En este artículo te explicamos que es Big Data Hadoop, para que sirve, la importancia que tiene para las empresas y los desafíos que supone utilizarlo. ene 27, 2017 Hadoop es un framework opensource para almacenar datos y ejecutar aplicaciones en clusters de hardware básicos.
¿Cuáles son las ventajas de usar Hadoop?
Ventajas de utilizar Hadoop. Entre las ventajas de usar Hadoop señalar: –Los desarrolladores no tienen que enfrentar los problemas de la programación en paralelo. –Permite distribuir la información en múltiples nodos y ejecutar los procesos en paralelo. –Dispone de mecanismos para la monitorización de los datos.
¿Qué es la base de datos Hadoop y cómo funciona?
¿Qué es Hadoop? Hadoop es framework de código abierto con el que se pueden almacenar y procesar cualquier tipo de datos masivos. Tiene la capacidad de operar tareas de forma casi ilimitada con un gran poder de procesamiento y obtener respuestas rápidas a cualquier tipo de consulta sobre los datos almacenados.
¿Qué es Apache Hadoop y para qué sirve?
¿Sabes qué es Apache Hadoop y para qué sirve? En UNIR te damos las claves de uno de los frameworks más importantes para el Big Data. Hadoop nace como iniciativa de Apache para dar soporte al paradigma de programación Map-Reduce, que fue inicialmente publicado por Google.
¿Qué es big data Hadoop y para qué sirve?
En este artículo te explicamos que es Big Data Hadoop, para que sirve, la importancia que tiene para las empresas y los desafíos que supone utilizarlo. Hadoop es un framework opensource para almacenar datos y ejecutar aplicaciones en clusters de hardware básicos.
¿Qué es y cómo funciona Hadoop?
Hadoop es una estructura de software de código abierto para almacenar datos y ejecutar aplicaciones en clústeres de hardware comercial. Proporciona almacenamiento masivo para cualquier tipo de datos, enorme poder de procesamiento y la capacidad de procesar tareas o trabajos concurrentes virtualmente ilimitados.
¿Qué beneficios tiene Hadoop?
Ventajas de utilizar Hadoop –Los desarrolladores no tienen que enfrentar los problemas de la programación en paralelo. –Permite distribuir la información en múltiples nodos y ejecutar los procesos en paralelo. –Dispone de mecanismos para la monitorización de los datos. –Permite la realización de consultas de datos.
¿Cuándo es recomendable usar Hadoop?
Hadoop es la herramienta más eficiente para analizar Big Data: eficaz y a un bajo coste. Hadoop permite sacar partido a información desestructurada que teníamos guardada en repositorios sin utilizar. Hadoop facilita extraer valor de los grandes datos en tiempo real.
¿Qué es Hadoop ejemplos?
Hadoop es una plataforma de cambio de juego que puede combinar tanto el almacenamiento histórico y el flujo de datos en tiempo real para permitir a las organizaciones localizar y personalizar sus promociones.
¿Qué beneficios existen en la arquitectura de implementar HDFS?
Gracias a su estructura distribuida HDFS (Hadoop Data File System) es capaz de almacenarlos y tratarlos de un modo eficiente, pudiendo procesar con rapidez ingentes cantidades de información, lo que convierte a este sistema de código abierto en una heramienta idónea para llevar a cabo análisis en clave de Big Data.
¿Cuáles son los componentes de Hadoop?
Veamos algunos de los componentes del ecosistema Hadoop.Eclipse. ... Sqoop. ... Flume. ... Hive. ... Pig: para trabajar con MapReduce, es necesario programar, tener sólidos conocimientos de Java, saber cómo funciona MapReduce, conocer el problema a resolver, escribir, probar y mantener el código, etc. ... Hbase. ... Oozie. ... Zookeeper.More items...•
¿Dónde se usa Hadoop?
Hadoop es frecuentemente utilizado como almacén de datos para millones o miles de millones de transacciones. Las capacidades masivas de almacenamiento y procesamiento también te permiten usar Hadoop como una sandbox de descubrimiento y definición de patrones para ser monitorizados para instrucciones prescriptivas.
¿Qué es Hadoop y cómo puede revolucionar el sector bancario?
Detección de fraude: Hadoop permite analizar puntos de venta, autorizaciones y transacciones, logrando identificar y mitigar el fraude. Big Data, a su vez, facilita la tarea de detectar patrones de comportamiento inusuales y alertar a los bancos de los mismos, llegando a hacerlo incluso en tiempo real.
¿Qué es la arquitectura Hadoop?
Hadoop es una infraestructura de código abierto que reúne todos los componentes necesarios para almacenar y analizar grandes cantidades de datos. Se trata de una arquitectura de bibliotecas de software versátil y accesible.
¿Cómo funciona el MAP reduce?
Funcionamiento MapReduce Lector de Entrada: Divide la entrada en pequeños bloques de tamaño apropiado y asigna una división a cada función Map. Función Map: Toma una serie de pares clave/valor, los procesa y genera cero o más pares clave/valor de salida. Función de Partición: Obtiene un hash de la clave.
¿Qué es el Big Data?
Definición de big data Dicho de otro modo, el big data está formado por conjuntos de datos de mayor tamaño y más complejos, especialmente procedentes de nuevas fuentes de datos. Estos conjuntos de datos son tan voluminosos que el software de procesamiento de datos convencional sencillamente no puede gestionarlos.
¿Por que usar Apache Spark?
Apache Spark es un motor unificado de analíticas para procesar datos a gran escala que integra módulos para SQL, streaming, aprendizaje automático y procesamiento de grafos. Spark se puede ejecutar de forma independiente o en Apache Hadoop, Apache Mesos, Kubernetes, la nube y distintas fuentes de datos.
Escalabilidad
Hadoop permite escalar el sistema según crece el volumen de datos recibido, puesto que para procesar más datos, solo es necesario agregar más nodos a la estructura. Algo que, además, requiere poca administración.
Eficiencia
Gracias a su esquema de almacenamiento distribuido en nodos, donde cada nodo almacena un fragmento de la información, y la forma en que se estructura el tratamiento de los datos dentro de cada nodo, Hadoop ofrece un sistema altamente eficiente, con una gran capacidad de procesamiento y una alta velocidad.
Reducción de costes
Puesto que Hadoop es una licencia de software libre o código abierto, eso quiere decir que adquirirlo no tiene ningún coste. Además, funciona sobre hardaware convencional para almacenar y procesar los datos, por lo que el coste para su uso y mantenimiento no es elevado.
Flexibilidad
A diferencia de las bases de datos tradicionales, en Hadoop podemos crear los llamados lagos de datos (data lakes) sin necesidad de procesar los datos previamente, sean estos datos estructurados o no estructurados. Podemos almacenar tantos datos como queramos o necesitemos y más tarde decidir cómo se van a utilizar.
Gestión de errores
Sin duda, una de las ventajas de operar a través de diferentes nodos es que si uno falla, ni la estructura ni los datos se ven comprometidos, puesto sus tareas son pasan a otro de los nodos. Además, todos los datos son replicados de forma automática en varios nodos.
Características de Apache Hadoop

Otras Características de Hadoop Son
- –Tolerancia a fallos: al tratarse de una arquitectura distribuida entre una gran cantidad de nodos, se dispone de tolerancia a fallos en los mismos ya que, si falla alguno de ellos, sus tareas son traspasadas de manera transparente a otro de sus pares. Los datos son replicados automáticamente en múltiples máquinas. –Flexibilidad:los datos no son procesados previamen…
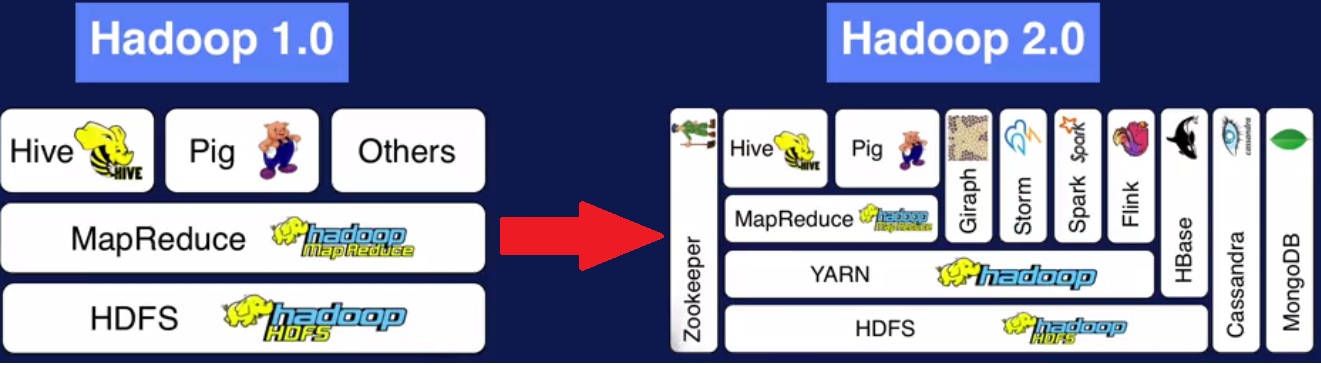
Componentes de Apache Hadoop
- Los componentes básicosde los que consta son: –Sistema de archivos distribuido HDFS: la información no se almacena en una única máquina, sino que se distribuye entre todas las máquinas que forman el clúster. –Framework MAP-REDUCE:se trata de un enfoque sistemático que utiliza el sistema de archivos distribuido HDFS para el procesamiento en paralelo de los dat…
Ventajas de utilizar Hadoop
- Entre las ventajas de usar Hadoop señalar: –Los desarrolladores no tienen que enfrentar los problemasde la programación en paralelo. –Permite distribuir la información en múltiples nodos y ejecutar los procesos en paralelo. –Dispone de mecanismos para la monitorización de los datos. –Permite la realización de consultas de datos. –Dispone de múltiples funcionalidadespara facili…
¿Cuáles Son Sus Características Básicas?
- Procesamiento distribuido.
- Eficiente.
- Económico.
- Fácilmente escalable.
¿Cuál Es Su Arquitectura Básica?
- En Hadoop se distinguen cuatro nodos principales: 1. Commom Utilities 2. YARN Framework 3. HDFS (Distributed Storage) 4. MapReduce (Distributed Computation) El Commom Utilitieslo forman todos los hardware y las librerías que son necesarias para ejecutar Hadoop. El YARN es el gestor de recursosde Hadoop. Ya que como hemos dicho Hadoop es un sistema distribuido e…
El Hadoop Cluster
- La configuración habitual de Hadoop es tenerlo en un cluster de máquinas. De manera que debemos tener una máquina “maestra” y “n” cantidad de máquinas “esclavas”. La idea principal es que la máquina maestra gestionará todas las tareas y las enviará a las máquinas “esclavas”. Esas máquinas realizarán todo el procesamiento de los datos y a continuación volverían a informara l…
¿Qué Opciones Tenemos para Trabajar Con Hadoop?
- Tenemos tres opciones: 1. Microsoft Azure. (Hadoop en Azure) Es un servicio que nos proporciona Microsoft que nos permite tener nuestras máquinas en la nube y solo pagaríamos por la cantidad de máquinas que tengamos y sus características.Click en su enlace: https://azure.microsoft.com/es-es/ 2. Hortonworks. Es la última distribución que ha salid…
¿Qué Es Hadoop?

Ventajas de Hadoop
- Las herramientas de Hadoop le dan una serie de ventajas que no está demás conocer, como la posibilidad de integrar otros sistemas con él, como por ejemplo el Big Data en Amazona través de los servicios de análisis de datos de AWS.
¿Qué Utilidades tiene Hadoop en El Big Data?
- La principal utilidad que tiene Hadoop en el Big Data, y para la que podemos encontrar más casos de uso, es la capacidad de llevar a cabo no solo el almacenamiento de los datos, sino el análisis avanzado de los mismos. Además, entre las utilidades de Hadood en el Big Data tenemos estos ejemplos: 1. Hadoop tiene herramientasque permiten realizar desarrollos en entornos de sandb…
¿Cuáles Son Los Desafíos de Usar Hadoop en La Gestión de datos?
- Aunque, como hemos visto, Hadoop para el Big Data cuenta con varias ventajas, eso no significa que no conlleve algunos handicaps, que encontramos en los desafíos que supone utilizarlo. Por un lado, MAP-REDUCE es una opción adecuada para solucionar solicitudes simples de información y problemas que se pueden dividir en unidades independientes, sin embargo, deja d…
Hadoop vs Spark ¿Cuál Es mejor?
- En esta entrada hemos hablado de Hadoop, pero existe actualmente otro framework (también de Apache), que se presenta como alternativa; hablamos de Spark, pero, ¿cuál es mejor para trabajar con Big Data? Al igual que Hadoop, Spark también es un software de código abierto, por lo que a nivel de coste, el gasto sería muy similar, sin embargo, Spark mejora lo que nos ofrece Hadoop …