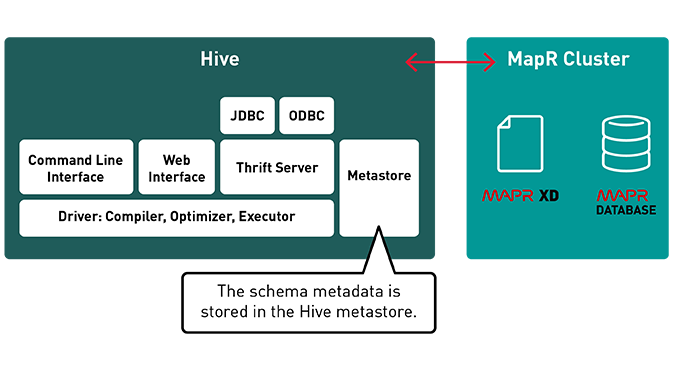
What is Apache Hive?
Apache Hive is a distributed, fault-tolerant data warehouse system that enables analytics at a massive scale. A data warehouse provides a central store of information that can easily be analyzed to make informed, data driven decisions.
What is the difference between a data warehouse and Hive?
A data warehouse provides a central store of information that can easily be analyzed to make informed, data driven decisions. Hive allows users to read, write, and manage petabytes of data using SQL. Hive is built on top of Apache Hadoop, which is an open-source framework used to efficiently store and process large datasets.
What is a hive in Hadoop?
Hive is an open-source, data warehouse, and analytic package that runs on top of a Hadoop cluster. Hive scripts use an SQL-like language called Hive QL (query language) that abstracts programming models and supports typical data warehouse interactions.
What is Apache Hive in Amazon EMR?
AWS Documentation » Amazon EMR Documentation » Amazon EMR Release Guide » Apache Hive. Hive is an open-source, data warehouse, and analytic package that runs on top of a Hadoop cluster. Hive scripts use an SQL-like language called Hive QL (query language) that abstracts programming models and supports typical data warehouse interactions.

What is Hive in Amazon?
Apache Hive is an open-source, distributed, fault-tolerant system that provides data warehouse-like query capabilities. It enables users to read, write, and manage petabytes of data using a SQL-like interface.
How do I run AWS Hive?
To run Hive commands interactivelyConnect to the master node. For more information, see Connect to the master node using SSH in the Amazon EMR Management Guide.At the command prompt for the current master node, type hive . ... Enter a Hive command that maps a table in the Hive application to the data in DynamoDB.
What is Hive in Devops?
Hive is the leading provider of cloud-based AI solutions for content understanding, trusted by the world's largest, fastest growing, and most innovative organizations. The company empowers developers with a portfolio of best-in-class, pre-trained AI models, serving billions of customer API requests every month.
What is Hive vs spark?
Hive and Spark are both immensely popular tools in the big data world. Hive is the best option for performing data analytics on large volumes of data using SQLs. Spark, on the other hand, is the best option for running big data analytics. It provides a faster, more modern alternative to MapReduce.
What is the use of Hive?
Hive allows users to read, write, and manage petabytes of data using SQL. Hive is built on top of Apache Hadoop, which is an open-source framework used to efficiently store and process large datasets. As a result, Hive is closely integrated with Hadoop, and is designed to work quickly on petabytes of data.
What is Hive with example?
Hive is a data warehouse system that is used to query and analyze large datasets stored in the HDFS. Hive uses a query language called HiveQL, which is similar to SQL.
Is Hive an ETL tool?
Hive is a powerful tool for ETL, data warehousing for Hadoop, and a database for Hadoop.
Is Hive same as SQL?
Key differences between Hive and SQL: Architecture: Hive is a data warehouse project for data analysis; SQL is a programming language. (However, Hive performs data analysis via a programming language called HiveQL, similar to SQL.) Set-up: Hive is a data warehouse built on the open-source software program Hadoop.
Is Hive a database?
Apache Hive is an open source data warehouse software for reading, writing and managing large data set files that are stored directly in either the Apache Hadoop Distributed File System (HDFS) or other data storage systems such as Apache HBase.
Is Hadoop the same as Hive?
Key Differences between Hadoop and Hive Hadoop is a framework to process/query the Big data while Hive is an SQL Based tool that builds over Hadoop to process the data. 2. Hive process/query all the data using HQL (Hive Query Language) it's SQL-Like Language while Hadoop can understand Map Reduce only.
Do we need Hive for Spark?
Yes, we can run spark sql queries on spark without installing hive, by default hive uses mapred as an execution engine, we can configure hive to use spark or tez as an execution engine to execute our queries much faster. Hive on spark hive uses hive metastore to run hive queries.
Why Spark is faster than Hive?
Speed: – The operations in Hive are slower than Apache Spark in terms of memory and disk processing as Hive runs on top of Hadoop. Read/Write operations: – The number of read/write operations in Hive are greater than in Apache Spark. This is because Spark performs its intermediate operations in memory itself.
How do I install and run the Hive?
The following simple steps are executed for Hive installation:Step 1: Verifying JAVA Installation. ... Step 2: Verifying Hadoop Installation. ... Step 4: Installing Hive. ... Step 5: Configuring Hive. ... Step 6: Downloading and Installing Apache Derby. ... Step 7: Configuring Metastore of Hive. ... Step 8: Verifying Hive Installation.
How do you know if Hive is running?
Check the status of the Hive services using the command: status.sh hive.If any one service did not start, you can manually start it using the following command:
How do I start the Hive command line?
Steps:Login to the web console using your cloudxlab username and password.Launch Hive by typing hive in the web console.To see the list of all databases type command: show databases;To see the list of all tables type command: show tables;To create your own database run below commands.More items...
What is Hive command?
Hive command is a data warehouse infrastructure tool that sits on top Hadoop to summarize Big data. It processes structured data. It makes data querying and analyzing easier. Hive command is also called as “schema on reading;” It doesn't verify data when it is loaded, verification happens only when a query is issued.
High availability
You can launch an EMR cluster with multiple master nodes to support high availability for Apache Hive. Amazon EMR automatically fails over to a standby master node if the primary master node fails or if critical processes, like Resource Manager or Name Node, crash. This means that you can run Apache Hive on EMR clusters without interruption.
Managed scaling
Amazon EMR allows you to define EMR Managed Scaling for Apache Hive clusters to help you optimize your resource usage. With EMR Managed Scaling, you can automatically resize your cluster for best performance at the lowest possible cost.
Fast performance
Amazon EMR 6.0.0 adds support for Hive LLAP, providing an average performance speedup of 2x over EMR 5.29. You can learn more here. You can now use S3 Select with Hive on Amazon EMR to improve performance.
Flexible metastore options
With Amazon EMR, you have the option to leave the metastore as local or externalize it. EMR provides integration with the AWS Glue Data Catalog and AWS Lake Formation, so that EMR can pull information directly from Glue or Lake Formation to populate the metastore.
Customer success
Airbnb connects people with places to stay and things to do around the world with 2.9 million hosts listed, supporting 800k nightly stays. Airbnb uses Amazon EMR to run Apache Hive on a S3 data lake. Running Hive on the EMR clusters enables Airbnb analysts to perform ad hoc SQL queries on data stored in the S3 data lake.
What is Hive in Hadoop?
No one can better explain what Hive in Hadoop is than the creators of Hive themselves: "The Apache Hive™ data warehouse software facilitates reading, writing, and managing large datasets residing in distributed storage using SQL. The structure can be projected onto data already in storage."
What is the difference between hive and SQL?
The most significant difference between the Hive Query Language (HQL) and SQL is that Hive executes queries on Hadoop's infrastructure instead of on a traditional database
How many modes does hive have?
Depending on the size of Hadoop data nodes, Hive can operate in two different modes:
What language does Hive use?
Hive uses an SQL-inspired language, sparing the user from dealing with the complexity of MapReduce programming. It makes learning more accessible by utilizing familiar concepts found in relational databases, such as columns, tables, rows, and schema, etc.
What is the certification for Big Data?
To that end, many companies look for candidates who have certification in the appropriate field. Simplilearn's Big Data Hadoop Certification Training Course is designed to give you an in-depth knowledge of the Big Data framework using Hadoop and Spark. It prepares you for Cloudera's CCA175 Hadoop Certification Exam.
How many hours of self-paced training?
Whether you choose self-paced learning, the Blended Learning program, or a corporate training solution, the course offers a wealth of benefits. You get 48 hours of instructor-led training, 10 hours of self-paced video training, four real-life industry projects using Hadoop, Hive and Big data stack, and training on Yarn, MapReduce, Pig, Hive, HBase, and Apache Spark. But the benefits don't end there, as you will also enjoy lifetime access to self-paced learning.
What is the driver in a query?
The driver interacts with the query compiler to retrieve the plan, which consists of the query execution process and metadata information. The driver also parses the query to check syntax and requirements.
Differences between Apache Hive on Amazon EMR and Apache Hive
This section describes the differences between Hive on Amazon EMR and the default versions of Hive available at http://svn.apache.org/viewvc/hive/branches/.
Differences in Hive between Amazon EMR release version 4.x and 5.x
This section covers differences to consider before you migrate a Hive implementation from Hive version 1.0.0 on Amazon EMR release 4.x to Hive 2.x on Amazon EMR release 5.x.
Additional features of Hive on Amazon EMR
Amazon EMR extends Hive with new features that support Hive integration with other AWS services, such as the ability to read from and write to Amazon Simple Storage Service (Amazon S3) and DynamoDB.
What is Hive?
Hive is an ETL and Data warehousing tool developed on top of Hadoop Distributed File System (HDFS). Hive makes job easy for performing operations like
How does hive communicate with Hadoop?
Hive Continuously in contact with Hadoop file system and its daemons via Execution engine. The dotted arrow in the Job flow diagram shows the Execution engine communication with Hadoop daemons.
What is the difference between HQL and SQL?
The major difference between HQL and SQL is that Hive query executes on Hadoop’s infrastructure rather than the traditional database .
What is client interaction in hive?
Client interactions with Hive can be performed through Hive Services. If the client wants to perform any query related operations in Hive, it has to communicate through Hive Services.
What services does hive use?
Hive services such as Meta store, File system, and Job Client in turn communicates with Hive storage and performs the following actions
What is a driver in hive?
Driver present in the Hive services represents the main driver, and it communicates all type of JDBC, ODBC, and other client specific applications. Driver will process those requests from different applications to meta store and field systems for further processing.
What does "Read many once" mean in hive?
Also, Hive supports “ READ Many WRITE Once ” pattern. Which means that after inserting table we can update the table in the latest Hive versions.
What is Cloudera Hive?
In this blog, we would discuss how to install Cloudera Hive on Linux (RHEL) EC2 instance. Apache Hive is a data warehouse tool built on top of Apache Hadoop for providing data query and analysis. Hive provides a SQL_Like Interface to query data stored in various databases and filesystem that integrate with Hadoop. It enables…
What is Apache Hive?
Apache Hive is a data warehouse tool built on top of Apache Hadoop for providing data query and analysis. Hive provides a SQL_Like Interface to query data stored in various databases and filesystem that integrate with Hadoop. It enables reading, writing and managing large datasets in distributed storage. Hive queries are converted to a series of jobs that execute on a Hadoop cluster through MapReduce or Apache Spark. It also provides easy, familiar batch processing for Apache Hadoop.