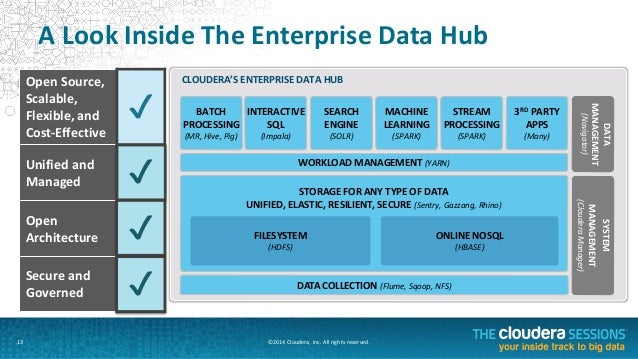
What is flume in big data? Flume is a distributed, reliable, and available service for efficiently collecting, aggregating, and moving large amounts of log data. It has a simple and flexible architecture based on streaming data flows.
What is flume?
Jun 19, 2020 · Apache Flume is a system used for moving massive quantities of streaming data into HDFS. Collecting log data present in log files from web servers and aggregating it in HDFS …
What is the purpose of flume in Hadoop?
Apache Flume is a tool/service/data ingestion mechanism for collecting aggregating and transporting large amounts of streaming data such as log files, events (etc...) from various …
How Apache Flume helps in data ingestion?
Sep 11, 2021 · Flume is a distributed, reliable, and available service for efficiently collecting, aggregating, and moving large amounts of log data. It has a simple and flexible architecture …
What are the biggest issues with flume?
Apache Flume is a open source of data collection for moving the data from source to destination. flume is tool used collect aggregate and transports large amount of streaming data like log …
Why is Flume used in Hadoop?
What Flume is and how it works?
What is the use of Flume tool?
What are the 3 main components of a Flume data flow?
- Source. ...
- Channel. ...
- Sink. ...
- Interceptors. ...
- Channel Selectors. ...
- Sink Processors.
What are the features of Flume?

- Open-source. Apache Flume is an open-source distributed system. ...
- Data flow. Apache Flume allows its users to build multi-hop, fan-in, and fan-out flows. ...
- Reliability. ...
- Recoverability. ...
- Steady flow. ...
- Latency. ...
- Ease of use. ...
- Reliable message delivery.
What is spark and Flume?
What is HBase in big data?
What is Flume source?
Which tool is used for data ingestion in HDFS?
What are the activities Flume can perform?
...
Answer: Configuration file is the heart of the Apache Flume's agents.
- Every Source must have at least one channel.
- Moreover, every Sink must have only one channel.
- Every component must have a specific type.
Can Flume distribute data to multiple destinations?
What is Flume source channel and sink?
What is a flume?
Flume is used to move the log data generated by application servers into HDFS at a higher speed.
What is flume routing?
Flume provides the feature of contextual routing. The transactions in Flume are channel-based where two transactions (one sender and one receiver) are maintained for each message. It guarantees reliable message delivery. Flume is reliable, fault tolerant, scalable, manageable, and customizable.
Can Flume be used with Hadoop?
Using Flume, we can get the data from multiple servers immediately into Hadoop.
What is yarn in Hadoop?
YARN organizes information ingest from Apache Flume and different administrations that convey crude data into an Enterprise Hadoop cluster.
What is Apache Flume?
Apache Flume is an appropriated, reliable, and accessible service for productively gathering, conglomerating, and moving a lot of streaming data information into the Hadoop Distributed File System (HDFS). It has a very straightforward and adaptable design based on data streams inflow and is vigorous and error resistant with tunable unwavering quality systems for failover and recuperation scenarios.
What is an event in Flume?
Event: A byte payload with discretionary string headers that represent a unit of data that Flume can transport from its point of origin to its ultimate destination
What is no data replication?
No Data Replication- The framework of Flume at no time support for data replication.
What is data storage?
Data storage - Data functioning or flowing through whichever of the core or centralized stores can be easily stored using the great Apache Flume.
What is source in Avro?
Source: An interface execution system that can expend occasions conveyed to it through a particular instrument. For instance, an Avro source is a source usage that can be utilized to get Avro events from customers or different operators in the stream. At the point when a source gets an event, it hands it over to at least one of the channels.
What is steady data flow?
Steady Data Flow - Flume provides a steady flow of data by mediating the writing time and the data delivery time.
What is Flume?
Apache Flume is a tool/service/data ingestion mechanism for collecting aggregating and transporting large amounts of streaming data such as log files, events (etc...) from various sources to a centralized data store.
Flume Agent
Flume is a framework which is used to move log data into HDFS. Generally events and log data are generated by the log servers and these servers have Flume agents running on them. These agents receive the data from the data generators.
Multi-hop Flow
Within Flume, there can be multiple agents and before reaching the final destination, an event may travel through more than one agent. This is known as multi-hop flow.
Fan-out Flow
The dataflow from one source to multiple channels is known as fan-out flow. It is of two types −
Fan-in Flow
The data flow in which the data will be transferred from many sources to one channel is known as fan-in flow.
What is Flume 1.9.0?
Version 1.9.0 is the eleventh Flume release as an Apache top-level project.
What is Flume service?
Flume is a distributed, reliable, and available service for efficiently collecting, aggregating, and moving large amounts of log data. It has a simple and flexible architecture based on streaming data flows. It is robust and fault tolerant with tunable reliability mechanisms and many failover and recovery mechanisms. It uses a simple extensible data model that allows for online analytic application.
How many patches were made since 1.8.0?
Several months of active development went into this release: about 70 patches were committed since 1.8.0, representing many features, enhancements, and bug fixes. While the full change log can be found on the 1.9.0 release page (link below), here are a few new feature highlights:
What is configuration filter?
Configuration Filters to provide a way to inject sensitive information like passwords into the configuration
Is Flume 1.3.1 backwards compatible?
Flume 1.3.1 has been put through many stress and regression tests, is stable, production-ready software, and is backwards-compatible with Flume 1.3.0 and Flume 1.2.0. Apache Flume 1.3.1 is a maintainance release for the 1.3.0 release, and includes several bug fixes and performance enhancements.
Where to download Flume?
This release can be downloaded from the Flume download page at: http://flume.apache.org/download.html
How to insert data into Hadoop?
Hadoop File System Shell provides commands to insert data into Hadoop and read from it. You can insert data into Hadoop using the put command as shown below.
What is Apache Flume?
Apache Flume is a tool/service/data ingestion mechanism for collecting aggregating and transporting large amounts of streaming data such as log data, events (etc...) from various webserves to a centralized data store.
What happens to a file in HDFS?
In HDFS, the file exists as a directory entry and the length of the file will be considered as zero till it is closed. For example, if a source is writing data into HDFS and the network was interrupted in the middle of the operation (without closing the file), then the data written in the file will be lost.
What is a log file?
Log file − In general, a log file is a file that lists events/actions that occur in an operating system. For example, web servers list every request made to the server in the log files.
How to transfer data into HDFS?
The traditional method of transferring data into the HDFS system is to use the put command. Let us see how to use the put command.
What is big data?
Big Data, as we know, is a collection of large datasets that cannot be processed using traditional computing techniques. Big Data, when analyzed, gives valuable results. Hadoop is an open-source framework that allows to store and process Big Data in a distributed environment across clusters of computers using simple programming models.
What is Scribe used for?
Scribe is an immensely popular tool that is used to aggregate and stream log data. It is designed to scale to a very large number of nodes and be robust to network and node failures.