What is AWS glue?
AWS Glue is a fully managed ETL (extract, transform, and load) service that makes it simple and cost-effective to categorize your data, clean it, enrich it, and move it reliably between various data stores and data streams.
How do I use AWS glue for ETL jobs?
You pay only for the resources your jobs use while running. AWS Glue can run your ETL jobs as new data arrives. For example, you can use an AWS Lambda function to trigger your ETL jobs to run as soon as new data becomes available in Amazon S3. You can also register this new dataset in the AWS Glue Data Catalog as part of your ETL jobs.
What is the data catalog and the AWS glue jobs system?
The Data Catalog is a drop-in replacement for the Apache Hive Metastore. The AWS Glue Jobs system provides a managed infrastructure for defining, scheduling, and running ETL operations on your data. For more information about the AWS Glue API, see AWS Glue API . You use the AWS Glue console to define and orchestrate your ETL workflow.
How long does an AWS glue job take to run?
The default is 2,880 minutes (48 hours). MaxCapacity – Number (double). For Glue version 1.0 or earlier jobs, using the standard worker type, the number of AWS Glue data processing units (DPUs) that can be allocated when this job runs.
See more

Why do we use glue in AWS?
AWS Glue provides both visual and code-based interfaces to make data integration easier. Users can easily find and access data using the AWS Glue Data Catalog. Data engineers and ETL (extract, transform, and load) developers can visually create, run, and monitor ETL workflows with a few clicks in AWS Glue Studio.
How do I get a job with AWS Glue?
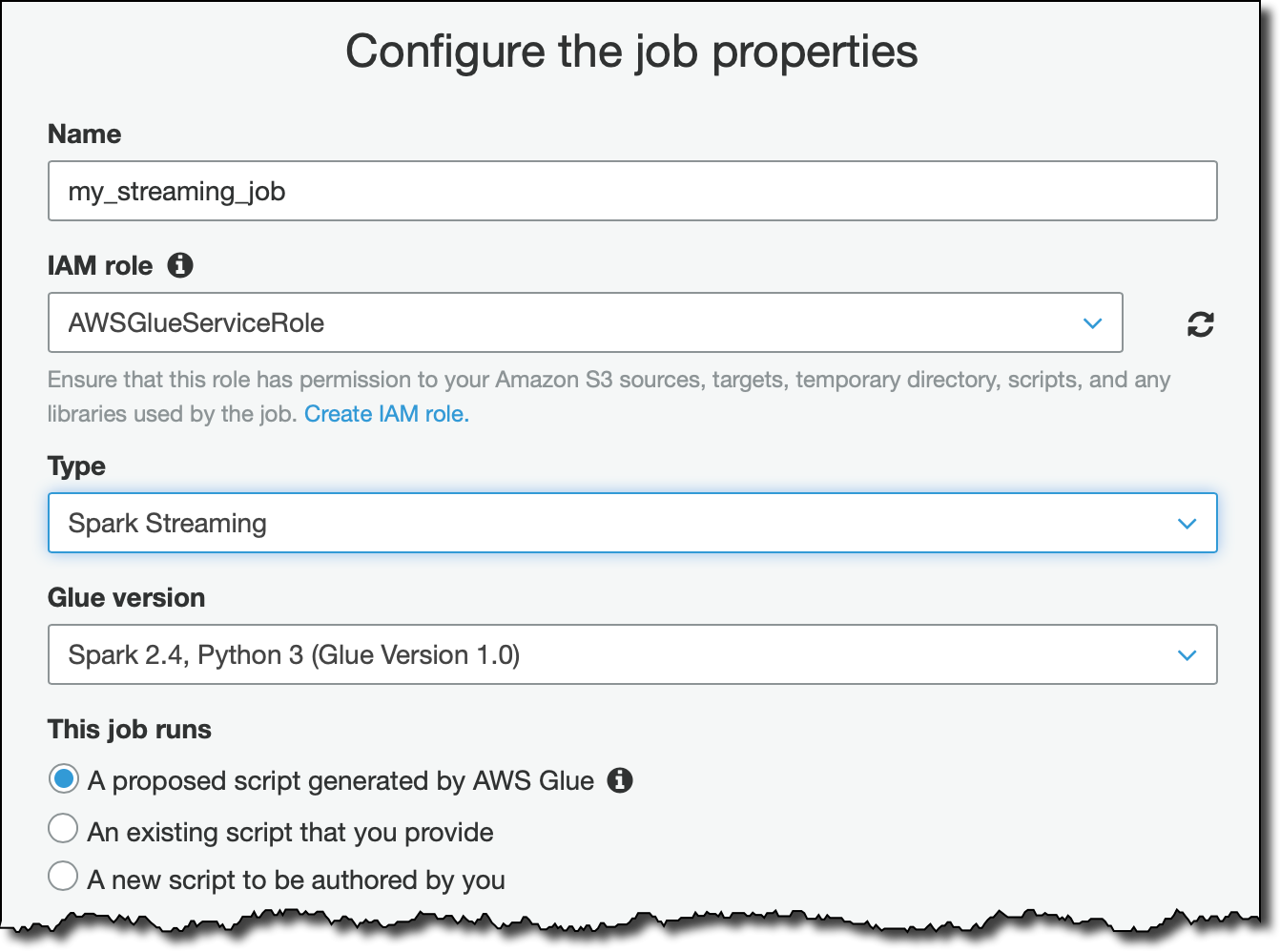
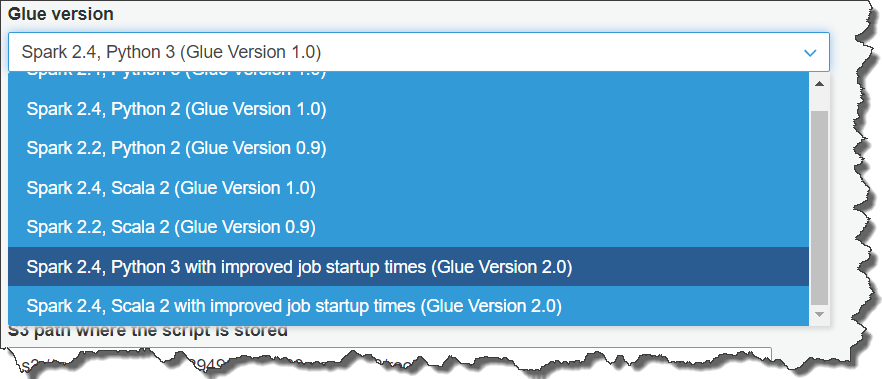
Open the AWS Glue console, and choose the Jobs tab. Choose Add job, and follow the instructions in the Add job wizard. If you decide to have AWS Glue generate a script for your job, you must specify the job properties, data sources, and data targets, and verify the schema mapping of source columns to target columns.
Does AWS Glue require coding?
You can choose any of the above options based on your requirements. If you prefer no code or less code experience, the AWS Glue Studio visual editor is a good choice. If you prefer an interactive notebook experience, AWS Glue Studio notebook is a good choice.
What are workers in glue?
AWS Glue comes with three worker types to help customers select the configuration that meets their job latency and cost requirements. These workers, also known as Data Processing Units (DPUs), come in Standard, G. 1X, and G. 2X configurations.
Can glue run Python?
You can use a Python shell job to run Python scripts as a shell in AWS Glue. With a Python shell job, you can run scripts that are compatible with Python 2.7, Python 3.6, or Python 3.9.
What is AWS Glue database?
A database in the AWS Glue Data Catalog is a container that holds tables. You use databases to organize your tables into separate categories. Databases are created when you run a crawler or add a table manually. The database list in the AWS Glue console displays descriptions for all your databases.
Is AWS Glue an ETL tool?
AWS Glue is a serverless data integration service that makes it easier to discover, prepare, move, and integrate data from multiple sources for analytics, machine learning (ML), and application development. AWS Glue can run your extract, transform, and load (ETL) jobs as new data arrives.
What is AWS Glue interview questions?
Top AWS Glue Interview QuestionsWhat is AWS Glue?What are the Features of AWS Glue?How can AWS Glue manage ETL Service?What are the use cases of AWS Glue?What are the drawbacks of AWS Glue?How can we Automate Data Onboarding?How to list all databases and tables in AWS Glue Catalog?What is AWS Glue Data Catalog?More items...
Can Glue write to S3?
You can add a Glue connection to your RDS instance and then use the Spark ETL script to write the data to S3. You'll have to first crawl the database table using Glue Crawler. This will create a table in the Data Catalog which can be used in the job to transfer the data to S3.
What is maximum capacity in AWS Glue?
Maximum capacity Choose an integer from 2 to 100. The default is 10. This job type cannot have a fractional DPU allocation. For AWS Glue version 2.0 or later jobs, you cannot instead specify a Maximum capacity.
How do I create an ETL job in AWS Glue?
1:286:37HOW TO CREATE ETL JOB IN AWS GLUE - YouTubeYouTubeStart of suggested clipEnd of suggested clipNow will created ideal job to load data from CSV to redshift. Now another ETL section you can see inMoreNow will created ideal job to load data from CSV to redshift. Now another ETL section you can see in jobs. Just click on jobs. Now. They are going to be create a job. So just provide you a job name I'
How much data can glue handle?
According to the Glue API docs, the max you can allocate per Job execution is 100 DPUs. AllocatedCapacity – Number (integer). The number of AWS Glue data processing units (DPUs) allocated to runs of this job. From 2 to 100 DPUs can be allocated; the default is 10.
How do I get job status Glue?
You can view the status of an AWS Glue extract, transform, and load (ETL) job while it is running or after it has stopped. You can view the status using the AWS Glue console, the AWS Command Line Interface (AWS CLI), or the GetJobRun action in the AWS Glue API.
Is AWS Glue an ETL tool?
AWS Glue is a serverless data integration service that makes it easier to discover, prepare, move, and integrate data from multiple sources for analytics, machine learning (ML), and application development. AWS Glue can run your extract, transform, and load (ETL) jobs as new data arrives.
How long can an AWS Glue job run?
This is the maximum time that a job run can consume resources before it is terminated and enters TIMEOUT status. This value overrides the timeout value set in the parent job. Streaming jobs do not have a timeout. The default for non-streaming jobs is 2,880 minutes (48 hours).
How do you execute a Glue job?
How To Define and Run a Job in AWS GlueCreate a Python script file (or PySpark)Copy it to Amazon S3.Give the Amazon Glue user access to that S3 bucket.Run the job in AWS Glue.Inspect the logs in Amazon CloudWatch.
Syntax
To declare this entity in your AWS CloudFormation template, use the following syntax:
Return values
When you pass the logical ID of this resource to the intrinsic Ref function, Ref returns the job name.
Faster data integration
Different groups across your organization can use AWS Glue to work together on data integration tasks, including extraction, cleaning, normalization, combining, loading, and running scalable ETL workflows. This way, you reduce the time it takes to analyze your data and put it to use from months to minutes.
Automate your data integration at scale
AWS Glue automates much of the effort required for data integration. AWS Glue crawls your data sources, identifies data formats, and suggests schemas to store your data. It automatically generates the code to run your data transformations and loading processes.
No servers to manage
AWS Glue runs in a serverless environment. There is no infrastructure to manage, and AWS Glue provisions, configures, and scales the resources required to run your data integration jobs. You pay only for the resources your jobs use while running.
Build event-driven ETL (extract, transform, and load) pipelines
AWS Glue can run your ETL jobs as new data arrives. For example, you can use an AWS Lambda function to trigger your ETL jobs to run as soon as new data becomes available in Amazon S3. You can also register this new dataset in the AWS Glue Data Catalog as part of your ETL jobs.
Create a unified catalog to find data across multiple data stores
You can use the AWS Glue Data Catalog to quickly discover and search across multiple AWS data sets without moving the data. Once the data is cataloged, it is immediately available for search and query using Amazon Athena, Amazon EMR, and Amazon Redshift Spectrum.
Create, run, and monitor ETL jobs without coding
AWS Glue Studio makes it easy to visually create, run, and monitor AWS Glue ETL jobs. You can compose ETL jobs that move and transform data using a drag-and-drop editor, and AWS Glue automatically generates the code. You can then use the AWS Glue Studio job run dashboard to monitor ETL execution and ensure that your jobs are operating as intended.
Explore data with self-service visual data preparation
AWS Glue DataBrew enables you to explore and experiment with data directly from your data lake, data warehouses, and databases, including Amazon S3, Amazon Redshift, AWS Lake Formation, Amazon Aurora, and Amazon RDS.