
What are nodes in big data? A cluster is a collection of nodes. A node is a process running on a virtual or physical machine or in a container. When you run Hadoop in local node it writes data to the local file system instead of HDFS (Hadoop Distributed File System).
What are nodes and clusters in big data?
What are nodes in big data? A cluster is a collection of nodes. A node is a process running on a virtual or physical machine or in a container. When you run Hadoop in local node it writes data to the local file system instead of HDFS (Hadoop Distributed File System).
What is a node in data structure?
A node is a basic unit of a data structure, such as a linked list or tree data structure. Nodes contain data and also may link to other nodes. Links between nodes are often implemented by pointers.
What are some examples of nodes in a network?
Here are some examples of network nodes: In a computer network such as a local area network LAN or wide area network WAN, nodes may be personal computers as well as other pieces of data terminal equipment (DTE) and data communication equipment (DCE). This can include equipment such as modems, routers, servers and workstations.
What is a node in Hadoop?
A node in hadoop simply means a computer that can be used for processing and storing. There are two types of nodes in hadoop Name node and Data node. It is called as a node as all these computers are interconnected.

What is data node?
A data node is an appliance that you can add to your event and flow processors to increase storage capacity and improve search performance. You can add an unlimited number of data nodes to your IBM® QRadar® deployment, and they can be added at any time.
What are name nodes in big data?
The NameNode is the centerpiece of an HDFS file system. It keeps the directory tree of all files in the file system, and tracks where across the cluster the file data is kept. It does not store the data of these files itself.
What is a Hadoop node?
A Hadoop cluster is a collection of computers, known as nodes, that are networked together to perform these kinds of parallel computations on big data sets.
What are cluster and nodes?
A cluster is a group of servers or nodes. Using the same train analogy from our Kubernetes 101 post, we called the nodes the individual train cars, such as a tanker or a freight car. The clusters as the body of the train, a connection of all these cars that form the train itself.
What is data node and name node?
The main difference between NameNode and DataNode in Hadoop is that the NameNode is the master node in Hadoop Distributed File System (HDFS) that manages the file system metadata while the DataNode is a slave node in Hadoop distributed file system that stores the actual data as instructed by the NameNode.
What are name nodes?
NameNode is the master node in the Apache Hadoop HDFS Architecture that maintains and manages the blocks present on the DataNodes (slave nodes). NameNode is a very highly available server that manages the File System Namespace and controls access to files by clients.
How many nodes are there in Hadoop?
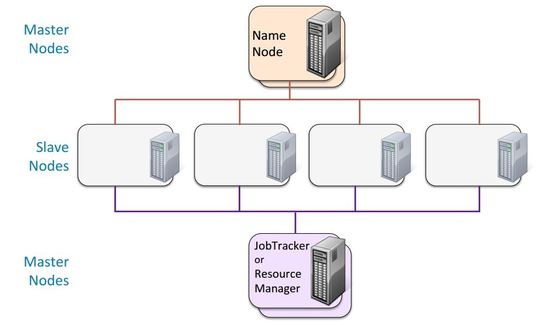
Master Node – Master node in a hadoop cluster is responsible for storing data in HDFS and executing parallel computation the stored data using MapReduce. Master Node has 3 nodes – NameNode, Secondary NameNode and JobTracker.
What are types of nodes in Hadoop?
Types of Nodes in HadoopNameNode: NameNode is the main and heartbeat node of Hdfs and also called master.Secondary NameNode: Secondary NameNode helps to Primary NameNode and merge the namespaces. ... DataNode: ... Checkpoint Node: ... Backup Node: ... Job Tracker Node: ... Task Tracker Node:
What is single node and multi node?
There are no daemons running and everything runs in a single JVM instance. HDFS is not used. Pseudo-distributed or multi-node cluster: The Hadoop daemons run on a local machine, thus simulating a cluster on a small scale. Different Hadoop daemons run in different JVM instances, but on a single machine.
What are nodes in data center?
A node is a single machine that runs Cassandra. A collection of nodes holding similar data are grouped in what is known as a "ring" or cluster. Sometimes if you have a lot of data, or if you are serving data in different geographical areas, it makes sense to group the nodes of your cluster into different data centers.
Are nodes and servers the same?
Node contains less information than server . Nodes and servers have not same function. Main function of server is to access, hold and transfer all files and data from other computer machine over the computer network.
What are nodes and cores?
Nodes, cores, processes and threads Supercomputers have complex architectures, mainly due to their processors capability to work together on the same memory space. More precisely, the smallest computing units, called cores, are grouped in nodes. All the cores in one node share the same memory space.
What is role of NameNode and DataNode in Hadoop?
NameNode and DataNodes HDFS exposes a file system namespace and allows user data to be stored in files. Internally, a file is split into one or more blocks and these blocks are stored in a set of DataNodes. The NameNode executes file system namespace operations like opening, closing, and renaming files and directories.
Is NameNode a process?
Namenode is a daemon (background process) that runs on the 'Master Node' of Hadoop Cluster. Functions of Namenode are: 1. To store all the metadata(data about data) of all the slave nodes in a Hadoop cluster.
What type of data is stored in NameNode?
NameNode only stores the metadata of HDFS – the directory tree of all files in the file system, and tracks the files across the cluster. NameNode does not store the actual data or the dataset. The data itself is actually stored in the DataNodes.
How many nodes does a Hadoop system have?
Master Node – Master node in a hadoop cluster is responsible for storing data in HDFS and executing parallel computation the stored data using MapReduce. Master Node has 3 nodes – NameNode, Secondary NameNode and JobTracker.
What is a node in Microsoft?
He's also the GM & VP of Lifewire. A node is any physical device within a network of other tools that’s able to send, receive, or forward information.
What is a node in a TV?
Other Types of Nodes. In a fiber-based cable TV network, nodes are the homes or businesses that connect to the same fiber optic receiver. Another example of a node is a device that provides intelligent network service within a cellular network, like a base station controller (BSC) or Gateway GPRS Support Node (GGSN).
What is end node problem?
The term "end node problem” refers to the security risk that comes with users connecting their computers or other devices to a sensitive network, either physically (like at work) or through the cloud (from anywhere), while at the same time using that same device to perform unsecured activities.
What is a node in JavaScript?
The word "node" also appears in node.js, which is a JavaScript runtime environment that executes server-side JavaScript code. The "js" there doesn't refer to the JS file extension used with JavaScript files; it's just the name of the tool.
What is an ISP node?
ISP. Broadband. Ethernet. Wi-Fi & Wireless. A node is any physical device within a network of other tools that’s able to send, receive, or forward information. A personal computer is the most common node. It's called the computer node or internet node . Modems, switches, hubs, bridges, servers, and printers are also nodes, ...
What is a supernode in P2P?
A supernode is a node within a peer-to-peer network that functions not only as a regular node but also as a proxy server and the device that relays information to other users within the P2P system. Because of this, supernodes require more CPU and bandwidth than regular nodes.
What is the name of the master node in Hadoop?
HDFS or Hadoop Distributed File System have Namenode and data node. Namenode is the master node running the master daemon, and it manages the data nodes and keeps tracks of all operations. Datanodes are the slaves where the data is actually stored.
Why is Hadoop used in data science?
It has collaborated with Hadoop to help data scientists to gain better insight by providing an environment that gives visual and interactive experience, thus helping to explore new trends. The analytical programs extract meaningful insights from data, and the in-memory technology helps faster data access.
Why is Hadoop important?
For this reason, professionals with Hadoop skills will always find ample opportunities in the coming days and can be a vital asset for an organization boosting the business and their career.
What are the components of Hadoop?
Several Components of Hadoop. There are several components like the pig, hive, sqoop, flume, mahout, oozie, zookeeper, HBase, etc. Sqoop – It is used to import and export data from RDBMS to Hadoop and vice versa. Flume – It is used to pull real-time data into Hadoop. Kafka – It is a messaging system used to route real-time data.
What is Hadoop software?
Hadoop is an open-source software framework for storing and processing big data sets using a distributed large cluster of commodity hardware. It was developed by Doug Cutting and Michael J. Cafarella and licensed under Apache.
What are the advantages of Hadoop?
Advantages of Hadoop. Below are a few of the advantages of Hadoop: Scalable – Unlike traditional RDBMS, it is a highly scalable platform as it can store large datasets in distributed clusters over commodity hardware operating in parallel.
Is Hadoop in high demand?
Bigdata and Hadoop are in high demand in today’s market. This is going to increase more in the coming days. Lots of organization have already moved into Hadoop, and those who have not are going to move soon. There is a current report stating that major corporations have started investing in big data analytics.
What is big data?
Big data is a blanket term for the non-traditional strategies and technologies needed to gather, organize, process, and gather insights from large datasets. While the problem of working with data that exceeds the computing power or storage of a single computer is not new, the pervasiveness, scale, and value of this type ...
What is a large dataset?
In this context, “large dataset” means a dataset too large to reasonably process or store with traditional tooling or on a single computer. This means that the common scale of big datasets is constantly shifting and may vary significantly from organization to organization.
Why is sheer scale important in big data?
The sheer scale of the information processed helps define big data systems. These datasets can be orders of magnitude larger than traditional datasets , which demands more thought at each stage of the processing and storage life cycle.
What is the term for data that cannot be handled by traditional computers?
Big data: Big data is an umbrella term for datasets that cannot reasonably be handled by traditional computers or tools due to their volume, velocity, and variety. This term is also typically applied to technologies and strategies to work with this type of data. Batch processing: Batch processing is a computing strategy ...
What is data ingestion?
Data ingestion is the process of taking raw data and adding it to the system. The complexity of this operation depends heavily on the format and quality of the data sources and how far the data is from the desired state prior to processing.
Why is big data important?
Big data is a broad, rapidly evolving topic. While it is not well-suited for all types of computing, many organizations are turning to big data for certain types of work loads and using it to supplement their existing analysis and business tools. Big data systems are uniquely suited for surfacing difficult-to-detect patterns and providing insight into behaviors that are impossible to find through conventional means. By correctly implement systems that deal with big data, organizations can gain incredible value from data that is already available.
Why are clusters better than individual computers?
Clustered Computing. Because of the qualities of big data , individual computers are often inadequate for handling the data at most stages. To better address the high storage and computational needs of big data , computer clusters are a better fit.
What is big data?
Big data is the data that is characterized by such informational features as the log-of-events nature and statistical correctness, and that imposes such technical requirements as distributed storage, parallel data processing and easy scalability of the solution.
How is big data used in BI?
Big data can be used both as a part of traditional BI and in an independent system. Let’s turn to examples again. A company analyses big data to identify behavior patterns of every customer. Based on these insights, it allocates the customers with similar behavior patterns to a particular segment. Finally, a traditional BI system uses customer segments as another attribute for reporting. For instance, users can create reports that show the sales per customer segment or their response to a recent promotion.
How to learn about big data?
Our big data consultants created a short quiz. There are five questions for you to check how much you’ve learned about big data: 1 What kind of data processing does big data require? 2 Is big data 100% reliable and accurate? 3 If your goal is to create a unique customer experience, what kind of big data analytics do you need? 4 Name at least three external sources of big data. 5 Is there any similarity between Hadoop and Apache Spark?
Why use sensor data?
2. Industrial analytics. To avoid expensive downtimes that affect all the related processes, manufacturers can use sensor data to foster proactive maintenance. Imagine that the analytical system has been collecting and analyzing sensor data for several months to form a history of observations.
Why do companies use big data analytics?
Companies also use big data analytics to monitor the performance of their remote employees and improve the efficiency of the processes. Let’s take transportation as an example. Companies can collect and store the telemetry data that comes from each truck in real time to identify a typical behavior of each driver.
What are the two types of big data?
There are two types of big data sources: internal and external ones . Data is internal if a company generates, owns and controls it. External data is public data or the data generated outside the company; correspondingly, the company neither owns nor controls it.
Is big data good for bookkeeping?
So, it doesn’t make much sense to use big data for bookkeeping. However, big data is correct statistically and can give a clear understanding of the overall picture, trends and dependencies.
Hardware Configuration
Hardware configuration of nodes varies from cluster to cluster and it depends on the usage of the cluster. In Some Hadoop clusters the velocity of data growth is high, in that instance more importance is given to the storage capacity.
Name Node Configuration
Processors: 2 Quad Core CPUs running @ 2 GHz RAM: 128 GB Disk: 6 x 1TB SATA Network: 10 Gigabit Ethernet
Data Node Configuration
Like what you are reading? Enroll in our free Hadoop Starter Kit course & explore Hadoop in depth.
What Does A Network Node do?

Other Types of Nodes
- In a fiber-based cable TV network, nodes are the homes or businesses that connect to the same fiber optic receiver. Another example of a node is a device that provides intelligent network service within a cellular network, like a base station controller (BSC) or Gateway GPRS Support Node (GGSN). In other words, the mobile node is what provides the software controls behind th…
What Is The End-Node Problem?
- The term "end node problem” refers to the security risk that comes with users connecting their computers or other devices to a sensitive network, either physically (like at work) or through the cloud (from anywhere), while at the same time using that same device to perform unsecured activities. Some examples include an end-user who takes their work laptop home but then check…
Other Node Meanings
- "Node" also describes a computer file in a tree data structure. Much like a real tree where the branches hold their leaves, the folders within a data structure contain records. The files are called leaves or leaf nodes. The word "node" also appears in node.js, which is a JavaScript runtime environment that executes server-side JavaScript code. The "js" there doesn't refer to the JS file …