
| Unicode code point | character | UTF-8 (hex.) | name |
| U+00C5 | Å | c3 85 | LATIN CAPITAL LETTER A WITH RING ABOVE |
| U+00C6 | Æ | c3 86 | LATIN CAPITAL LETTER AE |
| U+00C7 | Ç | c3 87 | LATIN CAPITAL LETTER C WITH CEDILLA |
| U+00C8 | È | c3 88 | LATIN CAPITAL LETTER E WITH GRAVE |
What is the difference between ANSI and UTF 8?
- ANSI uses fixed bytes, while UTF 8 uses multibyte.
- ANSI is fixed, while UTF 8 is more flexible.
- ANSI can use only 256 characters as it uses a byte. ...
- ANSI doesn’t have a distinct code point for each character, while UTF 8 has a distinct code point for every character.
Is ASCII and UTF 8 the same?
However, a 1-byte code in UTF-8 is the same as the ASCII character set. This is because ASCII still forms the foundation of UTF-8 and is therefore included in its set. In the late ‘80s, both the Unicode Consortium and the standardization subcommittee ISO/IEC JTC 1/SC 2 began work on a universal character set.
What is the difference between UTF-8 and ISO-8859-1?
What is the difference between UTF-8 and ISO-8859-1? UTF-8 is a multibyte encoding that can represent any Unicode character. ISO 8859-1 is a single-byte encoding that can represent the first 256 Unicode characters.
Does UTF 8 support all languages?
UTF-8 supports any unicode character, which pragmatically means any natural language (Coptic, Sinhala, Phonecian, Cherokee etc), as well as many non-spoken languages (Music notation, mathematical symbols, APL). The stated objective of the Unicode consortium is to encompass all communications. The few exceptions which are not supported well (like Klingon) usually have a roman-alphabet equivalent and/or have an unofficial private unicode code page.
What is UTF-8 encoded text?
UTF-8 is a character encoding system. It lets you represent characters as ASCII text, while still allowing for international characters, such as Chinese characters. As of the mid 2020s, UTF-8 is one of the most popular encoding systems.
What is UTF-8 encoding used for?
UTF-8 is the most widely used way to represent Unicode text in web pages, and you should always use UTF-8 when creating your web pages and databases. But, in principle, UTF-8 is only one of the possible ways of encoding Unicode characters.
What characters are not allowed in UTF-8?
Yes. 0xC0, 0xC1, 0xF5, 0xF6, 0xF7, 0xF8, 0xF9, 0xFA, 0xFB, 0xFC, 0xFD, 0xFE, 0xFF are invalid UTF-8 code units.
How do you tell if a file is UTF-8 encoded?
Open the file in Notepad. Click 'Save As...'. In the 'Encoding:' combo box you will see the current file format. Yes, I opened the file in notepad and selected the UTF-8 format and saved it.
What are the 3 types of character encoding?
UNICODE Encoding standard has the following UTF schemes:UTF-8 Encoding. The UTF8 is defined by the UNICODE standard, which is variable-width character encoding used in Electronics Communication. ... UTF-16 Encoding. UTF16 Encoding represents a character's code points using one of two 16-bits integers.UTF-32 Encoding.
What is difference between UTF-8 and ASCII?
UTF-8 encodes Unicode characters into a sequence of 8-bit bytes. The standard has a capacity for over a million distinct codepoints and is a superset of all characters in widespread use today. By comparison, ASCII (American Standard Code for Information Interchange) includes 128 character codes.
How many UTF-8 characters are there?
UTF-8 is capable of encoding all 1,112,064 valid character code points in Unicode using one to four one-byte (8-bit) code units.
Are Emojis UTF-8?
Emojis look like images, or icons, but they are not. They are letters (characters) from the UTF-8 (Unicode) character set.
How do I change my UTF-8 encoding?
UTF-8 Encoding in Notepad (Windows)Open your CSV file in Notepad.Click File in the top-left corner of your screen.Click Save as...In the dialog which appears, select the following options: In the "Save as type" drop-down, select All Files. In the "Encoding" drop-down, select UTF-8. ... Click Save.
What is UTF-8 and what problem does it solve?
The problem UTF-8 solves US keyboards can often produce 101 symbols, which suggests 101 symbols would be enough for most English text. Seven bits would be enough to encode these symbols since 27 = 128, and that's what ASCII does.
How do you determine character encoding?
One way to check this is to use the W3C Markup Validation Service. The validator usually detects the character encoding from the HTTP headers and information in the document. If the validator fails to detect the encoding, it can be selected on the validator result page via the 'Encoding' pulldown menu (example).
How do I change the encoding of a text file?
Choose an encoding standard when you open a fileClick the File tab.Click Options.Click Advanced.Scroll to the General section, and then select the Confirm file format conversion on open check box. ... Close and then reopen the file.In the Convert File dialog box, select Encoded Text.More items...
Why do we need encoding?
The purpose of encoding is to transform data so that it can be properly (and safely) consumed by a different type of system, e.g. binary data being sent over email, or viewing special characters on a web page. The goal is not to keep information secret, but rather to ensure that it's able to be properly consumed.
Does UTF 8 support all languages?
Content. UTF-8 supports any unicode character, which pragmatically means any natural language (Coptic, Sinhala, Phonecian, Cherokee etc), as well as many non-spoken languages (Music notation, mathematical symbols, APL). The stated objective of the Unicode consortium is to encompass all communications.
What are examples of encoding?
For example, you may realize you're hungry and encode the following message to send to your roommate: “I'm hungry. Do you want to get pizza tonight?” As your roommate receives the message, they decode your communication and turn it back into thoughts to make meaning.
What is UTF-8 encoding?
UTF-8 is a variable-width character encoding used for electronic communication. Defined by the Unicode Standard, the name is derived from Unicode (or Universal Coded Character Set) Transformation Format – 8-bit. UTF-8 is capable of encoding all 1,112,064 valid character code points in Unicode using one to four one- byte (8-bit) code units.
What is the encoding code for UTF-8?
The official Internet Assigned Numbers Authority (IANA) code for the encoding is "UTF-8". All letters are upper-case, and the name is hyphenated. This spelling is used in all the Unicode Consortium documents relating to the encoding.
What is CESU-8?
Unicode Technical Report #26 assigns the name CESU-8 to a nonstandard variant of UTF-8, in which Unicode characters in supplementary planes are encoded using six bytes, rather than the four bytes required by UTF-8.
Why is UTF-16 important?
These encodings are very useful because they avoid the need to deal with "invalid" byte strings until much later, if at all, and allow "text" and "data" byte arrays to be the same object. If a program wants to use UTF-16 internally these are required to preserve and use filenames that can use invalid UTF-8; as the Windows filesystem API uses UTF-16, the need to support invalid UTF-8 is less there.
What is UTF-8 in computer?
UTF-8 was designed as a superior alternative to UTF-1, a proposed variable-width encoding with partial ASCII compatibility which lacked some features including self-synchronization and fully ASCII-compatible handling of characters such as slashes. Ken Thompson and Rob Pike produced the first implementation for the Plan 9 operating system in September 1992. This led to its adoption by X/Open as its specification for FSS-UTF, which would first be officially presented at USENIX in January 1993 and subsequently adopted by the Internet Engineering Task Force (IETF) in RFC 2277 ( BCP 18) for future Internet standards work, replacing Single Byte Character Sets such as Latin-1 in older RFCs.
How many bytes does a character take?
A "character" can actually take more than 4 bytes, e.g. an emoji flag character takes 8 bytes since it's "constructed from a pair of Unicode scalar values".
How many bits per byte is UTF-8?
UTF-8's use of six bits per byte to represent the actual characters being encoded, means that octal notation (which uses 3-bit groups) can aid in the comparison of UTF-8 sequences with one another and in manual conversion.
What Is UTF-8?
UTF-8 stands for “Unicode Transformation Format - 8 bits.” That’s not helpful to us yet, so let’s rewind to the basics.
Why is UTF-8 unique?
There are other encoding systems for Unicode besides UTF-8, but UTF-8 is unique because it represents characters in one-byte units. Remember that one byte consists of eight bits, hence the “-8” in its name.
How many bytes are there in ASCII?
The number of characters that ASCII can represent is limited to the number of unique bytes available, since each character gets one byte. If you do the math, you’ll find that there are 256 different ways of groups eight 1s and 0s together. This gives us 256 different bytes, or 256 ways to represent a character in ASCII. When ASCII was introduced in 1960, this was okay, since developers needed only 128 bytes to represent all the English characters and symbols they needed.
How many bytes are in a UTF-8 string?
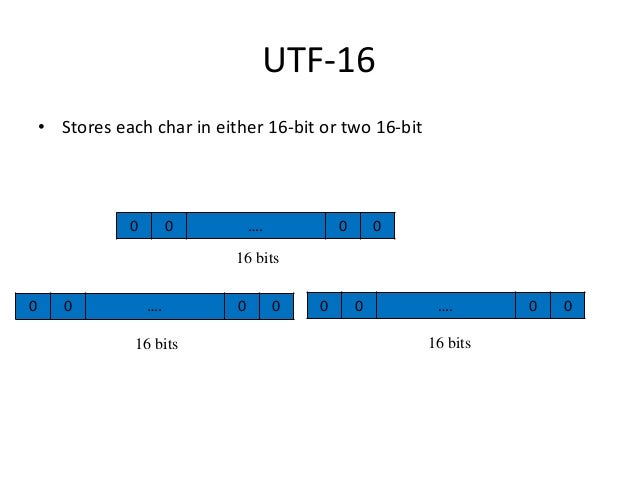
These methods differ in the number of bytes they need to store a character. UTF-8 encodes a character into a binary string of one, two, three, or four bytes. UTF-16 encodes a Unicode character into a string of either two or four bytes. This distinction is evident from their names.
How many code points does Unicode have?
Like ASCII, Unicode assigns a unique code, called a code point, to each character. However, Unicode’s more sophisticated system can produce over a million code points, more than enough to account for every character in any language. Unicode is now the universal standard for encoding all human languages.
What is the advantage of UTF-8?
Spatial efficiency is a key advantage of UTF-8 encoding. If instead every Unicode character was represented by four bytes, a text file written in English would be four times the size of the same file encoded with UTF-8.
What is the ASCII library?
ASCII’s library includes every upper-case and lower-case letter in the Latin alphabet (A, B, C…), every digit from 0 to 9, and some common symbols ( like /, !, and ?). It assigns each of these characters a unique three-digit code and a unique byte.
What is UTF-8 encoding?from en.wikipedia.org
UTF-8 is a variable-width character encoding used for electronic communication. Defined by the Unicode Standard, the name is derived from Unicode (or Universal Coded Character Set) Transformation Format – 8-bit. UTF-8 is capable of encoding all 1,112,064 valid character code points in Unicode using one to four one- byte (8-bit) code units.
How many bytes are in CESU-8?from en.wikipedia.org
Unicode Technical Report #26 assigns the name CESU-8 to a nonstandard variant of UTF-8, in which Unicode characters in supplementary planes are encoded using six bytes, rather than the four bytes required by UTF-8.
What is utf8mb3 in MySQL?from en.wikipedia.org
In MySQL, the utf8mb3 character set is defined to be UTF-8 encoded data with a maximum of three bytes per character , meaning only Unicode characters in the Basic Multilingual Plane (i.e. from UCS-2) are supported . Unicode characters in supplementary planes are explicitly not supported. utf8mb3 is deprecated in favor of the utf8mb4 character set, which uses standards-compliant UTF-8 encoding. utf8 is an alias for utf8mb3, but is intended to become an alias to utf8mb4 in a future release of MySQL. It is possible, though unsupported, to store CESU-8 encoded data in utf8mb3, by handling UTF-16 data with supplementary characters as though it is UCS-2.
What is UTF-8 Mb3?from en.wikipedia.org
In MySQL, the utf8mb3 character set is defined to be UTF-8 encoded data with a maximum of three bytes per character , meaning only Unicode characters in the Basic Multilingual Plane (i.e. from UCS-2) are supported. Unicode characters in supplementary planes are explicitly not supported. utf8mb3 is deprecated in favor of the utf8mb4 character set, which uses standards-compliant UTF-8 encoding. utf8 is an alias for utf8mb3, but is intended to become an alias to utf8mb4 in a future release of MySQL. It is possible, though unsupported, to store CESU-8 encoded data in utf8mb3, by handling UTF-16 data with supplementary characters as though it is UCS-2.
What is the backward compatibility of UTF-8?from en.wikipedia.org
Backward compatibility: Backward compatibility with ASCII and the enormous amount of software designed to process ASCII-encoded text was the main driving force behind the design of UTF-8. In UTF-8, single bytes with values in the range of 0 to 127 map directly to Unicode code points in the ASCII range. Single bytes in this range represent characters, as they do in ASCII. Moreover, 7-bit bytes (bytes where the most significant bit is 0) never appear in a multi-byte sequence, and no valid multi-byte sequence decodes to an ASCII code-point. A sequence of 7-bit bytes is both valid ASCII and valid UTF-8, and under either interpretation represents the same sequence of characters. Therefore, the 7-bit bytes in a UTF-8 stream represent all and only the ASCII characters in the stream. Thus, many text processors, parsers, protocols, file formats, text display programs, etc., which use ASCII characters for formatting and control purposes, will continue to work as intended by treating the UTF-8 byte stream as a sequence of single-byte characters, without decoding the multi-byte sequences. ASCII characters on which the processing turns, such as punctuation, whitespace, and control characters will never be encoded as multi-byte sequences. It is therefore safe for such processors to simply ignore or pass-through the multi-byte sequences, without decoding them. For example, ASCII whitespace may be used to tokenize a UTF-8 stream into words; ASCII line-feeds may be used to split a UTF-8 stream into lines; and ASCII NUL characters can be used to split UTF-8-encoded data into null-terminated strings. Similarly, many format strings used by library functions like "printf" will correctly handle UTF-8-encoded input arguments.
What is CESU-8 in Unicode?from en.wikipedia.org
Unicode Technical Report #26 assigns the name CESU-8 to a nonstandard variant of UTF-8, in which Unicode characters in supplementary planes are encoded using six bytes , rather than the four bytes required by UTF-8. CESU-8 encoding treats each half of a four-byte UTF-16 surrogate pair as a two-byte UCS-2 character, yielding two three-byte UTF-8 characters, which together represent the original supplementary character. Unicode characters within the Basic Multilingual Plane appear as they would normally in UTF-8. The Report was written to acknowledge and formalize the existence of data encoded as CESU-8, despite the Unicode Consortium discouraging its use, and notes that a possible intentional reason for CESU-8 encoding is preservation of UTF-16 binary collation.
What is CESU-8?from en.wikipedia.org
Unicode Technical Report #26 assigns the name CESU-8 to a nonstandard variant of UTF-8, in which Unicode characters in supplementary planes are encoded using six bytes, rather than the four bytes required by UTF-8.
How many characters can be encoded with UTF-8?
UTF-8, even with a four byte limitation, supports 2 21 code points, which is far more than 17 * 2^16. 2,164,864 “characters” can be potentially coded by UTF-8. This number is 2 7 + 2 11 + 2 16 + 2 21, which comes from the way the encoding works:
What is UTF-8 in text?
The “8” in “UTF-8” relates to the length of code units in bits. Code units are entities use to encode characters, not necessarily as a simple one-to-one mapping. UTF-8 uses a variable number of code units to encode a character. The collection of characters that can be encoded in UTF-8 is exactly the same as for UTF-16 or UTF-32, ...
How many bits are in a 4 byte sequence?
So a four byte sequence would begin with 11110... (and ... = three bits for the value) then three bytes with 6 bits each for the value, yielding a 21 bit value. 2^21 exceeds the number of unicode characters, so all of unicode can be expressed in UTF8.
What is the difference between Unicode and UTF-8?
Unicode resolves code points to characters. UTF-8 is a storage mechanism for Unicode. Unicode has a spec. UTF-8 has a spec. They both have different limits. UTF-8 has a different upwards-bound.
How many bytes are needed for the Latin alphabet?
The first 128 characters (US-ASCII) need one byte. The next 1,920 characters need two bytes to encode. This covers the remainder of almost all Latin alphabets, and also Greek, Cyrillic, Coptic, Armenian, Hebrew, Arabic, Syriac and Tāna alphabets, as well as Combining Diacritical Marks. Three bytes are needed for characters in the rest ...
How many bytes are in UTF-8?
UTF-8 does not use one byte all the time, it's 1 to 4 bytes.
How many planes are there in Unicode?
Unicode is designated with "planes." Each plane carries 2 16 code points. There are 17 Planes in Unicode. For a total of 17 * 2^16 code points. The first plane, plane 0 or the BMP, is special in the weight of what it carries.
How long is a UTF-8 character?
UTF-8. A character in UTF8 can be from 1 to 4 bytes long. UTF-8 can represent any character in the Unicode standard. UTF-8 is backwards compatible with ASCII. UTF-8 is the preferred encoding for e-mail and web pages. UTF-16.
What is the Unicode standard?
The Unicode standard is also support ed in many operating systems and all modern browsers. The Unicode Consortium cooperates with the leading standards development organizations, like ISO, W3C, and ECMA.
What is HTML5 standard?
The HTML5 Standard: Unicode UTF-8. Because the character sets in ISO-8859 were limited in size, and not compatible in multilingual environments, the Unicode Consortium developed the Unicode Standard. The Unicode Standard covers (almost) all the characters, punctuations, and symbols in the world. Unicode enables processing, storage, and transport ...
What is the purpose of the Unicode Consortium?
The Unicode Consortium develops the Unicode Standard. Their goal is to replace the existing character sets with its standard Unicode Transformation Format (UTF).
What is encoding in computer?
Encoding is how these numbers are translated into binary numbers to be stored in a computer:
What is Unicode used for?
Unicode enables processing, storage, and transport of text independent of platform and language.
What is 16 bit?
16-bit Unicode Transformation Format is a variable-length character encoding for Unicode, capable of encoding the entire Unicode repertoire. UTF-16 is used in major operating systems and environments, like Microsoft Windows, Java and .NET.

Overview
UTF-8 is a variable-width character encoding used for electronic communication. Defined by the Unicode Standard, the name is derived from Unicode (or Universal Coded Character Set) Transformation Format – 8-bit.
UTF-8 is capable of encoding all 1,112,064 valid character code points in Unicode using one to four one-byte (8-bit) code units. Code points with lower numerical values, which tend to occur more fr…
Naming
The official Internet Assigned Numbers Authority (IANA) code for the encoding is "UTF-8". All letters are upper-case, and the name is hyphenated. This spelling is used in all the Unicode Consortium documents relating to the encoding.
However, the name "utf-8" may be used by all standards conforming to the IANA list (which include CSS, HTML, XML, and HTTP headers), as the declaration is case-insensitive.
Encoding
Since the restriction of the Unicode code-space to 21-bit values in 2003, UTF-8 is defined to encode code points in one to four bytes, depending on the number of significant bits in the numerical value of the code point. The following table shows the structure of the encoding. The x characters are replaced by the bits of the code point.
The first 128 code points (ASCII) need one byte. The next 1,920 code points need two bytes to e…
Adoption
Many standards only support UTF-8, e.g. open JSON exchange requires it (without a byte order mark (BOM)). UTF-8 is also the recommendation from the WHATWG for HTML and DOM specifications, and the Internet Mail Consortium recommends that all e-mail programs be able to display and create mail using UTF-8. The World Wide Web Consortium recommends UTF-8 as the default enc…
History
The International Organization for Standardization (ISO) set out to compose a universal multi-byte character set in 1989. The draft ISO 10646 standard contained a non-required annex called UTF-1 that provided a byte stream encoding of its 32-bit code points. This encoding was not satisfactory on performance grounds, among other problems, and the biggest problem was probably that it did not have a clear separation between ASCII and non-ASCII: new UTF-1 tools would be backward c…
Standards
There are several current definitions of UTF-8 in various standards documents:
• RFC 3629 / STD 63 (2003), which establishes UTF-8 as a standard internet protocol element
• RFC 5198 defines UTF-8 NFC for Network Interchange (2008)
• ISO/IEC 10646:2014 §9.1 (2014)
Comparison with other encodings
Some of the important features of this encoding are as follows:
• Backward compatibility: Backward compatibility with ASCII and the enormous amount of software designed to process ASCII-encoded text was the main driving force behind the design of UTF-8. In UTF-8, single bytes with values in the range of 0 to 127 map directly to Unicode code points in the ASCII range. Single bytes in this range represent characters, as they do in ASCII. M…
Derivatives
The following implementations show slight differences from the UTF-8 specification. They are incompatible with the UTF-8 specification and may be rejected by conforming UTF-8 applications.
Unicode Technical Report #26 assigns the name CESU-8 to a nonstandard variant of UTF-8, in which Unicode characters in supplementary planes are encoded using six bytes, rather than the four bytes required by UTF-8. CESU-8 encoding treats each half of a four-byte UTF-16 surrogate …
What Is Utf-8?
Utf-8 Characters in Web Development
- UTF-8 is the most common character encoding method used on the internet today, and is the default character set for HTML5. Over 95% of all websites, likely including your own, store characters this way. Additionally, common data transfer methods over the web, like XML and JSON, are encoded with UTF-8 standards. Since it’s now the standard method for encoding text …
Utf-8 vs. UTF-16
- As I mentioned, UTF-8 is not the only encoding method for Unicode characters — there’s also UTF-16. These methods differ in the number of bytes they need to store a character. UTF-8 encodes a character into a binary string of one, two, three, or four bytes. UTF-16 encodes a Unicode character into a string of either two or four bytes. This distincti...
Decoding The World of Utf-8 Encoding
- That was a lot of words about words, so let’s summarize what we’ve covered: 1. Computers store data, including text characters, as binary (1s and 0s). 2. ASCII was an early way of encoding, or mapping characters to binary code so that computers could store them. However, ASCII did not provide enough room for non-Latin characters and numbers to be represented in binary. 3. Unico…