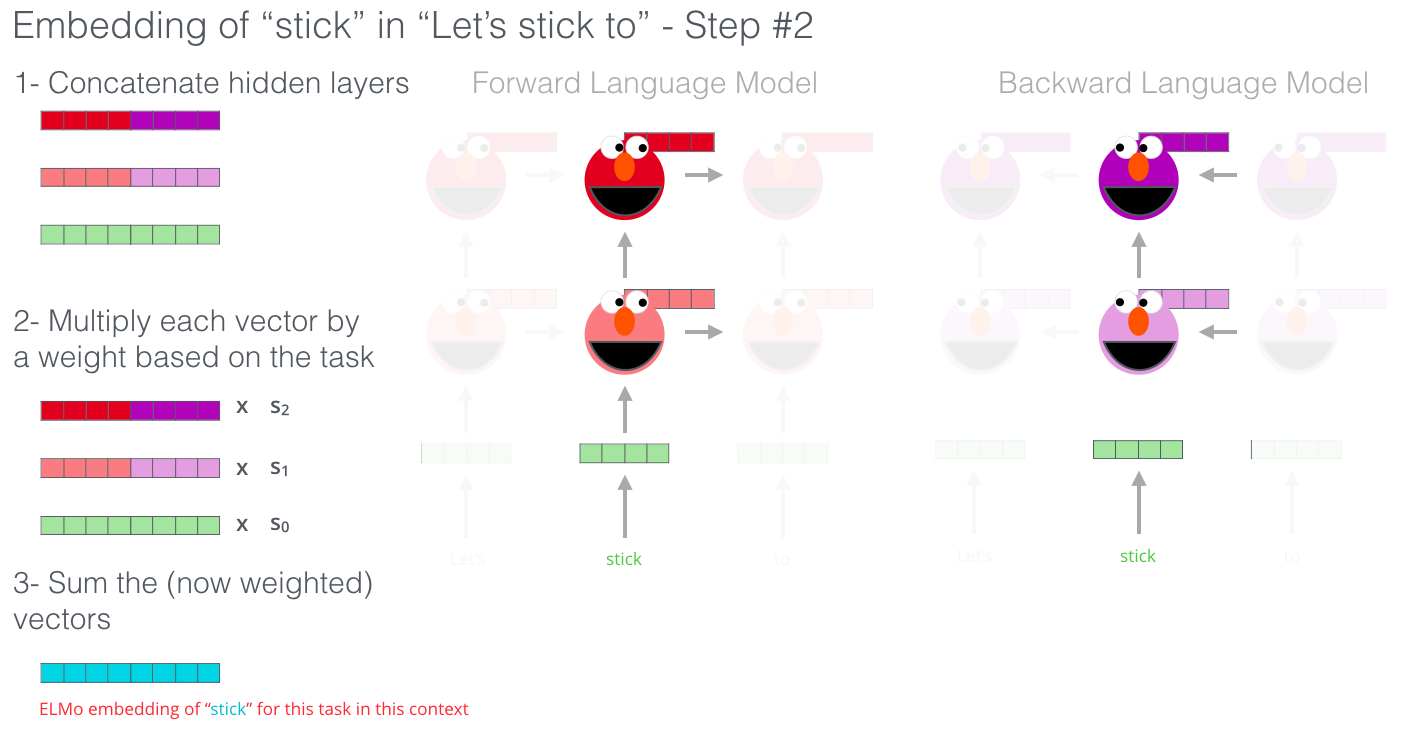
What is LDA and how to use it?
I encourage you to pull it and try it. LDA is used to classify text in a document to a particular topic. It builds a topic per document model and words per topic model, modeled as Dirichlet distributions. Each document is modeled as a multinomial distribution of topics and each topic is modeled as a multinomial distribution of words.
What is LDA and topic modeling?
LDA and Topic Modeling There are many ways to explore the topics of these emails. Latent Dirichlet Allocation (LDA) is one way to do this. LDA is a bag-of-words algorithm that helps us to automatically discover topics that are contained within a set of documents.
Where can I find the code for LDA?
The code is quite simply and fast to run. You can find it on Github. I encourage you to pull it and try it. LDA is used to classify text in a document to a particular topic. It builds a topic per document model and words per topic model, modeled as Dirichlet distributions.
What is the next step for LDA?
The next step for LDA is to iterate over these probabilities and improve them in such a way that we are able to maximize the probability that we can generate our original documents, using these topics. Remember, each document is a mixture of topics, and each topic is a mixture of weighted words.
What is LDA used for NLP?
LDA is used to classify text in a document to a particular topic. It builds a topic per document model and words per topic model, modeled as Dirichlet distributions. Each document is modeled as a multinomial distribution of topics and each topic is modeled as a multinomial distribution of words.
What is LDA and how does it work?
LDA is a generative probability model, which means it attempts to provide a model for the distribution of outputs and inputs based on latent variables. This is opposed to discriminative models, which attempt to learn how inputs map to outputs.
What is meant by LDA?
Linear discriminant analysis takes the mean value for each class and considers variants in order to make predictions assuming a Gaussian distribution. It is one of several types of algorithms that is part of crafting competitive machine learning models.
What is LDA in unsupervised learning?
The Amazon SageMaker Latent Dirichlet Allocation (LDA) algorithm is an unsupervised learning algorithm that attempts to describe a set of observations as a mixture of distinct categories. LDA is most commonly used to discover a user-specified number of topics shared by documents within a text corpus.
Is LDA supervised or unsupervised?
Linear discriminant analysis (LDA) is one of commonly used supervised subspace learning methods.
Is LDA a type of clustering?
Strictly speaking, Latent Dirichlet Allocation (LDA) is not a clustering algorithm. This is because clustering algorithms produce one grouping per item being clustered, whereas LDA produces a distribution of groupings over the items being clustered. Consider k-means, for instance, a popular clustering algorithm.
Why LDA is used?
Linear discriminant analysis (LDA) is used here to reduce the number of features to a more manageable number before the process of classification. Each of the new dimensions generated is a linear combination of pixel values, which form a template.
What is LDA good for?
LDA is a technique for multi-class classification that can be used to automatically perform dimensionality reduction.
Is LDA a classifier?
LDA is a dimensionality reduction method, not a classifier.
How LDA works step by step?
Having chosen a value for K, the LDA algorithm works through an iterative process as follows:Initialize the model: Randomly assign a topic to each word in each document. ... Update the topic assignment for a single word in a single document: Choose a word in a document. ... Repeat Step 2 for all words in all documents.Iterate.
What is the difference between LDA and PCA?
LDA focuses on finding a feature subspace that maximizes the separability between the groups. While Principal component analysis is an unsupervised Dimensionality reduction technique, it ignores the class label. PCA focuses on capturing the direction of maximum variation in the data set.
How does linear discriminant analysis work?
The linear Discriminant analysis estimates the probability that a new set of inputs belongs to every class. The output class is the one that has the highest probability. That is how the LDA makes its prediction. LDA uses Bayes' Theorem to estimate the probabilities.
How is LDA different from PCA?
LDA focuses on finding a feature subspace that maximizes the separability between the groups. While Principal component analysis is an unsupervised Dimensionality reduction technique, it ignores the class label. PCA focuses on capturing the direction of maximum variation in the data set.
What does LDA optimize?
How will LDA optimize the distributions? The end goal of LDA is to find the most optimal representation of the Document-Topic matrix and the Topic-Word matrix to find the most optimized Document-Topic distribution and Topic-Word distribution.
How is LDA trained?
In order to train a LDA model you need to provide a fixed assume number of topics across your corpus. There are a number of ways you could approach this: Run LDA on your corpus with different numbers of topics and see if word distribution per topic looks sensible.
NLP with LDA (Latent Dirichlet Allocation) and Text Clustering to improve classification
This post is part 2 of solving CareerVillage’s kaggle challenge; however, it also serves as a general purpose tutorial for the following three things:
Problem Description
This section serves as a short reminder on what we are trying to do. CareerVillage, in its essence, is like Stackoverflow or Quora but for career questions. Users can post questions about any careers like computer science, pharmacology, aerospace engineering etc, and volunteer professionals try their best to answer the questions.
Data Preparation
Before we perform topic modeling, we need to specify our goals. In what context do we need topic modeling. In this article (part 3 where we make the model), we have four important features we need to calculate.
Topic Modeling (LDA)
As you can see from the image above, we will need to find tags to fill in our feature values and this is where LDA helps us. But first, what is LDA? A very basic explanation looks like this:
Semantic Similarity using Spacy
In our next step, we are going to check out semantic similarity using this wonderful library called Spacy and its similarity check.
DBSCAN for text clustering
Again, I will start this section by reinstating the goal of the section. We want to group semantically similar tags together, and at the end of the last section, we ended up converting all our tags to their respective vector representations in Spacy’s similarity model.
Summary
I hope this article served as a good tutorial for using Spacy, LDA, and the DBSCAN clustering algorithm. Although these topics are applied on the CareerVillage kaggle challenge, they are still applicable to other scenarios.
Step 1: Data collection
To spice things up, let’s use our own dataset! For this, we will use the newspaper3k library, a wonderful tool for easy article scraping.
Step 2: Preprocessing
The next step is to prepare the input data for the LDA model. LDA takes as input a document-term matrix.
Step 3: Model implementation
Using scikit-learn’s implementation of this algorithm is really easy. However, this abstraction can make it really difficult to understand what is going on behind the scenes. It is important to have at least some intuition on how the algorithms we use actually work, so let’s recap a bit on the explanations from the introduction.
Step 4: Visualization
One last step in our Topic Modeling analysis has to be visualization. One popular tool for interactive plotting of Latent Dirichlet Allocation results is pyLDAvis.
What is LDA in a document?
Latent Dirichlet Allocation (LDA) is one way to do this. LDA is a bag-of-words algorithm that helps us to automatically discover topics that are contained within a set of documents.
What is a document in LDA?
A document is a mixture of different topics which itself is an expression of words all tagged with a given probability of occurrence. Said differently, we have topic representations across all the documents and word distribution across all the topics. At the heart of LDA is this concept of a Dirichlet distribution.
What Did We Learn?
A true scientist is never afraid to examine the results of his or her experiment. Here goes.
What libraries are needed for NLP?
Getting this done will require a suite of NLP libraries. A few of these include Gensim, Mallet, Spacy, and NLTK.
Is Pandas a Python program?
Pandas is a great python tool to do this. I import it and read in my emails.csv file. I don’t want the whole dataset so I grab a small slice to start (first 10,000 emails).
What is LDA in text?
LDA is used to classify text in a document to a particular topic. It builds a topic per document model and words per topic model, modeled as Dirichlet distributions. Each document is modeled as a multinomial distribution of topics and each topic is modeled as a multinomial distribution of words. LDA assumes that the every chunk ...
How many topics are there in LDA?
The output from the model is a 8 topics each categorized by a series of words. LDA model doesn’t give a topic name to those words and it is for us humans to interpret them. See below sample output from the model and how “I” have assigned potential topics to these words.
What is LDA in natural language processing?
In natural language processing, the Latent Dirichlet Allocation ( LDA) is a generative statistical model that allows sets of observations to be explained by unobserved groups that explain why some parts of the data are similar. For example, if observations are words collected into documents, it posits that each document is a mixture of a small number of topics and that each word's presence is attributable to one of the document's topics. LDA is an example of a topic model and belongs to the machine learning field and in a wider sense to the artificial intelligence field.
Who proposed LDA?
In the context of population genetics, LDA was proposed by J. K. Pritchard, M. Stephens and P. Donnelly in 2000. LDA was applied in machine learning by David Blei, Andrew Ng and Michael I. Jordan in 2003.
What is a variation of LDA?
Variations on LDA have been used to automatically put natural images into categories, such as "bedroom" or "forest", by treating an image as a document, and small patches of the image as words; one of the variations is called Spatial Latent Dirichlet Allocation.
How to extend LDA?
This is achieved by using another distribution on the simplex instead of the Dirichlet. The Correlated Topic Model follows this approach, inducing a correlation structure between topics by using the logistic normal distribution instead of the Dirichlet. Another extension is the hierarchical LDA (hLDA), where topics are joined together in a hierarchy by using the nested Chinese restaurant process, whose structure is learnt from data. LDA can also be extended to a corpus in which a document includes two types of information (e.g. , words and names), as in the LDA-dual model. Nonparametric extensions of LDA include the hierarchical Dirichlet process mixture model, which allows the number of topics to be unbounded and learnt from data.
What is jLDADMM?
jLDADMM A Java package for topic modeling on normal or short texts. jLDADMM includes implementations of the LDA topic model and the one-topic-per-document Dirichlet Multinomial Mixture model. jLDADMM also provides an implementation for document clustering evaluation to compare topic models.
What is topic discovery in machine learning?
One application of LDA in machine learning - specifically, topic discovery, a subproblem in natural language processing - is to discover topics in a collection of documents, and then automatically classify any individual document within the collection in terms of how "relevant" it is to each of the discovered topics. A topic is considered to be a set of terms (i.e., individual words or phrases) that, taken together, suggest a shared theme.
What is the problem of learning the various distributions?
Learning the various distributions (the set of topics, their associated word probabilities, the topic of each word, and the particular topic mixture of each document) is a problem of statistical inference.
What is LDA in a document?
LDA is a popular topic modeling algorithm that works by discovering the hidden (latent) topics in a set of documents with the help of Dirichlet distributions
How to learn LDA?
Curious? To learn more about LDA topic modeling: 1 Here’s a comprehensive yet intuitive explanation of how LDA topic modeling works —step by step and with no math 2 Here’s an explanation of how to evaluate topic models —an important and sometimes overlooked aspect of topic modeling 3 Here’s a hands-on example of how LDA works in practice (with Python code) which uses topic modeling to analyze US corporate earnings call transcripts
Why is the LDA topic modeling algorithm iterative?
With each iteration of the LDA algorithm, better and better topics are formed.
Why is LDA topic modeling important?
This is one of the reasons why LDA topic modeling is a popular approach for analyzing unstructured text data.
How many steps does LDA use?
LDA uses a 4-step iterative process, which produces better results as the number of iterations increases based on the way that probabilities are updated with successive iterations in the LDA algorithm.
What is the requirement of LDA?
One requirement of LDA is that the number of topics needs to be decided in advance. Based on this number—let’s call it K —the algorithm will generate K topics that best fit the data.
How many distributions are there in LDA?
In LDA topic modeling, there are two Dirichlet distributions used. The first is a distribution over topics and the second is a distribution over words.