Sample Statistics
- x refers to a sample mean.
- s refers to the standard deviation of a sample.
- s2 refers to the variance of a sample.
- p refers to the proportion of sample elements that have a particular attribute.
- q refers to the proportion of sample elements that do not have a particular attribute, so q = 1 - p.
How do 'X bar' and 'Mu' differ in statistics?
“x bar” refers to the mean for a sample; “mu” refers to the mean for a population. The former is a “statistic”; the latter a “parameter”. We use statistics to estimate parameters and conduct hypothesis tests about the values of unknown parameters of interest.
What does "X" and "y" mean in science?
x-axis (in mathematics) The horizontal line at the bottom of a graph, which can be labeled to give information about what the graph represents. y-axis (in mathematics) The vertical line to the left or right of a graph, which can be labeled to give information about what the graph represents.
What is numeric X in statistics?
X refers to a set of population elements; and x, to a set of sample elements. N refers to population size; and n, to sample size. Like capital letters, Greek letters refer to population attributes. Their sample counterparts, however, are usually Roman letters. For example, μ refers to a population mean; and x, to a sample mean.
What is the SX in statistics?
sx is the sample standard deviation for x values. sy is the sample standard deviation for y values. See also How many degrees are in a mile of latitude? What is SX on ti84?
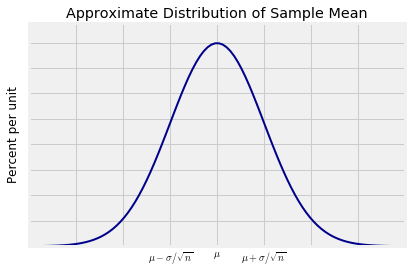
What does X̄ mean?
X-bar in statistics is a symbol for the sample mean. Given a sample of n observations of numbers, the sample mean is found by adding up all of the observations, then dividing by the total number of observations (n).
How do you find X in statistics?
In summary, in order to use a normal probability to find the value of a normal random variable X: Find the z value associated with the normal probability. Use the transformation x = μ + z σ to find the value of x.
What is X and X bar in statistics?
In statistics, x-bar (x) is a symbol used to represent the sample mean of a dataset.
What are the symbols for statistics?
List of Probability and Statistics SymbolsSymbolSymbol NameMeaning / definitionstd(X)standard deviationstandard deviation of random variable Xσ2variancevariance of population valuesx ~medianmiddle value of random variable xσXstandard deviationstandard deviation value of random variable X35 more rows
What does the x bar mean in statistics?
In statistics, an x-bar indicates the average or mean value of the random variable "x." A bar over any capital letter indicates the mean value of a random variable.
Why is the x bar not the same number?
Because "x" is a random variable, x-bar is not the same number if it is measured repeatedly. The x-bar should not be confused with the other average quantities, the median and the mode. The median indicates the middle of the observed values of "x.".
What is mode in statistics?
The mode is the most commonly observed value of "x.". The value with the highest number of observations, if there is such a value, is the mode. When there is no value that occurs more often than other values, the data set has no mode. ADVERTISEMENT.
What is X-Bar?
Before discussing x-bar, some prerequisite information is needed about populations and samples in statistics. Here are a few definitions that are needed:
What Does X-Bar Mean?
In statistics, an estimate is a number that approximates a population parameter that is found from some sample. A point estimate is a single number that is the best estimate for some population parameter.
What Is a Chi-Square Statistic?
A chi-square ( χ2) statistic is a test that measures how a model compares to actual observed data. The data used in calculating a chi-square statistic must be random, raw, mutually exclusive, drawn from independent variables, and drawn from a large enough sample. For example, the results of tossing a fair coin meet these criteria.
Who uses chi-square analysis?
Since chi-square applies to categorical variables, it is most used by researchers who are studying survey response data. This type of research can range from demography to consumer and marketing research to political science and economics.
Why do we use chi square test?
A chi-square test is used to help determine if observed results are in line with expected results, and to rule out that observations are due to chance. A chi-square test is appropriate for this when the data being analyzed is from a random sample, and when the variable in question is a categorical variable. A categorical variable is one that consists of selections such as type of car, race, educational attainment, male vs. female, how much somebody likes a political candidate (from very much to very little), etc.
What are operators in statistics?
Operators. In probability and statistics, operators denote mathematical operations which are used to better make sense of data and chances. These include key combinatorial operators, probability-related operators/functions, probability distributions and statistical operators.
What is the meaning of P#N#robability?
P#N#robability and statistics correspond to the mathematical study of chance and data, respectively . The following reference list documents some of the most notable symbols in these two topics, along with each symbol’s usage and meaning.
What is mean in statistics?
The mean, or arithmetic mean, of a data set is the sum of all values divided by the total number of values. It’s the most commonly used measure of central tendency and is often referred to as the “average.”.
How many steps are there in calculating mean?
There are two steps for calculating the mean:
When can you use the mean, median or mode?
The mean is the most widely used measure of central tendency because it uses all values in its calculation. The best measure of central tendency depends on your type of variable and the shape of your distribution.
How does an outlier affect the mean?
Because all values are used in the calculation of the mean, an outlier can have a dramatic effect on the mean by pulling the mean away from the majority of the values. Let’s see what happens to the mean when we add an outlier to our data set. Data set. Cost of dinner for two (USD)
What is skewed distribution?
In skewed distributions, more values fall on one side of the center than the other, and the mean, median and mode all differ from each other. One side has a more spread out and longer tail with fewer scores at one end than the other.
Why is the median better than the mean?
For data from skewed distributions, the median is better than the mean because it isn’t influenced by extremely large values.
How much does adding one outlier raise the mean?
As we can see, adding just one outlier to our data set raised the mean by $20. In this case, a different measure of central tendency, like the median, would be more appropriate.