
What are the functions of lexical analyzer?
- Lexical analyzer first read int and finds it to be valid and accepts as token
- max is read by it and found to be a valid function name after reading (
- int is also a token , then again i as another token and finally ;
What does 'lexical meaning' mean?
What does lexical mean? Of a vocabulary, or stock of words, as that of a language; specif., of words as isolated items of vocabulary rather than...
What does lexical approach mean?
The lexical approach is a way of analysing and teaching language based on the idea that it is made up of lexical units rather than grammatical structures. The units are words, chunks formed by collocations, and fixed phrases. The phrase 'Rescue attempts are being hampered by bad weather' is a chunk of language, and almost a fixed phrase.
What is the role lexical analyzer?
As the first phase of a compiler, the main task of the lexical analyzer is to read the input characters of the source program, group them into lexemes, and produce as output a sequence of tokens for each lexeme in the source program. The stream of tokens is sent to the parser for syntax analysis.
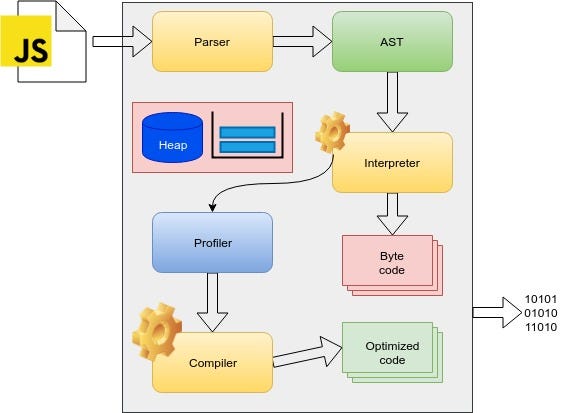
How do you explain lexical analysis?
Essentially, lexical analysis means grouping a stream of letters or sounds into sets of units that represent meaningful syntax. In linguistics, it is called parsing, and in computer science, it can be called parsing or tokenizing.
How does lexical analysis and syntax analysis work?
From source code, lexical analysis produces tokens, the words in a language, which are then parsed to produce a syntax tree, which checks that tokens conform with the rules of a language. Semantic analysis is then performed on the syntax tree to produce an annotated tree.
How does lexical analysis detect errors?
A lexer contains tokenizer or scanner. If the lexical analyzer detects that the token is invalid, it generates an error. The role of Lexical Analyzer in compiler design is to read character streams from the source code, check for legal tokens, and pass the data to the syntax analyzer when it demands.
Why do we use lexical analysis?
The lexical analysis is the first phase of the compiler where a lexical analyser operate as an interface between the source code and the rest of the phases of a compiler. It reads the input characters of the source program, groups them into lexemes, and produces a sequence of tokens for each lexeme.
Which compiler is used for lexical analysis?
JavaCC is the standard Java compiler-compiler. Unlike the other tools presented in this chapter, JavaCC is a parser and a scanner (lexer) generator in one. JavaCC takes just one input file (called the grammar file), which is then used to create both classes for lexical analysis, as well as for the parser.
What is lexical analysis in linguistics?
Lexical analysis is a process by which meanings are associated with specific words or other textual strings. These strings, which can be referred to as lexical terms, or just terms, are typically extracted during the scanning of some document.
What is lexical analysis explain with example?
Lexical Analysis is the first phase of the compiler also known as a scanner. It converts the High level input program into a sequence of Tokens. Lexical Analysis can be implemented with the Deterministic finite Automata. The output is a sequence of tokens that is sent to the parser for syntax analysis.
What is the output of lexical analysis?
What is the output of lexical analyzer? Explanation: A lexical analyzer coverts character sequences to set of tokens.
What are the lexical errors explain with one example?
A lexical error is any input that can be rejected by the lexer. This generally results from token recognition falling off the end of the rules you've defined. For example (in no particular syntax): [0-9]+ ===> NUMBER token [a-zA-Z] ===> LETTERS token anything else ===> error!
What are the two processes of lexical analyzer?
Lexing can be divided into two stages: the scanning, which segments the input string into syntactic units called lexemes and categorizes these into token classes; and the evaluating, which converts lexemes into processed values.
What is pattern in lexical analysis?
Pattern: Notation used to identify the set of lexemes represented by a token. e.g., [0 − 9]+ Compilers. Lexical Analysis. CSE 304/504.
What is the difference between lexical analysis and parsing?
Lexical analysis reads the source program one character at a time and converts it into meaningful lexemes (tokens) whereas syntax analysis takes the tokens as input and generates a parse tree as output. Thus, this is the main difference between lexical analysis and syntax analysis.
How lexical analysis is different from syntax analysis?
A lexical analyser is a pattern matcher. A syntax analysis involves forming a tree to identify deformities in the syntax of the program. Less complex approaches are often used for lexical analysis.
What is the difference between lexical analysis and syntax analysis?
Lexical analysis is the process of converting a sequence of characters into a sequence of tokens while syntax analysis is the process of analyzing a string of symbols either in natural language, computer languages or data structures conforming to the rules of a formal grammar.
Why lexical analysis and syntax analysis phases are separated?
Separation allows the simplification of one or the other. 2) Compiler efficiency is improved. Optimization of lexical analysis because a large amount of time is spent reading the source program and partitioning it into tokens. 3) Compiler portability is enhanced.
What is lexical and syntactic structure of a language?
Syntactic structure is defined by: An alphabet (what are legal characters) Lexical structure: formation of strings of legal characters into lexical units (legal tokens) Parse structure: formation of sequences of legal tokens into grammatical units (legal constructs)
What is Lexical Analysis?
Lexical analysis is the starting phase of the compiler. It gathers modified source code that is written in the form of sentences from the language preprocessor. The lexical analyzer is responsible for breaking these syntaxes into a series of tokens, by removing whitespace in the source code.
Terminologies
Token: It is a sequence of characters that represents a unit of information in the source code.
The Architecture of Lexical Analyzer
To read the input character in the source code and produce a token is the most important task of a lexical analyzer. The lexical analyzer goes through with the entire source code and identifies each token one by one. The scanner is responsible to produce tokens when it is requested by the parser.
What is the output of lexical phase?
The output of the lexical phase is a stream of tokens corresponding to the words described above. In addition, this phase builds tables which are used by subsequent phases of the compiler. One such table, called the symbol table, stores all identifiers used in the source program, including relevant information and attributes of the identifiers. In block-structured languages it may be preferable to construct the symbol table during the syntax analysis phase because program blocks (and identifier scopes) may be nested.
What is the first phase of a compiler?
The first phase of a compiler is called lexical analysis (and is also known as a lexical scanner ). As implied by its name, lexical analysis attempts to isolate the “words” in an input string. We use the word “word” in a technical sense. A word, also known as a lexeme, a lexical item, or a lexical token, is a string of input characters which is taken as a unit and passed on to the next phase of compilation. Examples of words are
What is a lex utility?
The lex utility generates a C program that is a lexical analyzer, a program that performs lexical processing of its character input. The source code for a lex program is a table of regular expressions coupled with corresponding actions, which are expressed as C code fragments. So, for example, if an identifier is found in the program, then the action corresponding to the identifier is taken. Perhaps some information would be added to the symbol table in this case. If a keyword such as if is recognized, a different action would be taken.
What is the purpose of lex?
The first step of compilation, called lexical analysis, is to convert the input from a simple sequence of characters into a list of tokens of different kinds, such as numerical and string constants, variable identifiers, and programming language keywords. The purpose of lex is to generate lexical analyzers.
What is ad hoc in parsing?
The ad hoc technique, syntax-directed translation, integrates arbitrary snippets of code into the parser and lets the parser sequence the actions and pass values between them . This approach has been widely embraced because of its flexibility and its inclusion in most parser-generator systems. The ad hoc approach sidesteps the practical problems that arise from nonlocal attribute flow and from the need to manage attribute storage. Values flow in one direction alongside the parser's internal representation of its state (synthesized values for bottom-up parsers and inherited for top-down parsers). These schemes use global data structures to pass information in the other direction and to handle nonlocal attribute flow.
What is a regular expression?
Regular expressions can be used to specify exactly what values are legal for the tokens to assume. Some tokens are simply keywords, like if, else, and for. Others, like identifiers, can be any sequence of letters and digits provided that they do not match a keyword and do not start with a digit. Typically, an identifier is a variable name such as current, flag2, or windowStatus. In general, an identifier is a letter followed by any combination of digits and letters.
What is a lexical token?
A word, also known as a lexeme, a lexical item, or a lexical token, is a string of input characters which is taken as a unit and passed on to the next phase of compilation. Examples of words are. 1. key words — while, void, if, for, …. 2. identifiers —declared by the programmer. 3. operators —+, −, *, /, =,= = ,…. 4.
What is symbolic supervisor in Java?
In JavaCC’s wording the scanner/lexical analyzer is known as the symbolic supervisor. What’s more, in actuality the created class that contains the symbolic administrator is called Parser Name Token Manager. Obviously, following the typical Java record name prerequisites, the class is put away in a document called ParserNameTokenManager.java. The Parser Name part is taken from the info record. What’s more, JavaCC makes a second class, called Parser Name Constants. That second class, as the name infers, contains meanings of constants, particularly token constants. JavaCC additionally creates a standard class called Token. That one is consistently the equivalent, and contains the class used to speak to tokens. One likewise gets a class called Parse Error. This is a special case which is tossed if something turned out badly.
What is the purpose of lexical analyzer?
First in a compiler, the fundamental undertaking of the lexical analyzer is to peruse the info nature of the source code, bunch them into lexemes, and build an arrangement of tokens for every lexeme in the source program. the symbolic stream is sent to the parser for parsing. it is normal for the lexical analyzer to communicate with the image. at the point when the lexical analyzer finds a lexeme which comprises an identifier, it must embed this lexeme in the table of images.
What is a lexer in computer science?
In computer science, lexical investigation, lexing or tokenization is the way toward changing over a grouping of characters (as in a software engineer or a page) into an arrangement of tokens (strings with an appointed significance and thus distinguished). a developer that performs lexical investigation might be known as a lexer, tokenizer, or scanner, despite the fact that scanner is likewise a term for the initial step of a lexer.
What is JavaCC?
JavaCC is the standard Java compiler-compiler. Dissimilar to different devices introduced in this part, JavaCC is a parser and a scanner (lexer) generator in one. JavaCC takes only one information record (called the syntax document), which is then used to make the two classes for lexical examination, just as for the parser.
What is lexical analysis?
Lexical examination is the initial stage in planning the compiler. A lexeme is a grouping of characters remembered for the source software engineer as per the coordinating example of symbol. The lexical analysis is executed to examine all the source code of the developer.
What is expected to create and focus the lexer and its symbolic depictions?
More exertion is expected to create and focus the lexer and its symbolic depictions
What is the straight forwardness of plan?
The straight forwardness of plan: It encourages the pattern of lexical assessment and the sentence structure examination by murdering bothersome symbols.
What is Lexical Analysis?
Lexical Analysis is the very first phase in the compiler designing. A Lexer takes the modified source code which is written in the form of sentences . In other words, it helps you to convert a sequence of characters into a sequence of tokens. The lexical analyzer breaks this syntax into a series of tokens. It removes any extra space or comment written in the source code.
What are the drawbacks of using a Lexical Analyzer?
The biggest drawback of using Lexical analyzer is that it needs additional runtime overhead is required to generate the lexer tables and construct the tokens
What is the Lexical Analyzer method?
Lexical analyzer method is used by programs like compilers which can use the parsed data from a programmer's code to create a compiled binary executable code. It is used by web browsers to format and display a web page with the help of parsed data from JavsScript, HTML, CSS.
What is simplicity of design?
The simplicity of design: It eases the process of lexical analysis and the syntax analysis by eliminating unwanted tokens
What does lexical analyzer do on receiving command?
On receiving this command, the lexical analyzer scans the input until it finds the next token.
Why do we need a separate lexical analyzer?
A separate lexical analyzer helps you to construct a specialized and potentially more efficient processor for the task
What is a character sequence that is not possible to scan into any valid token?
A character sequence which is not possible to scan into any valid token is a lexical error. Important facts about the lexical error :
What is a lexer in a compiler?
A lexer forms the first phase of a compiler frontend in modern processing. Analysis generally occurs in one pass. In older languages such as ALGOL, the initial stage was instead line reconstruction, which performed unstropping and removed whitespace and comments (and had scannerless parsers, with no separate lexer).
How are lexers generated?
Lexers are often generated by a lexer generator, analogous to parser generators, and such tools often come together. The most established is lex, paired with the yacc parser generator, or rather some of their many reimplementations, like flex (often paired with GNU Bison ). These generators are a form of domain-specific language, taking in a lexical specification – generally regular expressions with some markup – and emitting a lexer.
What is a lexeme in a parser?
A lexeme, however, is only a string of characters known to be of a certain kind (e.g., a string literal, a sequence of letters). In order to construct a token, the lexical analyzer needs a second stage, the evaluator, which goes over the characters of the lexeme to produce a value. The lexeme's type combined with its value is what properly constitutes a token, which can be given to a parser. Some tokens such as parentheses do not really have values, and so the evaluator function for these can return nothing: only the type is needed. Similarly, sometimes evaluators can suppress a lexeme entirely, concealing it from the parser, which is useful for whitespace and comments. The evaluators for identifiers are usually simple (literally representing the identifier), but may include some unstropping. The evaluators for integer literals may pass the string on (deferring evaluation to the semantic analysis phase), or may perform evaluation themselves, which can be involved for different bases or floating point numbers. For a simple quoted string literal, the evaluator needs to remove only the quotes, but the evaluator for an escaped string literal incorporates a lexer, which unescapes the escape sequences.
Why is it important to use a lexer in semantic analysis?
When a token class represents more than one possible lexeme, the lexer often saves enough information to reproduce the original lexeme, so that it can be used in semantic analysis. The parser typically retrieves this information from the lexer and stores it in the abstract syntax tree. This is necessary in order to avoid information loss in the case where numbers may also be valid identifiers.
What are the two lexical categories?
Two important common lexical categories are white space and comments . These are also defined in the grammar and processed by the lexer, but may be discarded (not producing any tokens) and considered non-significant, at most separating two tokens (as in if x instead of ifx ). There are two important exceptions to this. First, in off-side rule languages that delimit blocks with indenting, initial whitespace is significant, as it determines block structure, and is generally handled at the lexer level; see phrase structure, below. Secondly, in some uses of lexers, comments and whitespace must be preserved – for examples, a prettyprinter also needs to output the comments and some debugging tools may provide messages to the programmer showing the original source code. In the 1960s, notably for ALGOL, whitespace and comments were eliminated as part of the line reconstruction phase (the initial phase of the compiler frontend ), but this separate phase has been eliminated and these are now handled by the lexer.
How to use off side rule in Python?
The off-side rule (blocks determined by indenting) can be implemented in the lexer, as in Python, where increasing the indenting results in the lexer emitting an INDENT token, and decreasing the indenting results in the lexer emitting a DEDENT token. These tokens correspond to the opening brace { and closing brace } in languages that use braces for blocks, and means that the phrase grammar does not depend on whether braces or indenting are used. This requires that the lexer hold state, namely the current indent level, and thus can detect changes in indenting when this changes, and thus the lexical grammar is not context-free: INDENT–DEDENT depend on the contextual information of prior indent level.
What is lexical analysis?
In computer science, lexical analysis, lexing or tokenization is the process of converting a sequence of characters (such as in a computer program or web page) into a sequence of tokens ( strings with an assigned and thus identified meaning). A program that performs lexical analysis may be termed a lexer, tokenizer, or scanner, ...
What is Lexical Analysis?from guru99.com
Lexical Analysis is the very first phase in the compiler designing. A Lexer takes the modified source code which is written in the form of sentences . In other words, it helps you to convert a sequence of characters into a sequence of tokens. The lexical analyzer breaks this syntax into a series of tokens. It removes any extra space or comment written in the source code.
What is the Lexical Analyzer method?from guru99.com
Lexical analyzer method is used by programs like compilers which can use the parsed data from a programmer's code to create a compiled binary executable code. It is used by web browsers to format and display a web page with the help of parsed data from JavsScript, HTML, CSS.
What is simplicity of design?from guru99.com
The simplicity of design: It eases the process of lexical analysis and the syntax analysis by eliminating unwanted tokens
What happens if a lexical analyzer finds a token invalid?from tutorialspoint.com
If the lexical analyzer finds a token invalid, it generates an error. The lexical analyzer works closely with the syntax analyzer. It reads character streams from the source code, checks for legal tokens, and passes the data to the syntax analyzer when it demands.
What is the problem with lexical analyzer?from tutorialspoint.com
The only problem left with the lexical analyzer is how to verify the validity of a regular expression used in specifying the patterns of keywords of a language. A well-accepted solution is to use finite automata for verification.
What does lexical analyzer do on receiving command?from guru99.com
On receiving this command, the lexical analyzer scans the input until it finds the next token.
What is the language defined by regular expressions?from tutorialspoint.com
Regular expressions have the capability to express finite languages by defining a pattern for finite strings of symbols. The grammar defined by regular expressions is known as regular grammar. The language defined by regular grammar is known as regular language.
Do you want to learn more?
I’m in the process of writing the second part that explores a theory behind context-free grammar, AST construction and parser implementation algorithms. This second part will show how TypeScript parser is implemented and what algorithms it uses. Follow me to get notified whenever the article is ready.
What is DFA scanner?
The DFA can be implemented as a table-driven or hand-coded scanner. Table-driven scanners are usually generated by some specialized tools like Flex. Because with DFA each input uniquely determines the state to navigate to and it never backtracks the DFA is the preferred model for the implementation in generated scanners. The usual flow consists of converting a lexical specification (either regular grammar or regular expression) into NFA and then NFA is converted into DFA. Here is the picture that demonstrates the workflow:
What is ECMAScript grammar?
ECMAScript defines the rules for recognizing an input of Unicode symbols as tokens using regular grammar. According to the Chomsky classification of grammars regular grammar is the most restrictive type with the least expressiveness power. It’s only suitable to describing how the tokens can be constructed but can’t be used to describe sentence structure. However, more restrictions on the grammar make it easier to describe and parse. And since we’re concerned with defining and parsing tokens in this chapter this is the ideal grammar to use.
What is lexical analysis?
Lexical analysis is the first stage of a three-part process that the compiler uses to understand the input program. The role of the lexical analysis is to split program source code into substrings called tokens and classify each token to their role (token class). The program that performs the analysis is called scanner or lexical analyzer. It reads a stream of characters and combines them into tokens using rules defined by the lexical grammar, which is also referred to as lexical specification. If there are no rules that define a particular sequence of characters the scanner reports an error. This is exactly what happened with our example string d that produced Invalid or unexpected token syntax error.
What is a formal language?
Formal languages, on the hand, are languages that are designed by people for specific applications — programming languages to express computations, mathematical notation to denote relationships among numbers etc.
What is a compiler?
Compilers are computer programs that translate a program written in one language into a program in another language. A compiler must first understand the source-language program that it takes as input and then map its functionality to the target-language program. Because of the distinct nature of these two tasks it makes sense to split compiler functionality into two major blocks: a front-end and a back-end. The main focus of the former is to understand the source-language program, while the latter focuses on transforming it into the target-language program.
Why is white space important in grammar?
For some parts of the grammar white-space plays an important role that helps scanner distinguish one token from another. Let’s take a look at the following code and the resulting tokens:
Pre-requisites
For one to follow up with the article, the following knowledge is required:
What is Lexical analysis?
Lexical analysis is the first phase of the compiler, also known as a scanner. It is the process of converting a high-level source code into a series of tokens that the compiler can easily recognize.
A token count based on a sample code
This Java code prints a ‘Hello World’ message when running the code below:
Set up the tools
This section will feature the installation of the lexical analysis tools discussed above.
Create a Lex file and run it
Let us create a Lex analyzer that counts the number of words in a file and their total size.
A Lex analyzer that converts instances of certain characters into a particular pattern
Let us create a lex analyzer that changes ‘abc’ occurrences in the input to ‘ABC’. Create a file named strings.l. In it, add the following in the definitions section:
A lex analyzer that identifies certain words
This lex analyzer will identify words among a pre-defined set. It then returns an output if it is among the Set or not.

Introduction
- Lexical analysis is the starting phase of the compiler. It gathers modified source code that is written in the form of sentences from the language preprocessor. The lexical analyzer is responsible for breaking these syntaxes into a series of tokens, by removing whitespace in the source code. If the lexical analyzer gets any invalid token, it genera...
Basic Terminologies For Lexical Analyzer
Comparison of Lexical Analyzer & Parser
Role of Lexical Analyzer
Output of Lexical Analysis
- Lexeme Lexeme is a succession of nature remembered for the source developer as indicated by the coordinating example of a token. it is simply a symbolic occurrence. Token Symbol is a succession of nature that speaks to a part of data in the origin software engineering. Pattern Format is a portrayal utilized by the token. On account of a catchphrase utilized as a symbol, th…
Facts
- Lexical and Parser Separation
1. The straight forwardness of plan: It encourages the pattern of lexical assessment and the sentence structure examination by murdering bothersome symbols. 2. For better compiler adequacy: Helps you to better compiler order. 3. Explicit procedures can be applying to better th…
Cannot Read A Characters Twice
- Essential job: Scan a source program (a string) and split it up into little, significant units, called tokens. Model: position: =initial rate*60; Change into important units: identifiers, constants, administrators, and accentuation. Different jobs: 1. Removal of comments 2. Case of conversion 3. Removal of white spaces First in a compiler, the funda...
Compiler Design
- To Understand the Output of Lexical Analysis, we discuss an example: Here is a program Int maximum (Int a, Int b) { if (a > b) return a; else { return b; } } The output generated by the lexical analyzer To Understand the Output of Lexical Analysis, we discuss another example: Int main () { Int a = 10; if (a < 2) { printf (“a is less than 2”); } else { printf (“a is not less than 2”); } printf (“value …
Why Is It Important to Learn?
- There are some acceptable impacts of the lexical examination 1. The lexical analyzer technique is utilized by projects, for example, compilers that can utilize the information parsed by a software engineer’s code to make ordered pairs executable code. 2. Used by internet browsers to arrange and show a site page utilizing parsed JavaScript, HTML and CSS information. 3. A separate lexic…
Which Compiler Is Used For Lexical Analysis?
- A key objective in the plan of scanners ought to be to “limit the occasions The character is influenced by the program.” Although it appears to be entirely self-evident, it is regularly hacked while utilizing a scanner generator. The issue happens when RE don’t depict a solitary lexical token however a class of tokens. Consider what the numbers resemble: first, the entered charac…
Basic Terminologies
- A compiler deciphers code written in one language into another without altering the significance of the code. A compiler is additionally awaiting to make the objective code proficient and advanced as far as reality. The compiler plan standards give understanding into the interpretation and streamlining measure. The compiler venture covers the essential interpretation component …
Lexical Analyzer Architecture: How Tokens Are Recognized
- PCs are a reasonable blend of programming and apparatus. The apparatus is just a mechanical tool and its capacities are constrained by viable programming. We have discovered that each PC shell is composed of apparatus and programming. The material incorporates one language; that people can’t comprehend. That is the reason we compose programs in elevated level language t…
Roles of The Lexical Analyzer
- JavaCC is the standard Java compiler-compiler. Dissimilar to different devices introduced in this part, JavaCC is a parser and a scanner (lexer) generator in one. JavaCC takes only one information record (called the syntax document), which is then used to make the two classes for lexical examination, just as for the parser. In JavaCC’s wording the scanner/lexical analyzer is kn…
Lexical Errors
Error Recovery in Lexical Analyzer
Why Separate Lexical and Parser?
Advantages of Lexical Analysis
Disadvantage of Lexical Analysis
Summary