
- Physically stored in order (ascending or descending)
- Only one per table
- When a primary key is created a clustered index is automatically created as well.
- If the table is under heavy data modifications or the primary key is used for searches, a clustered index on the primary key is recommended.
How do I create an index in Oracle?
15.1.2 Index Tuning using the SQLAccess Advisor. The SQLAccess Advisor is an alternative to manually determining which indexes are required. This advisor recommends a set of indexes when invoked from Oracle Enterprise Manager or run through the DBMS_ADVISOR package APIs. The SQLAccess Advisor either recommends using a workload or it generates a hypothetical …
What are the types of index in Oracle?
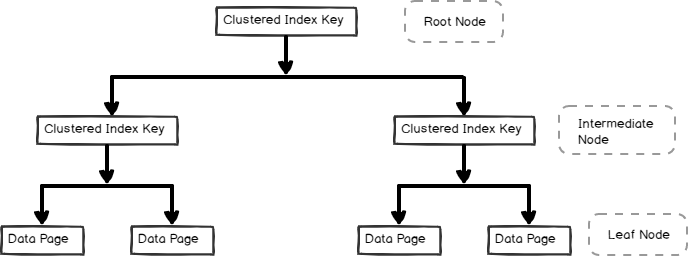
Apr 09, 2020 · What are clustered indexes in Oracle? A clustered index is a special type of index that reorders the way records in the table are physically stored. Therefore table can have only one clustered index. The leaf nodes of a clustered index contain the data pages. Click to see full answer. Also asked, how do clustered indexes work?
How to create index Oracle?
An alternative is to use an index organized table. Do not cluster tables if the data from all tables with the same cluster key value exceeds more than one or two Oracle blocks. To access a row in a clustered table, Oracle reads all blocks containing rows with that value.
How to create and use indexes in Oracle Database?
Oct 08, 2012 · A clustered index is a special type of index that reorders the way records in the table are physically stored. Therefore table can have only one clustered index. The leaf nodes of a clustered index contain the data pages.
What are clustered indexes?
Clustered indexes are indexes whose order of the rows in the data pages corresponds to the order of the rows in the index. This order is why only one clustered index can exist in any table, whereas, many non-clustered indexes can exist in the table.
What are clustered and non-clustered indexes in Oracle?
A Clustered index is a type of index in which table records are physically reordered to match the index. A Non-Clustered index is a special type of index in which logical order of index does not match physical stored order of the rows on disk.Oct 29, 2021
What is the purpose of the clustered index?
A clustered index defines the order in which data is physically stored in a table. Table data can be sorted in only way, therefore, there can be only one clustered index per table. In SQL Server, the primary key constraint automatically creates a clustered index on that particular column.Aug 28, 2017
What is the difference between clustered and non-clustered indexes?
Differences between Clustered Index and NonClustered Index You can sort the records and store clustered index physically in memory as per the order. A non-clustered index helps you to creates a logical order for data rows and uses pointers for physical data files.Feb 26, 2022
Is primary key clustered index?
A primary key is a unique index that is clustered by default. By default means that when you create a primary key, if the table is not clustered yet, the primary key will be created as a clustered unique index.Feb 24, 2013
What is clustered index in SQL with example?
Clustered. Clustered indexes sort and store the data rows in the table or view based on their key values. These are the columns included in the index definition. There can be only one clustered index per table, because the data rows themselves can be stored in only one order.Jan 28, 2022
How do you choose a clustered index?
What are the options for a clustered index?Option 1 – create an “id” column that is either an int or bigint and is also an “identity” ... Options 2 – Use a unique natural key made up of one or more columns. ... Option 3 – Use a non-unique natural key. ... Key width. ... Non-unique keys / uniqueifier's.More items...
Does clustered index need to be unique?
SQL Server does not require a clustered index to be unique, but yet it must have some means of uniquely identifying every row. That's why, for non-unique clustered indexes, SQL Server adds to every duplicate instance of a clustering key value a 4-byte integer value called a uniqueifier.Jan 6, 2011
Can clustered index be created on non primary key?
Can I create Clustered index without Primary key? Yes, you can create. The main criteria is that the column values should be unique and not null. Indexing improves the performance in case of huge data and has to be mandatory for quick retrieval of data.Oct 27, 2017
What is the main advantage of a clustered index over a non clustered index?
A clustered index specifies the physical storage order of the table data (this is why there can only be one clustered index per table). If there is no clustered index, inserts will typically be faster since the data doesn't have to be stored in a specific order but can just be appended at the end of the table.
Can clustered index have multiple columns?
Short: Although SQL Server allows us to add up to 16 columns to the clustered index key, with maximum key size of 900 bytes, the typical clustered index key is much smaller than what is allowed, with as few columns as possible.May 3, 2018
What are the differences between primary and clustered index?
If Primary Keys are good at uniquely identifying each row in a data table, Clustered Indexes are good at finding the specific rows quickly. A Clustered Index actually sorts the table using the values in the specified column.Jan 7, 2021
What is index in an application?
Indexes within an application sometimes have uses that are not immediately apparent from a survey of statement execution plans. An example of this is a foreign key index on a parent table, which prevents share locks from being taken out on a child table.
What is domain index?
Domain indexes are built using the indexing logic supplied by a user-defined indextype. An indextype provides an efficient mechanism to access data that satisfy certain operator predicates. Typically, the user-defined indextype is part of an Oracle option, like the Spatial option.
What is rowids in a bitmap?
The rowids used in bitmap indexes on index-organized tables are in a mapping table, not in the base table. The mapping table maintains a mapping of logical rowids (needed to access the index-organized table) to physical rowids (needed by the bitmap index code).
How many columns can a bitmap index do?
Bitmap indexes can be efficiently combined during query execution, so three small single-column bitmap indexes can do the job of six three-column B- tree indexes. Bitmap indexes are much more efficient than B-tree indexes, especially in data warehousing environments.
What is a bitmap join index?
A bitmap join index is a space-saving way to reduce the volume of data that must be joined, by performing restrictions in advance.
How to allow CBO to use index access path?
To allow the CBO the option of using an index access path, ensure that the statement contains a construct that makes such an access path available. Writing Statements That Avoid Using Indexes. In some cases, you might want to prevent a SQL statement from using an access path that uses an existing index.
Do you use B-tree indexes on a key?
Do not use standard B-tree indexes on keys or expressions with few distinct values. Such keys or expressions usually have poor selectivity and therefore do not optimize performance unless the frequently selected key values appear less frequently than the other key values.
What is cluster in Oracle?
First, you must understand what a cluster is in Oracle. A cluster is simply a method for storing more then 1 table on the same block. Normally -- a block contains data for exactly 1 table. In a cluster -- you have data from many tables sharing the same block. For example -- if you join the data from EMP and DEPT by DEPTNO frequently -- you might ...
Can you store data in a cluster?
absolutely NOT . with a cluster you can store data from more than one table on a single block (pre-joined). You cannot do that with partitioning. with a cluster you can make sure that every row that has a common key (like deptno, or empno in a history table) is stored right next to other rows with the same key.
Can a table have only one clustered index?
Therefore table can have only one clustered index. The leaf nodes of a clustered index contain the data pages. A nonclustered index is a special type of index in which the logical order of the index does not match the physical stored order of the rows on disk.
Why is the index only limited to one read operation per row?
Although the table access might become a bottleneck, it is still limited to one read operation per row because the index has the ROWID as a direct pointer to the table row. The database can immediately load the row from the heap table because the index has its exact position.
Why is clustering key longer than ROWID?
The clustering key is usually longer than a ROWID so that the secondary indexes are larger than they would be on a heap table, often eliminating the savings from the omission of the heap table. The strength of index-organized tables and clustered indexes is mostly limited to tables that do not need a second index.
What is secondary index?
Analogous to a regular index, a so-called secondary index refers to the original table data—which is stored in the clustered index. There, the data is not stored statically as in a heap table but can move at any time to maintain the index order. It is therefore not possible to store the physical location of the rows in ...
Does PostgreSQL use clustering?
The Oracle database always uses the primary key as the clustering key. PostgreSQL only uses heap tables. You can, however, use the CLUSTER clause to align the contents of the heap table with an index. By default SQL Server uses clustered indexes (index-organized tables) using the primary key as clustering key.
Can you use index only scans?
Tables with more indexes can often benefit from heap tables. You can still use index-only scans to avoid the table access. This gives you the select performance of a clustered index without slowing down other indexes.
Does DB2 have index organized tables?
DB2 doesn’t have index-organized tables but uses the term “clustered index“ for a different feature. It uses a heap table, but tries to insert new rows in the same block as nearby rows in the index. The MyISAM engine only uses heap tables while the InnoDB engine always uses clustered indexes.
Does a secondary index have a pointer?
A secondary index does not store a physical pointer ( ROWID) but only the key values of the clustered index—the so-called clustering key. Often that is the primary key of the index-organized table.
What is index in table?
An index in an ordinary table stores both the column data and the rowid. A row in an index-organized table does not have a stable physical location. It keeps data in sorted order, in the leaves of a B*-tree index built on the table's primary key. These rows can move around to preserve the sorted order.
How does a row in an ordinary table work?
A row in an ordinary table has a stable physical location. Once this location is established, the row never completely moves. Even if it is partially moved with the addition of new data, there is always a row piece at the original physical address--identified by the original physical rowid--from which the system can find the rest of the row. As long as the row exists, its physical rowid does not change. An index in an ordinary table stores both the column data and the rowid.
Is there an index organized table?
Yes there is. It is called "index organized table" (IOT) - which in my opinion is the better name as it makes it absolutely clear that the index and the table are the same physical thing (which is the reason why we can have only one clustered index in SQL Server) If yes, please let me know the SQL statement to create a cluster index.
Can you create a clustered index in Oracle?
If yes, please let me know the SQL statement to create a cluster index. There is no such thing as create clustered index in Oracle. To create an index organized table, you use the create table statement with the organization index option. In Oracle you usually use IOTs for very narrow tables.
How many clustered indexes are there in a database?
In the Database, there is only one clustered index per table. A clustered index defines the order in which data is stored in the table which can be sorted in only one way. So, there can be an only a single clustered index for every table.
What is cluster index?
Cluster index is a type of index that sorts the data rows in the table on their key values whereas the Non-clustered index stores the data at one location and indices at another location.
What are the pros and cons of clustered index?
The pros/benefits of the clustered index are: Clustered indexes are an ideal option for range or group by with max, min, count type queries. In this type of index, a search can go straight to a specific point in data so that you can keep reading sequentially from there.
What is index in SQL?
An Index is a key built from one or more columns in the database that speeds up fetching rows from the table or view. This key helps a Database like Oracle, SQL Server, MySQL, etc. to find the row associated with key values quickly. Two types of Indexes are: Clustered Index. Non-Clustered Index.
Why is a non clustering index important?
A non-clustering index helps you to retrieves data quickly from the database table. Helps you to avoid the overhead cost associated with the clustered index. A table may have multiple non-clustered indexes in RDBMS. So, it can be used to create more than one index.
Can a book have more than one index?
For example, a book can have more than one index, one at the beginning which displays the contents of a book unit wise while the second index shows the index of terms in alphabetical order. A non-clustering index is defined in the non-ordering field of the table. This type of indexing method helps you to improve the performance ...
What is cluster index?
"An indexed cluster is a table cluster that uses an index to locate data. The cluster index is a B-tree index on the cluster key. A cluster index must be created before any rows can be inserted into clustered tables.".
Can you have multiple tables in the same cluster?
So when you frequently query many rows with the same cluster key value, even from different tables, you only have to read a few data blocks, and there is a better chance of them being in the buffer cache. You can have multiple tables in the same cluster, and it is the cluster key index is used to identify the data block where those rows are located.
