Avro schema evolution is defined as the schema evolution that can acknowledge us to update the schema, and it can be used for writing new data while sustaining backward compatibility by utilizing the schema of our past data; when all data can have the same schema, then we can able to read data thoroughly.
Why choose Avro for schema evolution?
Importantly, Avro also offers the ability for customers to safely and confidently evolve their data model definitions. After all — we should expect the shape of data to change over time. However, in my experience, our customers often struggled to engage with Avro’s schema evolution strategies and rules.
What is an Avro?
The avro is the schema-based process that can be used for changing the data, the avro can gain schemas as inputs in which it cannot follows the obtainable schema it accompanied its own standards for substituting the schemas.
What are primitive types in Apache Avro schema?
Primitive types have no specified attributes. There are six kinds of complex types in Apache Avro Schema, such as: i. Avro Schema Records Basically, it uses the type name “record” and does support various attributes, such as: It is a JSON string which describes the name of the record (required).
What are the advantages of serialization in Avro?
By making serialization both fast and small, it allows each datum to be written with no-par-value overheads. Avro schema is stored with Avro data when it is stored in a file, hence that files may be later processed by any program. However, there could be an error occur, that the program reading the data expects a different schema.

Does Avro support schema evolution?
A common trait shared by these platforms is that they used Apache Avro to provide strong schema-on-write data contracts. Importantly, Avro also offers the ability for customers to safely and confidently evolve their data model definitions. After all — we should expect the shape of data to change over time.
How does Avro handle schema changes?
In Avro and Protobuf, you can define fields with default values. In that case, adding or removing a field with a default value is a fully compatible change. Compatibility rules for supported schema types are described in Compatibility Checks in Formats, Serializers, and Deserializers.
How does schema evolve?
Schema evolution is a feature that allows users to easily change a table's current schema to accommodate data that is changing over time. Most commonly, it's used when performing an append or overwrite operation, to automatically adapt the schema to include one or more new columns.
How does Avro schema work?
Avro Schemas It allows every data to be written with no prior knowledge of the schema. It serializes fast and the resulting serialized data is lesser in size. Schema is stored along with the Avro data in a file for any further processing. In RPC, the client and the server exchange schemas during the connection.
What is schema evolution in Kafka?
Schema evolution is the term used for how the store behaves when Avro schema is changed after data has been written to the store using an older version of that schema.
What is schema evolution in spark?
Schema evolution allows users to easily change the current schema of a Hudi table to adapt to the data that is changing over time. As of 0.11. 0 release, Spark SQL (Spark 3.1. x, 3.2. 1 and above) DDL support for Schema evolution has been added and is experimental.
What is schema evolution in big data?
Definition. Schema evolution deals with the need to retain current data when database schema changes are performed.
Is Avro schema backward compatible?
Backward Compatibility To support this kind of use case, we can evolve the schemas in a backward compatible way: data encoded with the old schema can be read with the newer schema. Avro has a set of rules on what changes are allowed in the new schema for it to be backward compatible.
How is Avro different from JSON?
It is based on a subset of the JavaScript Programming Language. Avro can be classified as a tool in the "Serialization Frameworks" category, while JSON is grouped under "Languages". Redsift, OTTLabs, and Mon Style are some of the popular companies that use JSON, whereas Avro is used by Liferay, LendUp, and BetterCloud.
Why Avro schema is used with Kafka plug in?
We think Avro is the best choice for a number of reasons: It has a direct mapping to and from JSON. It has a very compact format. The bulk of JSON, repeating every field name with every single record, is what makes JSON inefficient for high-volume usage.
What is the difference between Avro schema and JSON schema?
JSON Schema can describe a much broader set of data than Avro (Avro can only have strings in enums, for instance, while enums in JSON Schema can have any JSON value); but Avro has notions which are not available in JSON (property order in records, binary types).
How do I convert Avro schema to JSON?
1 AnswerDownload: avro-tools-1.7.4.jar (or latest version from repository)Run: java -jar avro-tools-1.7.4.jar tojson avro-filename.avro>output-filename.json.
How do you handle schema evolution in hive?
How to Handle Schema Changes/Evolutes in Hive ORC tables like Column Deletions happening at Source DB.Before Schema Changes: ... #Insert some Data into it. ... #Create a New HDFS directory to store New Schema Changed data. ... #Similarly create a new directory. ... #Sqoop the Firstime Load as below.More items...•
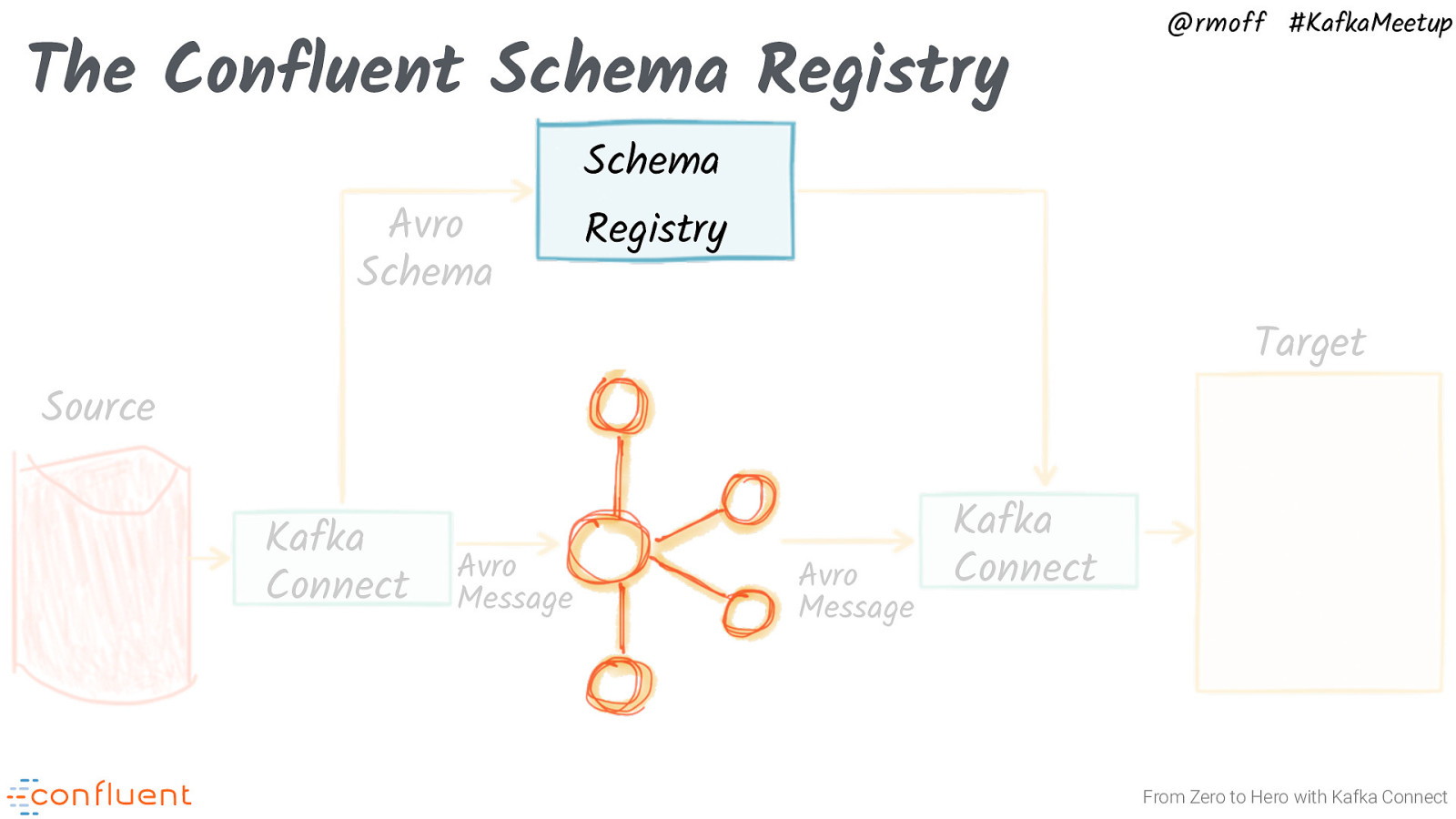
How does schema registry work in Kafka?
Schema Registry lives outside of and separately from your Kafka brokers. Your producers and consumers still talk to Kafka to publish and read data (messages) to topics. Concurrently, they can also talk to Schema Registry to send and retrieve schemas that describe the data models for the messages.
Does parquet support schema evolution?
Like Protocol Buffer, Avro, and Thrift, Parquet also supports schema evolution. Users can start with a simple schema, and gradually add more columns to the schema as needed. In this way, users may end up with multiple Parquet files with different but mutually compatible schemas.
How is Avro different from JSON?
It is based on a subset of the JavaScript Programming Language. Avro can be classified as a tool in the "Serialization Frameworks" category, while JSON is grouped under "Languages". Redsift, OTTLabs, and Mon Style are some of the popular companies that use JSON, whereas Avro is used by Liferay, LendUp, and BetterCloud.
Why is schema evolution important?
When this happens, it’s critical for the downstream consumers to be able to handle data encoded with both the old and the new schema seamlessly. This is an area that tends to be overlooked in practice until you run into your first production issues. Without thinking through data management and schema evolution carefully, people often pay a much higher cost later on.
How does schema compatibility check work?
Confluent Schema Registry is built for exactly that purpose. Schema compatibility checking is implemented in Schema Registry by versioning every single schema. The compatibility type determines how Schema Registry compares the new schema with previous versions of a schema, for a given subject. When a schema is first created for a subject, it gets a unique id and it gets a version number, i.e., version 1. When the schema is updated (if it passes compatibility checks), it gets a new unique id and it gets an incremented version number, i.e., version 2.
What is full compatibility in a schema?
For example, if there are three schemas for a subject that change in order X-2, X-1, and X then FULL compatibility ensures that consumers using the new schema X can process data written by producers using schema X or X-1, but not necessarily X-2 , and that data written by producers using the new schema X can be processed by consumers using schema X or X-1, but not necessarily X-2 . If the new schema needs to be forward and backward compatible with all registered schemas, not just the last two schemas, then use FULL_TRANSITIVE instead of FULL . For example, if there are three schemas for a subject that change in order X-2, X-1, and X then FULL_TRANSITIVE compatibility ensures that consumers using the new schema X can process data written by producers using schema X, X-1, or X-2, and that data written by producers using the new schema X can be processed by consumers using schema X, X-1, or X-2.
Which schema can be read by consumers?
FORWARD_TRANSITIVE: data produced using schema X can be read by consumers with schema X, X-1, or X-2
Can you add a default value in Avro?
In Avro and Protobuf, you can define fields with default values. In that case, adding or removing a field with a default value is a fully compatible change.
Can consumers read older schemas?
FORWARD or FORWARD_TRANSITIVE: there is no assurance that consumers using the new schema can read data produced using older schemas. Therefore, first upgrade all producers to using the new schema and make sure the data already produced using the older schemas are not available to consumers, then upgrade the consumers.
How does Avro support schema evolution?
You can actually give two different schemas to the Avro parser, and it uses resolution rules to translate data from the writer schema into the reader schema.
How to leave out a value in Avro?
Instead, if you want to be able to leave out a value, you can use a union type, like union { null, long } above. This is encoded as a byte to tell the parser which of the possible union types to use, followed by the value itself. By making a union with the null type (which is simply encoded as zero bytes) you can make a field optional.
What are the options for the fourth stage of Java?
Once you get to the fourth stage, your options are typically Thrift , Protocol Buffers or Avro. All three provide efficient, cross-language serialization of data using a schema, and code generation for the Java folks.
How to add field in protobuf?
You can add a field to your record, as long as it is given a new tag number. If the Protobuf parser parser sees a tag number that is not defined in its version of the schema, it has no way of knowing what that field is called. But it does roughly know what type it is, because a 3-bit type code is included in the first byte of the field. This means that even though the parser can’t exactly interpret the field, it can figure out how many bytes it needs to skip in order to find the next field in the record.
What is the difference between Avro and Protocol Buffers?
One way of looking at it: in Protocol Buffers, every field in a record is tagged, whereas in Avro, the entire record, file or network connection is tagged with a schema version.
Why are no tag numbers needed in Avro?
Because fields are matched by name, changing the name of a field is tricky.
Can you reuse a tag number in schema?
Thus, it is safe to remove that kind of field from the schema. However, you must never reuse the tag number for another field in future, because you may still have data stored that uses that tag for the field you deleted.
Evolving Schemas with Schema Registry
This article explores Schema Registry compatibility modes and how to evolve schemas according to them.
Transitive x Non-transitive compatibility modes
The Confluent Schema Registry compatibility modes are divided into two groups that you can choose when you set compatibility:
Schema compatibility tests
To test the schema compatibility, I will use these schemas. They were created as AVRO schemas and the code can be found here.
Final considerations
As shown in this article, the Schema Registry provides an automatic way of control changes in schemas, assuring compatibility and providing an organized way of evolving with less impact on downstream processes.
What is Avro Schema?
Basically, on schemas, only Avro relies on. The schema used, when Avro data is read, and when writing it is always present. By making serialization both fast and small, it allows each datum to be written with no-par-value overheads.
How is Avro schema stored?
Avro schema is stored with Avro data when it is stored in a file, hence that files may be later processed by any program. However, there could be an error occur, that the program reading the data expects a different schema. So, we can easily resolve because both schemas are present.
Why can we resolve Avro?
So, we can easily resolve because both schemas are present. The client and server in Avro exchange schemas in the connection handshake, while Avro is used in RPC. If somehow the client and the server both have the correspondence between same-named fields, other’s full schema, extra fields, missing fields, etc. we can easily resolve it.
What does it mean when two schemas do not match?
A. If the two schemas do not match, this is an error.
What is the schema used to write data?
Basically, the schema which we use to write the data is what we call the writer’s schema, or the schema what the application expects is the reader’s schema. So, the differences between both must be resolved as follows:
Does Avro accept JSON?
Due to this reason, in all the languages that already have JSON libraries, it facilitates implementation. However, Avro accepts schemas as input. Avro follows its own standards of defining schemas, instead of variously available schemas.
Do schemas have to match?
Moreover, both schemas which are present their sizes and names must match .
What is Avro serialization?
Avro, being a schema-based serialization utility, accepts schemas as input. In spite of various schemas being available, Avro follows its own standards of defining schemas. These schemas describe the following details −
What is an enumeration in Avro?
An enumeration is a list of items in a collection, Avro enumeration supports the following attributes −
What is a field in a JSON schema?
fields − This field holds a JSON array, which have the list of all of the fields in the schema, each having name and the type attributes.