How to setup Kafka on Windows?
Setting Up Kafka
- Go to your Kafka config directory. For me its C:\kafka_2.11-0.9.0.0\config
- Edit the file “server.properties.”
- Find and edit the line log.dirs=/tmp/kafka-logs” to “log.dir= C:\kafka_2.11-0.9.0.0\kafka-logs.
- If your ZooKeeper is running on some other machine or cluster you can edit “zookeeper.connect:2181” to your custom IP and port. ...
Where to install Kafka?
Setting up Kafka
- Go to Kafka config directory.
- Edit the file “server.properties”.
- Once this is done, you can find and edit the line where you see: dirs=/tmp/Kafka-logs to “log.dir= C:\kafka_2.11-0.9.0.0\kafka-logs
- If you have your Zookeeper running on some other machine, then you can change this path to “zookeeper.connect:2181” to a customized IP and port id.
How to create Kafka clients?
- In Cloudera Manager, click on Kafka > Instances > Kafka Broker (click on an individual broker) > Configuration. ...
- Set the following property for the Kafka Broker (using your own broker’s fully-qualified hostname) and save the configuration. ...
- Repeat the process for all the other brokers.
How to integrate Oracle and Kafka?
- Name: Enter ApacheKafka.
- Driver List: Select Oracle JDBC Driver.
- Driver: Enter cdata.jdbc.apachekafka.ApacheKafkaDriver
- URL: Enter the JDBC URL containing the connection string. Set BootstrapServers and the Topic properties to specify the address of your Apache Kafka server, as well as the topic you ...
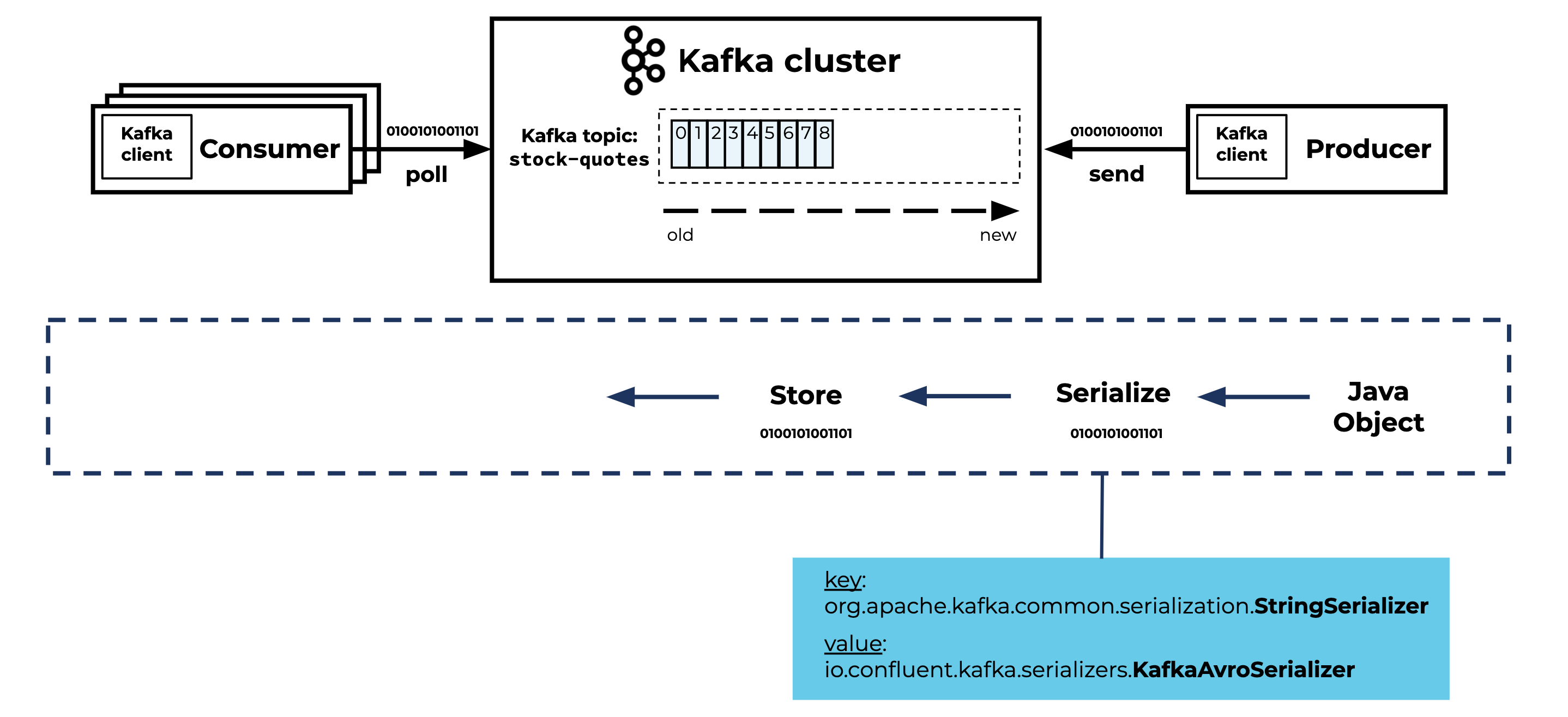
What is Kafka and why it is used?
Kafka is primarily used to build real-time streaming data pipelines and applications that adapt to the data streams. It combines messaging, storage, and stream processing to allow storage and analysis of both historical and real-time data.
Is Kafka a data integration tool?
Apache Kafka is an open-source distributed event streaming platform used by thousands of companies for high-performance data pipelines, streaming analytics, data integration, and mission-critical applications.
What is meant by Kafka?
Apache Kafka is a distributed publish-subscribe messaging system that receives data from disparate source systems and makes the data available to target systems in real time. Kafka is written in Scala and Java and is often associated with real-time event stream processing for big data.
What is Kafka in API?
The Kafka Streams API to implement stream processing applications and microservices. It provides higher-level functions to process event streams, including transformations, stateful operations like aggregations and joins, windowing, processing based on event-time, and more.
Is Kafka an ETL tool?
Companies use Kafka for many applications (real time stream processing, data synchronization, messaging, and more), but one of the most popular applications is ETL pipelines. Kafka is a perfect tool for building data pipelines: it's reliable, scalable, and efficient.
How do you integrate with Kafka?
1:1717:355. Integrating Kafka into Your Environment | Apache ... - YouTubeYouTubeStart of suggested clipEnd of suggested clipCluster. So on the source side it's reading from some external. System producing into the cluster.MoreCluster. So on the source side it's reading from some external. System producing into the cluster. And on the sync side it's consuming from some kafka topic and then writing into that external.
Is Kafka a database?
Apache Kafka is a database. It provides ACID guarantees and is used in hundreds of companies for mission-critical deployments. However, in many cases, Kafka is not competitive to other databases.
How does Kafka work?
Distributed means that Kafka works in a cluster, each node in the cluster is called Broker. Those brokers are just servers executing a copy of apache Kafka. So, basically, Kafka is a set of machines working together to be able to handle and process real-time infinite data.
Why is it called Kafka?
Jay Kreps chose to name the software after the author Franz Kafka because it is "a system optimized for writing", and he liked Kafka's work.
What are the 4 major Kafka APIs?
The Admin API for inspecting and managing Kafka objects like topics and brokers. The Producer API for writing (publishing) to topics. The Consumer API for reading (subscribing to) topics. The Kafka Streams API to provide access for applications and microservices to higher-level stream processing functions.
Is Kafka a REST API?
The Kafka REST Proxy is a RESTful web API that allows your application to send and receive messages using HTTP rather than TCP.
Is Kafka a middleware?
Apache Kafka is a popular open source stream processor / middleware tool that can also be used as a message broker. Kafka provides low end-to-end latency with exceptional durability (persistence).
Which is the best integration tool?
10 Best Data Integration ToolsDell Boomi. ... Talend. ... Pentaho. ... Xplenty. ... Integrately. ... Tray.io. ... Jitterbit. ... SnapLogic. SnapLogic Intelligent Integration Platform, or just SnapLogic for short, is a robust data integration tool with self-service functionality.More items...
What is data integration software?
Data integration software lets enterprises combine, manage, and understand all the data from multiple sources in one single platform. Armed with data integration software, enterprises can make sense of the data, through analytics and statistics, and make better business decisions.
What is data integration with example?
Data integration defined For example, customer data integration involves the extraction of information about each individual customer from disparate business systems such as sales, accounts, and marketing, which is then combined into a single view of the customer to be used for customer service, reporting and analysis.
What are data integration techniques?
Data integration is the process of combining data from different sources to help data managers and executives analyze it and make smarter business decisions. This process involves a person or system locating, retrieving, cleaning, and presenting the data.
What is Apache Kafka?
Apache Kafka is a distributed data store optimized for ingesting and processing streaming data in real-time. Streaming data is data that is continuously generated by thousands of data sources, which typically send the data records in simultaneously.
Benefits of Kafka's approach
Kafka’s partitioned log model allows data to be distributed across multiple servers, making it scalable beyond what would fit on a single server.
Apache Kafka vs RabbitMQ
RabbitMQ is an open source message broker that uses a messaging queue approach. Queues are spread across a cluster of nodes and optionally replicated, with each message only being delivered to a single consumer.
Introduction
Apache Kafka is an event streaming platform used to collect, process, store, and integrate data at scale. It has numerous use cases including distributed streaming, stream processing, data integration, and pub/sub messaging.
Why Kafka? Benefits and Use Cases
Kafka is used by over 100,000 organizations across the world and is backed by a thriving community of professional developers, who are constantly advancing the state of the art in stream processing together.
Kafka Components and Ecosystem
If all you had were brokers managing partitioned, replicated topics with an ever-growing collection of producers and consumers writing and reading events, you would actually have a pretty useful system.
What is a containerized Kafka connector?
Containerized Kafka Connect is a streamlined way to get started, and Confluent maintains a Docker base image you can use. You’ll need to add dependencies for your connectors and other components, which you can fetch from a vetted list at Confluent Hub and either bake into a new image or set it to be installed at runtime if you insist.
How to improve Kafka Connect?
Best practices like creating connectors with PUT and fetching a connector’s associated topic names programmatically can improve the administration of your Kafka Connect instance via REST. Then there are little tricks like employing jq for JSON printing and peco for interactive command output filtering that will make your REST interactions a little more sprightly. The Confluent documentation for the Connect REST API (see also the Confluent Cloud documentation when using fully managed connectors) is the best source for detailed command specifics, but an overview of the basics is a good way to begin your journey with Kafka Connect’s powerful API.
What is Kafka Connect?
Kafka Connect is the pluggable, declarative data integration framework for Kafka. It connects data sinks and sources to Kafka, letting the rest of the ecosystem do what it does so well with topics full of events. As is the case with any piece of infrastructure, there are a few essentials you’ll want to know before you sit down to use it, namely setup and configuration, deployment, error handling, troubleshooting, its API, and monitoring. Confluent Developer recently released a Kafka Connect course covering these topics, and in each of the sections below, I’d like to share something about the content of each lesson in the course.
Can you use Kafka Connect with Confluent?
If fully managed Kafka Connect in Confluent Cloud is a possibility for you, it’s the most straightforward way to accomplish your integration, as you have to manage zero infrastructure yourself. If you do prefer to self-manage Kafka Connect, then permit me to recommend using Confluent Platform. In both cases, you have extensive graphical monitoring tools that let you quickly gain an overview of your data pipelines. From the overview, you might just drill down into a list of consumers for each pipeline, and then one step deeper into their specifics—seeing real-time statistics like topic consumption information and partition offsets. If you aren’t using Confluent Cloud or Confluent Platform, your options for monitoring Kafka Connect lie in JMX metrics and REST, because your Kafka Connect instance itself exposes extensive information.
Is Kafka Connect self managed?
In this video, you’ll see Kafka with self-managed Kafka Connect in action, taking data from a MySQL source via Debezium CDC, into Kafka, and out to Elasticsearch and Neo4j from where some nice visualization is done on the data in near real time.
Is Apache Kafka a good data integration system?
But as much as Kafka does a good job as the central nervous system of your company’s data, there are so many systems that are not Kafka that you still have to talk to. Writing bespoke data integration code for each one of those systems would have you writing the same boilerplate and unextracted framework code over and over again. Which is another way of saying that if the Kafka ecosystem didn’t already have Kafka Connect, we would have to invent it.
Is data integration error prone?
Data integration is inherently error-prone, rely ing as it does on connections between things—even if Connect itself never produced a single error. Stack traces and logs will help you with most problems, but you need to know some basics before you wade in. For example, take a running connector with a failed task: if you start your troubleshooting by inspecting the task’s stack trace, then proceed to your Kafka Connect log—you will quickly get an idea of what is causing your problem. And the recently completed Kafka Improvement Proposals (KIPs) addressing dynamic log configuration in Connect as well as additional context for Connect log messages make the job quite a bit more pleasant.
What is Apache Kafka?
Apache Kafka is an open source, distributed data streaming platform that can publish, subscribe to, store, and process streams of records in real time. It is designed to handle data streams from multiple sources and deliver them to multiple consumers.
What is streaming data, and why does it matter?
Streaming data is the continuous flow of real-time information, often represented as a running log of changes or events that have occurred in a data set.
What are the benefits of a Kafka service?
For all its benefits, Apache Kafka can be challenging to deploy at scale in a hybrid cloud environment. Streaming data services can have more stringent requirements than other data applications.
What Is Kafka, and What Does It Do?
Kafka was originally developed by LinkedIn in 2009 and later outsourced to The Apache Software Foundation in 2011. In a nutshell, Kafka is a high-volume, high-throughput, super scalable, and reliable distributed streaming platform.
Kafka Connectors and How They Work
Kafka provides the opportunity to create connectors through the Connect framework. Let’s see a bit more about what connectors are.
Kafka Connector Options
A plethora of connectors are available. Open source or commercial, there’s a great chance that a connector for the application you want to integrate with exists. Let’s take a look at some of those options.
Kafka Connect Takes the Headache Out of Stream Processing
Kafka is becoming more and more popular and provides top-level stream processing. The Scalyr connector can send log data from an existing Kafka infrastructure to Scalyr. It’s easy to configure, taking advantage of the straightforward process of integrating Kafka with an external system.
Introduction
- Apache Kafkais an event streaming platform used to collect, process, store, and integrate data at scale. It has numerous use cases including distributed streaming, stream processing, data integration, and pub/sub messaging. In order to make complete sense of what Kafka does, we'll delve into what an event streaming platform is and how it works. So ...
Why Kafka? Benefits and Use Cases
- Kafka is used by over 100,000 organizations across the world and is backed by a thriving community of professional developers, who are constantly advancing the state of the art in stream processing together. Due to Kafka's high throughput, fault tolerance, resilience, and scalability, there are numerous use cases across almost every industry - from banking and frau…
Kafka Architecture – Fundamental Concepts
- Kafka Topics
Events have a tendency to proliferate—just think of the events that happened to you this morning—so we’ll need a system for organizing them. Kafka’s most fundamental unit of organization is the topic, which is something like a table in a relational database. As a developer … - Kafka Partitioning
If a topic were constrained to live entirely on one machine, that would place a pretty radical limit on the ability of Kafka to scale. It could manage many topics across many machines—Kafka is a distributed system, after all—but no one topic could ever get too big or aspire to accommodate t…
Kafka Components and Ecosystem
- If all you had were brokers managing partitioned, replicated topics with an ever-growing collection of producers and consumers writing and reading events, you would actually have a pretty useful system. However, the experience of the Kafka community is that certain patterns will emerge that will encourage you and your fellow developers to build the same bits of functionality over and ov…