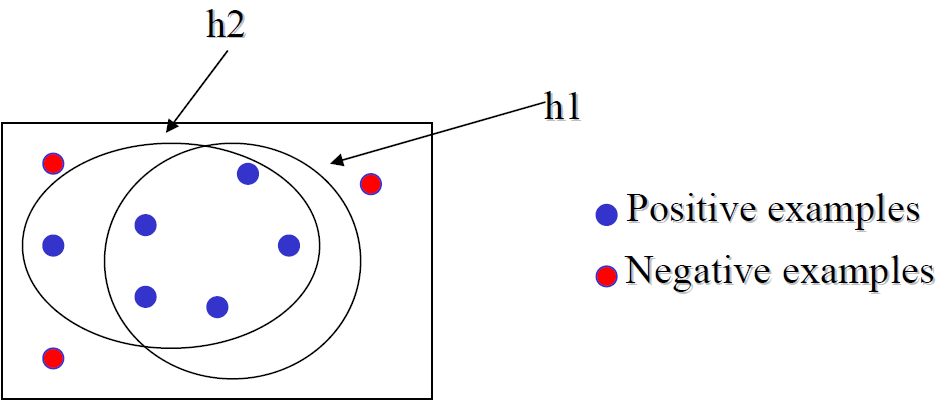
The Candidate Elimination Algorithm computes the version space containing all hypotheses from H that are consistent with an observed sequence of training examples. It begins by initializing the version space to the set of all hypotheses in H, that is, by initializing the G boundary set to contain the most general hypotheses in H
What is candidate elimination learning algorithm?
Candidate Elimination Learning Algorithm is a method for learning concepts from data that is supervised. In this blog, we’ll explain the candidate elimination learning algorithm with examples. Given a hypothesis space H and a collection E of instances, the candidate elimination procedure develops the version space progressively.
What is the difference between find-s and candidate elimination?
1. Introduction to Candidate Elimination Algorithm Candidate elimination algorithm overcomes the problem that is imposed by the Find-S algorithm. Find-S algorithm only considers positive training examples while Candidate elimination algorithm considers positive and negative both training examples.
How do you initialize candidate elimination?
Initializing both specific and general hypotheses. When the first training example is supplied (in this case, a positive example), the Candidate Elimination method evaluates the S boundary and determines that it is too specific, failing to cover the positive example.

Where is candidate elimination algorithm used?
Candidate Elimination Algorithm is used to find the set of consistent hypothesis, that is Version spsce.
Is candidate elimination algorithm supervised or unsupervised?
Introduction. In this tutorial, we'll explain the Candidate Elimination Algorithm (CEA), which is a supervised technique for learning concepts from data.
How is candidate elimination algorithm different from find-s algorithm?
Unlike Find-S(#Link to Find-S) algorithm, the Candidate Elimination algorithm considers not just positive but negative samples as well. It relies on the concept of version space. At the end of the algorithm, we get both specific and general hypotheses as our final solution.
What is inductive bias and how it is used for candidate elimination algorithm?
The inductive bias (also known as learning bias) of a learning algorithm is the set of assumptions that the learner uses to predict outputs given inputs that it has not encountered.
Does candidate elimination algorithm have search bias?
The candidate elimination algorithm is sometimes said to be an unbiased learning algorithm because the learning algorithm does not impose any bias beyond the language bias involved in choosing H.
What is supervised and unsupervised learning explain with example?
Supervised learning algorithms are trained using labeled data. Unsupervised learning algorithms are trained using unlabeled data. Supervised learning model takes direct feedback to check if it is predicting correct output or not. Unsupervised learning model does not take any feedback.
Why do we use find-s algorithm?
The find-S algorithm is a basic concept learning algorithm in machine learning. The find-S algorithm finds the most specific hypothesis that fits all the positive examples. We have to note here that the algorithm considers only those positive training example.
What are the properties of find-s algorithm?
The Find-S algorithm only considers the positive examples and eliminates negative examples. For each positive example, the algorithm checks for each attribute in the example. If the attribute value is the same as the hypothesis value, the algorithm moves on without any changes.
What is the output of find-s algorithm?
3. Find-S is guaranteed to output the most specific hypothesis h that best fits positive training examples. The hypothesis h returned by Find-S will also fit negative examples as long as training examples are correct.
What is inductive bias?
Definition. In machine learning, the term inductive bias refers to a set of (explicit or implicit) assumptions made by a learning algorithm in order to perform induction, that is, to generalize a finite set of observation (training data) into a general model of the domain.
Why is inductive bias important for a machine learning algorithm?
Generally, every building block and every belief that we make about the data is a form of inductive bias. Inductive biases play an important role in the ability of machine learning models to generalize to the unseen data. A strong inductive bias can lead our model to converge to the global optimum.
What is the inductive bias of decision tree?
Inductive Bias in Decision Tree Learning Shorter trees are preferred over longer trees. Trees that place high information gain attributes close to the root are preferred over those that do not.
What is ID3 algorithm in machine learning?
In decision tree learning, ID3 (Iterative Dichotomiser 3) is an algorithm invented by Ross Quinlan used to generate a decision tree from a dataset. ID3 is the precursor to the C4. 5 algorithm, and is typically used in the machine learning and natural language processing domains.
Will candidate elimination algorithm converge to correct hypothesis?
Candidate Elimination Algorithm Issues Will it converge to the correct hypothesis? Yes, if (1) the training examples are error free and (2) the correct hypothesis can be represented by a conjunction of attributes.
What is decision tree algorithm in machine learning?
Share. Introduction Decision Trees are a type of Supervised Machine Learning (that is you explain what the input is and what the corresponding output is in the training data) where the data is continuously split according to a certain parameter.
What are the limitations of the find s algorithm that are handled by the candidate elimination algorithm?
Limitations of Find-S Algorithm There is no way to determine if the hypothesis is consistent throughout the data. Inconsistent training sets can actually mislead the Find-S algorithm, since it ignores the negative examples.
What is the third example in CEA?
The third example in our data () is negative, so we execute the else-branch in the main loop of CEA. Since is not inconsistent with the object, we don’t change it, so we’ll have . Inspecting , we see that is too general and remove it from the boundary. Next, we see that there are six minimal specializations of the removed hypothesis that are consistent with the example:
What is CEA in math?
In this tutorial, we’ll explain the Candidate Elimination Algorithm (CEA), which is a supervised technique for learning concepts from data. We’ll work out a complete example of CEA step by step and discuss the algorithm from various aspects.
Does CEA change the boundary?
Since the only hypothesis in , , is consistent with the object , CEA doesn’t change the general boundary in the first iteration, so it stays the same: .
What is candidate elimination algorithm?
The candidate-Elimination algorithm computes the version space containing all (and only those) hypotheses from H that are consistent with an observed sequence of training examples.
What is the difference between positive and negative training examples?
In case of positive training examples, it moves from top to bottom (Specific hypothesis to General Hypothesis) and in the case of negative training examples it moves from bottom to top (general hypothesis to specific hypothesis).
Does the candidate elimination algorithm have to be specified to fit a negative training example?
In this case, candidate elimination algorithm checks G boundary and find that it is overly generalized and it fails to cover the negative example. Therefore G boundary must be specified to fit this negative training example.
Candidate Elimination Algorithm in Machine Learning
Candidate Elimination Algorithm is used to find the set of consistent hypothesis, that is Version spsce.
Summary
This tutorial discusses the Candidate Elimination Algorithm to find the set of consistent hypotheses in Machine Learning. If you like the tutorial share with your friends. Like the Facebook page for regular updates and YouTube channel for video tutorials.
How to do candidate elimination algorithm?from geeksforgeeks.org
ML – Candidate Elimination Algorithm 1 You can consider this as an extended form of Find-S algorithm. 2 Consider both positive and negative examples. 3 Actually, positive examples are used here as Find-S algorithm (Basically they are generalizing from the specification). 4 While the negative example is specified from generalize form.
What is a good approach to allow CEA to query the user for a labeled object to process next?from baeldung.com
A good approach is to allow CEA to query the user for a labeled object to process next. Since CEA can inspect its version space, it can ask for an object whose processing would halve the space’s size.
What is the inductive bias?from baeldung.com
That restriction biases the search towards a specific type of hypothesis and is therefore called the inductive bias. We can describe bias as a set of assumptions that allow deductive reasoning. That means that we can prove that the version spaces output correct labels. Essentially, we regard the labels as theorems and the training data, the object to classify, and the bias as the input to a theorem prover.
What is the third example in CEA?from baeldung.com
The third example in our data () is negative, so we execute the else-branch in the main loop of CEA. Since is not inconsistent with the object, we don’t change it, so we’ll have . Inspecting , we see that is too general and remove it from the boundary. Next, we see that there are six minimal specializations of the removed hypothesis that are consistent with the example:
Does CEA change the boundary?from baeldung.com
Since the only hypothesis in , , is consistent with the object , CEA doesn’t change the general boundary in the first iteration, so it stays the same: .

Introduction

Concept Learning
- A concept is a well-defined collection of objects. For example, the concept “a bird” encompasses all the animals that are birds and includes no animal that isn’t a bird. Each concept has a definition that fully describes all the concept’s members and applies to no objects that belong to other concepts. Therefore, we can say that a concept is a boolean function defined over a set of all po…
Example
- Let’s say that we have the weather data on the days our friend Aldo enjoys (or doesn’t enjoy) his favorite water sport: We want a boolean function that would be for all the examples for which. Each boolean function defined over the space of the tuples of is a candidate hypothesis for our target concept “days when Aldo enjoys his favorite water sport”. Since that’s an infinite space to …
The Candidate Elimination Algorithm
- There may be multiple hypotheses that fully capture the positive objects in our data. But, we’re interested in those also consistent with the negative ones. All the functions consistent with positive and negative objects (which means they classify them correctly) constitute the version space of the target concept. The Candidate Elimination Algorithm (CEA) relies on a partial orderi…
Convergence of Cea
- If contains a hypothesis that correctly classifies all the training objects and the data have no errors, then the version space CEA finds will include that hypothesis. If the output version space contains only a single hypothesis , then we say that CEA converges to . However, if the data contain errors or doesn’t contain any hypothesis consistent with the whole dataset, then CEA wil…
Speeding Up Cea
- The order in which CEA processes the training objects doesn’t affect the resulting version space, but it affects the convergence speed. CEA attains the maximal speed when it halves the size of the current version space in each iteration, as that reduces the search space the most. A good approach is to allow CEA to query the user for a labeled object to process next. Since CEA can in…
Partially Learned Concepts
- If the version space contains multiple hypotheses, then we say that CEA has partially learned the target concept. In that case, we must decide how to classify new objects. One strategy could be to classify a new object only if all the hypotheses in agree on its label. If there’s no consensus, we don’t classify . An efficient way of doing so is to consider the space’s boundaries and . If all the h…
Unrestricted Hypothesis Spaces
- If contains no hypothesis consistent with the dataset, then CEA will return an empty version space. To prevent this from happening, we can choose a representation that makes any concept a member of . If is the space the objects come from, then should represent every possible subset of . In other words, should correspond to the power set of . One way to do that is to allow complex …
from Inductive Bias to Deductive Reasoning
- That restriction biases the search towards a specific type of hypothesis and is therefore called the inductive bias. We can describe bias as a set of assumptions that allow deductive reasoning.That means that we can prove that the version spaces output correct labels. Essentially, we regard the labels as theorems and the training data, the object to classify, and the bias as the input to a the…
Conclusion
- In this article, we explained the Candidate Elimination Algorithm (CEA). We showed how to use it for concept learning and also discussed its convergence, speed, and inductive bias.