application and releasing it to production. AWS CodePipeline then builds, tests, and deploys your application according to the defined workflow every time there is a code change.
Is AWS data pipeline an ETL tool?
AWS Data Pipeline Product Details As a managed ETL (Extract-Transform-Load) service, AWS Data Pipeline allows you to define data movement and transformations across various AWS services, as well as for on-premises resources.
How do you run a data pipeline?
The quickest way to get started with AWS Data Pipeline is to use a pipeline definition called a template. Open the AWS Data Pipeline console at https://console.aws.amazon.com/datapipeline/ . From the navigation bar, select a region. You can select any region that's available to you, regardless of your location.
What is CI CD pipeline in AWS?
CI/CD can be pictured as a pipeline, where new code is submitted on one end, tested over a series of stages (source, build, test, staging, and production), and then published as production-ready code. CICD pipeline overview. Each stage of the CI/CD pipeline is structured as a logical unit in the delivery process.
How many stages can you have in a pipeline AWS?
A pipeline must contain at least two stages.
What are the stages in AWS code pipeline?
Valid CodePipeline action types are source , build , test , deploy , approval , and invoke .
What is the command to create a new pipeline?
The az pipelines command group allows you to create , delete , list , run , show and update a pipeline, enabling you to manage pipelines effectively from the command line.
What is a pipeline in cloud?
On any Software Engineering team, a pipeline is a set of automated processes that allow developers and DevOps professionals to reliably and efficiently compile, build, and deploy their code to their production compute platforms.
What a pipeline is?
Definition of pipeline 1a : a line of pipe with pumps, valves, and control devices for conveying liquids, gases, or finely divided solids. b : pipe sense 2b. 2 : a direct channel for information. 3 : a process or channel of supply an arms pipeline.
What is pipeline in DevOps?
A DevOps pipeline is a set of automated processes and tools that allows developers and operations professionals to collaborate on building and deploying code to a production environment.
What is the purpose of a data pipeline?
Data pipelines are used to perform data integration. Data integration is the process of bringing together data from multiple sources to provide a complete and accurate dataset for business intelligence (BI), data analysis and other applications and business processes.
Step 1: Create a deployment environment
Your continuous deployment pipeline will need a target environment containing virtual servers, or Amazon EC2 instances, where it will deploy sample code. You will prepare this environment before creating the pipeline.
Step 2: Get a copy of the sample code
In this step, you will retrieve a copy of the sample app’s code and choose a source to host the code. The pipeline takes code from the source and then performs actions on it.
Step 3: Create your pipeline
In this step, you will create and configure a simple pipeline with two actions: source and deploy. You will provide CodePipeline with the locations of your source repository and deployment environment.
Step 4: Activate your pipeline to deploy your code
In this step, you will launch your pipeline. Once your pipeline has been created, it will start to run automatically. First, it detects the sample app code in your source location, bundles up the files, and then move them to the second stage that you defined.
Step 5: Commit a change and then update your app
In this step, you will revise the sample code and commit the change to your repository. CodePipeline will detect your updated sample code and then automatically initiate deploying it to your EC2 instance via Elastic Beanstalk.
Step 6: Clean up your resources
To avoid future charges, you will delete all the resources you launched throughout this tutorial, which includes the pipeline, the Elastic Beanstalk application, and the source you set up to host the code.
Next Steps
Now that you have learned to create a simple pipeline using AWS CodePipeline, you can learn more by visiting the following resources.
Introduction: Create a Continuous Delivery Pipeline
Follow step-by-step instructions to build your first continuous delivery pipeline.
Overview
In this tutorial, you will create a continuous delivery pipeline for a simple web application. You will first use a version control system to store your source code. Then you will learn how to create a continuous delivery pipeline that will automatically deploy your web application whenever your source code is updated.
What You Will Learn
This tutorial will walk you through the steps to create the continuous delivery pipeline discussed above. You will learn to:
Application Architecture
The diagram below provides a visual representation of the services used in this tutorial and how they are connected. This application uses GitHub, AWS Elastic Beanstalk, AWS CodeBuild, and AWS CodePipeline as pictured below.
Modules
This tutorial is divided into five short modules. You must complete each module in order before moving on to the next one.
Step 1: Complete prerequisites
To integrate with Jenkins, AWS CodePipeline requires you to install the CodePipeline Plugin for Jenkins on any instance of Jenkins you want to use with CodePipeline. You should also configure a dedicated IAM user to use for permissions between your Jenkins project and CodePipeline.
Step 2: Create a pipeline in CodePipeline
In this part of the tutorial, you create the pipeline using the Create Pipeline wizard.
Step 3: Add another stage to your pipeline
Now you will add a test stage and then a test action to that stage that uses the Jenkins test included in the sample to determine whether the webpage has any content. This test is for demonstration purposes only.
Step 4: Clean up resources
After you complete this tutorial, you should delete the pipeline and the resources it uses so you will not be charged for continued use of those resources.
