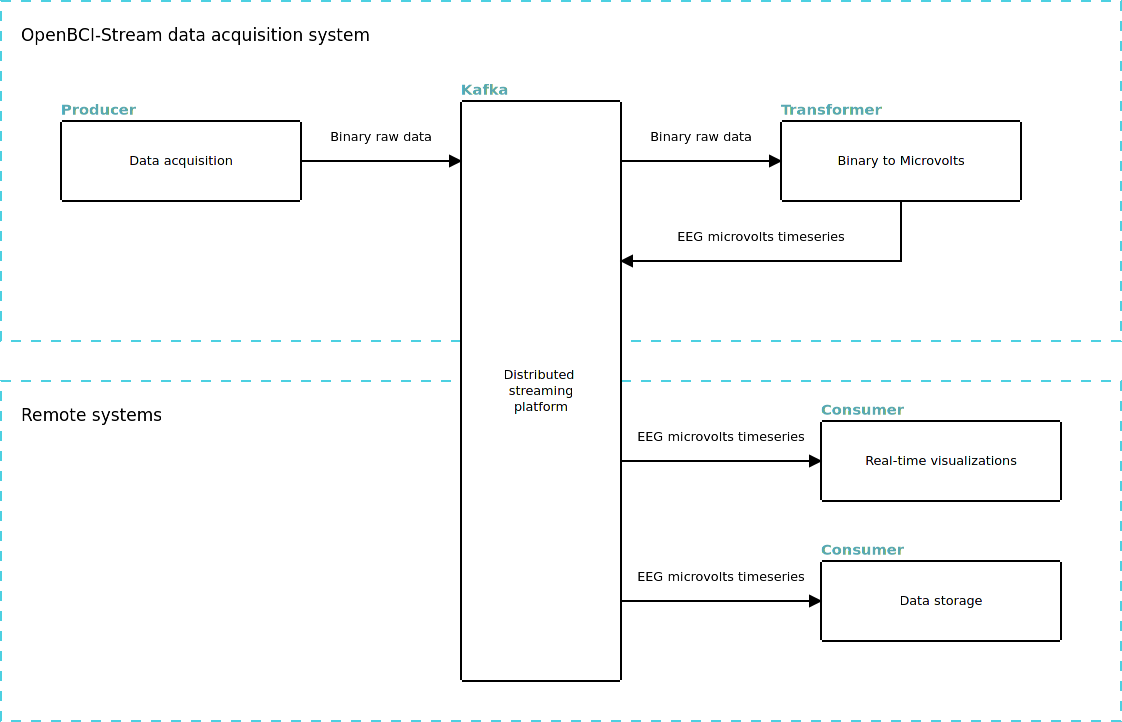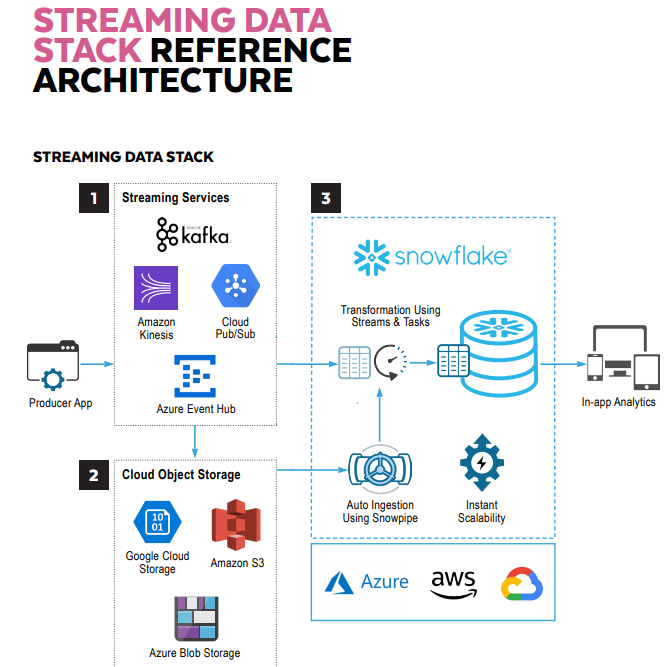
When to use Kafka Streams?
To complete this guide, you need:
- Roughly 30 minutes
- An IDE
- JDK 11+ installed with JAVA_HOME configured appropriately
- Apache Maven 3.8.1+
- Docker and Docker Compose
- Optionally the Quarkus CLI if you want to use it
- Optionally Mandrel or GraalVM installed and configured appropriately if you want to build a native executable (or Docker if you use a native container build)
How to read streaming data in XML format from Kafka?
This post explored the three most common options for integration between Kafka and XML:
- XML integration with a 3rd party middleware
- Kafka Connect connector for integration with XML files
- Kafka Connect SMT to embed the transformation into ANY other Kafka Connect source or sink connector to transform XML messages on the flight
How to process streams with Kafka Streams?
- Line 2 - We are setting an application ID. ...
- Line 3 - We are pointing where our Kafka is located.
- Line 4 - 5 - We are setting default serializers. ...
- Line 7 - Kafka Streams requires the source topic to be created up-front, otherwise you will get an exception. ...
- Line 9 - Get a StreamBuilder instance
- Line 10 - Start creating our first stream! ...
What is Amazon managed streaming for Kafka?
Kafka provides three main functions to its users:
- Publish and subscribe to streams of records
- Effectively store streams of records in the order in which records were generated
- Process streams of records in real time
What is difference between Kafka and Kafka Streams?
Every topic in Kafka is split into one or more partitions. Kafka partitions data for storing, transporting, and replicating it. Kafka Streams partitions data for processing it. In both cases, this partitioning enables elasticity, scalability, high performance, and fault tolerance.
Can Kafka be used for data streaming?
Kafka is used for building real-time streaming data pipelines that reliably get data between many independent systems or applications. It allows: Publishing and subscribing to streams of records. Storing streams of records in a fault-tolerant, durable way.
Why do we use Kafka Streams?
Kafka Streams greatly simplifies the stream processing from topics. Built on top of Kafka client libraries, it provides data parallelism, distributed coordination, fault tolerance, and scalability.
What is Kafka stream platform?
Apache Kafka is a popular event streaming platform used to collect, process, and store streaming event data or data that has no discrete beginning or end. Kafka makes possible a new generation of distributed applications capable of scaling to handle billions of streamed events per minute.
What is Kafka in simple words?
Apache Kafka is a distributed publish-subscribe messaging system that receives data from disparate source systems and makes the data available to target systems in real time. Kafka is written in Scala and Java and is often associated with real-time event stream processing for big data.
How Kafka is used in Netflix?
It enables applications to publish or subscribe to data or event streams. It stores data records accurately and is highly fault-tolerant. It is capable of real-time, high-volume data processing. It is able to take in and process trillions of data records per day, without any performance issues.
What is the difference between API and Kafka?
With the API, you can write code to process or transform individual messages, one-by-one, and then publish those modified messages to a new Kafka topic, or to an external system. With Kafka Streams, all your stream processing takes place inside your app, not on the brokers.
What is the difference between Kafka and spark streaming?
Apache Kafka vs Spark: Processing Type Kafka analyses the events as they unfold. As a result, it employs a continuous (event-at-a-time) processing model. Spark, on the other hand, uses a micro-batch processing approach, which divides incoming streams into small batches for processing.
Is Kafka an API?
The Kafka Streams API to implement stream processing applications and microservices. It provides higher-level functions to process event streams, including transformations, stateful operations like aggregations and joins, windowing, processing based on event-time, and more.
What is Kafka and how it works?
Kafka is distributed data infrastructure, which implies that there is some kind of node that can be duplicated across a network such that the collection of all of those nodes functions together as a single Kafka cluster. That node is called a broker.
Is Kafka a database?
Apache Kafka is not just a publisher/subscriber messaging system that sends data from one point to another. It's an event streaming platform. Associating databases with messaging solutions such as Kafka is a bit skewed. But Kafka has database-like features that make it primed to replace databases.
Is Kafka a big data tool?
Kafka can handle huge volumes of data and remains responsive, this makes Kafka the preferred platform when the volume of the data involved is big to huge. It's reliable, stable, flexible, robust, and scales well with numerous consumers.
What is the difference between Kafka and spark streaming?
Apache Kafka vs Spark: Processing Type Kafka analyses the events as they unfold. As a result, it employs a continuous (event-at-a-time) processing model. Spark, on the other hand, uses a micro-batch processing approach, which divides incoming streams into small batches for processing.
Where Kafka is used in real-time?
Most software and product vendors use it these days. Including messages frameworks (e.g., IBM MQ, RabbitMQ), event streaming platforms (e.g., Apache Kafka, Confluent), data warehouse/analytics vendors (e.g., Spark, Snowflake, Elasticsearch), and security / SIEM products (e.g., Splunk).
Can Kafka be used for audio streaming?
The Kafka Streams Quick Start demonstrates how to run your first Java application that uses the Kafka Streams library by showcasing a simple end-to-end data pipeline powered by Kafka. Streaming Audio is a podcast from Confluent, the team that built Kafka.
How much data can Kafka handle?
1 Answer. Show activity on this post. There is no limit in Kafka itself. As data comes in from producers it will be written to disk in file segments, these segments are rotated based on time (log.
What is Apache Kafka?
Apache Kafka is a distributed data store optimized for ingesting and processing streaming data in real-time. Streaming data is data that is continuously generated by thousands of data sources, which typically send the data records in simultaneously.
Why would you use Kafka?
Kafka is used to build real-time streaming data pipelines and real-time streaming applications. A data pipeline reliably processes and moves data from one system to another, and a streaming application is an application that consumes streams of data.
How does Kafka work?
Kafka combines two messaging models, queuing and publish-subscribe, to provide the key benefits of each to consumers. Queuing allows for data processing to be distributed across many consumer instances, making it highly scalable. However, traditional queues aren’t multi-subscriber.
Benefits of Kafka's approach
Kafka’s partitioned log model allows data to be distributed across multiple servers, making it scalable beyond what would fit on a single server.
Dive deep into Kafka's architecture
Kafka remedies the two different models by publishing records to different topics. Each topic has a partitioned log, which is a structured commit log that keeps track of all records in order and appends new ones in real time.
Apache Kafka vs RabbitMQ
RabbitMQ is an open source message broker that uses a messaging queue approach. Queues are spread across a cluster of nodes and optionally replicated, with each message only being delivered to a single consumer.
What is Kafka streaming?
Kafka streaming, which is part of the Kafka ecosystem, provides the ability to do real-time analytics. Kafka can be used to feed fast lane systems (real-time and operational data systems) like Storm, Flink, Spark streaming, and your services and CEP systems. Kafka is also used to stream data for batch data analysis.
What is Kafka communication protocol?
Kafka communication from clients and servers uses a wire protocol over TCP that is versioned and documented. Kafka promises to maintain backward compatibility with older clients, and many languages are supported. There are clients in C#, Java, C, Python, Ruby, and many more languages.
What is Kafka used for?
Kafka is used for real-time streams of data, to collect big data, or to do real time analysis ( or both). Kafka is used with in-memory microservices to provide durability and it can be used to feed events to CEP (complex event streaming systems) and IoT/IFTTT-style automation systems.
How does Kafka work?
Kafka relies heavily on the OS kernel to move data around quickly. It relies on the principals of zero copy. Kafka enables you to batch data records into chunks. These batches of data can be seen end-to-end from producer to file system (Kafka topic log) to the consumer.
What is the purpose of Kafka in Square?
Square uses Kafka as a bus to move all system events to various Square data centers (logs, custom events, metrics, and so on), outputs to Splunk, for Graphite (dashboards), and to implement Esper-like/CEP alerting systems. It's also used by other companies like Spotify, Uber, Tumbler, Goldman Sachs, PayPal, Box, Cisco, CloudFlare, and Netflix.
How long does Kafka keep records?
Kafka clusters retain all published record. If you don’t set a limit, it will keep records until it runs out of disk space. You can set time-based limits (configurable retention period), size-based limits (configurable based on size), or compaction (keeps the latest version of record using key). You can, for example, set a retention policy of three days or two weeks or a month. The records in the topic log are available for consumption until discarded by time, size, or compaction. The consumption speed not impacted by size as Kafka always writes to the end of the topic log.
Why is Kafka so popular?
But none of those characteristics would matter if Kafka was slow. The most important reason Kafka is popular is Kafka’s exceptional performance.
Logs, Brokers, and Topics
At the heart of Kafka is the log, which is simply a file where records are appended. The log is immutable, but you usually can't store an infinite amount of data, so you can configure how long your records live.
Getting Records into and out of Brokers: Producers and Consumers
You put data into Kafka with producers and get it out with consumers: Producers send a produce request with records to the log, and each record, as it arrives, is given a special number called an offset, which is just the logical position of that record in the log.
Connectors
Connectors are an abstraction over producers and consumers. Perhaps you need to export database records to Kafka. You configure a source connector to listen to certain database tables, and as records come in, the connector pulls them out and sends them to Kafka.
Streaming Engine
Now that you are familiar with Kafka's logs, topics, brokers, connectors, and how its producers and consumers work, it's time to move on to its stream processing component. Kafka Streams is an abstraction over producers and consumers that lets you ignore low-level details and focus on processing your Kafka data.
Processing Data: Vanilla Kafka vs. Kafka Streams
As mentioned, processing code written in Kafka Streams is far more concise than the same code would be if written using the low-level Kafka clients. One way to examine their approaches for interacting with the log is to compare their corresponding APIs.
What is the most fundamental part of Kafka?
The most fundamental part of Apache Kafka is the concept of topics. Everybody who has ever used a messaging service should intuitively understand what the topic is. People not familiar with that may think of a topic as the identifier of a data stream.
What is offset in Kafka?
The offset is a sequential id number that uniquely identifies each record within the partition. As I wrote before, Kafka keeps the offset metadata for every consumer, but the consumer may change it to an arbitrary value.
What is Kafka software?
Kafka is an open source software which provides a framework for storing, reading and analysing streaming data. Being open source means that it is essentially free to use and has a large network of users and developers who contribute towards updates, new features and offering support for new users.
What industry uses Kafka?
In fact, according to their website, one out of five Fortune 500 businesses uses Kafka to some extent. One particular niche where Kafka has gained dominance is the travel industry, where its streaming capability makes it ideal for tracking booking details of millions of flights, package holidays and hotel vacancies worldwide.
What companies use Kafka?
Since then, Kafka has become widely used, and it is an integral part of the stack at Spotify, Netflix, Uber, Goldman Sachs, Paypal and CloudFlare , which all use it to process streaming data and understand customer, or system, behaviour. In fact, according to their website, one out of five Fortune 500 businesses uses Kafka to some extent.
Intro to the Kafka Streams API
For an entire course on the basics of Kafka Streams, make sure to visit Confluent Developer.
Basic operations (stateless processing)
When you define a Kafka Streams operation on an event stream or streams, what you’re really defining is a processor topology, a directed acyclic graph (DAG) with processing nodes and edges that represent the flow of the stream.
KTable (stateful processing)
Unlike an event stream (a KStream in Kafka Streams), a table ( KTable) only subscribes to a single topic, updating events by key as they arrive. KTable objects are backed by state stores, which enable you to look up and track these latest values by key. Updates are likely buffered into a cache, which gets flushed by default every 30 seconds.
Serialization
Serialization converts higher-level objects into the ones and zeros that can be sent across the network to brokers or stored in the state stores that Kafka Streams uses; the term also encompasses deserialization, the opposite process.
Joins
In Kafka Streams, records being joined must have the same key: Two events with unrelated keys are unlikely to be related and thus will not be joined. A common scenario is using a join to provide a full information set about a customer—for example, adding customer purchases to customer addresses.
Stateful operations
If you need to use Kafka Streams to count the number of times that a customer has logged into a browser session, or log the total number of items that you have sold in a given timeframe, you’ll need to use state.
Windowing
Windowing in Kafka Streams gives you a snapshot of an aggregation over a given time frame, as opposed to its whole history—allowing you to do time-based analytics. You have several choices of windows.
What is Apache Kafka?
As of 2020, Apache Kafka is one of the most widely adopted message-broker software (used by the likes of Netflix, Uber, Airbnb and LinkedIn) to accomplish these tasks. This blog will give a very brief overview of the concept of stream-processing, streaming data architecture and why Apache Kafka has gained so much momentum.
What are the key strengths of Kafka?
One of the key strength of Kafka is its ability to parallelise partitions in order to increase the overall throughput.
What is Kafka's strength?
One of the key strength of Kafka is its ability to parallelise partitions in order to increase the overall throughput. The information is then made available to consumers which will be using this output in different ways. Image Credit: Wikipedia / Kafka Message Broker.
What is message broker in Kafka?
In Kafka, messages are written on topics which maintains its log and from which consumers can extract the data. Even though message-broker software such as Rabbit MQ and ActiveMQ have been around for years even before Kafka, the log-append structure has allowed for the processing of an insane amount of transactions.
What is stream processing?
Stream-processing is best visualised as a river. In the same way that water flows through a river, so do packages of information in the endless flow of stream-processing. According to AWS, the general definition of streaming data would be “data that is generated continuously by thousands of data sources, which typically send in ...
Why is data streaming important?
Data streaming works particularly well in time-series in order to find underlying patterns over time. It also really shines in the IoT space where different data signals can be constantly collected. Other common uses are found on web interactions, e-commerce, transaction logs, geolocation points and much much more.
What is big data?
The term ‘Big Data’ contains more than just its reference to quantity and volume. Living in the era of readily available information and instantaneous communication, it is not surprising that data architectures have been shifting to be stream-oriented. Real value for companies doesn’t just come from sitting on a gargantuan amount of collected data points, but also from their ability to extract actionable insights as quickly as possible (even in real-time). Processing data at faster rates allows a company to react to changing business conditions in real-time.