
A Polyglot Data Model is a model that should:
- allow denormalization, if desired, given access patterns;
- allow complex data types;
- contain data types that mapped to those available in the respective target technologies;
- be able to generate schemas for a variety of technologies.
What is polyglot data model?
A Polyglot Data Model sits over the previous boundary between logical and physical. It is called by some a logical model in the sense that it is technology-agnostic, but it is really a common physical schema with the following features:
What is a polyglot persistence database?
A polyglot persistence database is used when it is necessary to solve a complex problem by breaking that problem into segments and applying different database models. It is then necessary to aggregate the results into a hybrid data storage and analysis solution.
When is polyglot programming necessary?
Polyglot programming is considered necessary when a single, general-purpose language cannot offer the desired level of functionality or speed, interact properly with the database or the desired delivery platform, or meet end user expectations.
What is a polyglot data model?
Polyglot Persistence is a process for storing data in in the best database available, no matter the data model and data storage technology. This process is based on the understanding different data stores will handle certain types of data better than others.
What is polyglot programming in database technologies?
Polyglot persistence refers to using different data storage technologies to handle varying data storage needs. It's an offshoot of polyglot programming, which means using different programming languages to build an application. Simply put, it's an application that uses more than one core database technology.
What is azure polyglot?
Polyglot Persistence is the concept of using different storage technologies by the same application or solution, leveraging the best capabilities of each component. Azure Data Services support all possible data types and its usages.
What is polyglot persistence in Salesforce?
Polyglot Persistence is a fancy term to mean that when storing data, it is best to use multiple data storage technologies, chosen based upon the way data is being used by individual applications or components of a single application.
What is a polyglot software engineer?
A polyglot is a person who speaks many languages, therefore a polyglot software engineer is a person who writes software with many programming languages. It might be tempting to box yourself into a single language in hopes of attaining mastery.
What is polyglot Microservice?
Polyglot or multi-language microservices are a microservice architecture in which developers use multiple programming languages and technologies simultaneously. Therefore, each microservice can use the technology that is best suited for implementing the microservice's use case.
What is polyglot persistence in NoSQL?
Polyglot persistence is a hybrid approach enabling usage of multiple databases in a single application/software. A Software that is capable of using more than one type of data storage is referred to as Polyglot-persistent software.
What are the types of databases in Azure?
Azure offers a choice of fully managed relational, NoSQL, and in-memory databases, spanning proprietary and open-source engines, to fit the needs of modern app developers.
What is polyglot persistence and why is it considered a new approach?
Polyglot persistence is a way of storing data. It's an approach that acknowledges that often there is no one size fits all solution to data storage. From the types of data you're trying to store to your application architecture, polyglot persistence is a hybrid solution to data management.
What is a polyglot application?
Polyglot programming is the practice of writing code in multiple languages to capture additional functionality and efficiency not available in a single language. The use of domain specific languages (DSLs) has become a standard practice for enterprise application development.
Why Salesforce is called multi-tenant?
Multi-Tenant Layer Salesforce architecture is so popular because of its multitenancy. The multitenant architecture means one common application for multiple groups or clients. In such architecture, multiple clients use the same server, but their oaks are isolated from each other.
What is polyglot persistence in Microservices?
Whether it is polyglot programming -- the use of multiple programming languages to build an application -- or polyglot persistence -- the use of multiple types of storage methods for a single application -- microservices supports and even encourages this diversity.
Push and Pull from the target model
Many customers having accumulated physical data models in Hackolade prior to the introduction of the new functionality will want to convert their target model into a polyglot model. This is done by opening the physical target model, selecting the menu Tools > Polyglot > Convert to Polyglot Model...
Data type mapping
On the polyglot data model side, a long list of physical data types has been compiled across the different targets support by different Hackolade plugins. It was on purpose that this approach was decided instead of providing only a list of logical data types.
Naming conventions
Target-specific transformations rules are applied during the process of deriving from the polyglot model.
Maintain and update the target model
Once a target model has been created and derived from a polyglot model, it contains all the derived objects. You may not currently edit the attributes of an entity, but you may add new entities and views that are specific to the physical target model, for example based on access patterns. You may also remove entities from the target model.
What is a polyglot?
A polyglot is someone who speaks multiple languages. A polyglot data scientist, as I see it, is someone who uses multiple programming languages, tools, and techniques to obtain, scrub, explore, and model data.
What is a jupyter?
Project Jupyter is an open-source project, born out of the IPython Project in 2014 as it evolved to support interactive data science and scientific computing across all programming languages. Jupyter supports over 40 programming languages, including Python, R, Julia, and Scala. In this section I’ll focus on Python.
What is a Jupyter notebook?
Jupyter Notebook is, in essence, a browser-based version of Jupyter Console. It supports the same ways to leverage the command line, including the exclamation mark and bash magic. The biggest difference is that a notebook cannot only contain code, but also marked-up text, equations, and data visualizations.
The Old Reality
Until the 1990s most companies used a single version of a single database product. No matter the use case or the technical requirements, what prevailed was the company standard and all applications had to adapt to the official database vendor.
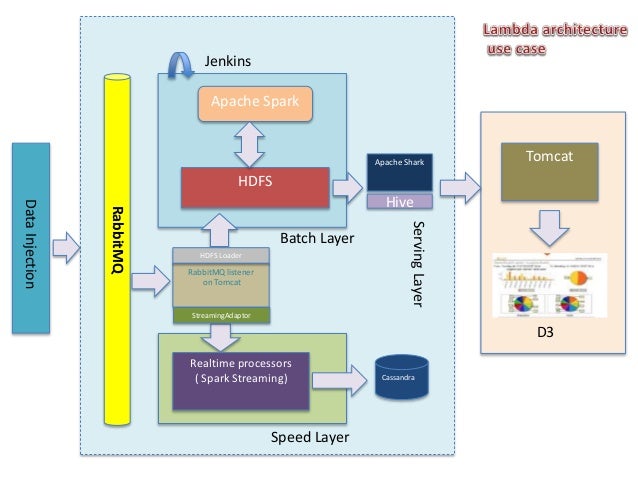
Cloud Native Applications and Polyglot Persistence on Azure
At this point we started to see some Polyglot Persistence in architecture level. Modern Data Warehouses were created using multiple products and services, with the data flowing from the data sources until the best storage option for that data type.
The Future
Right now, we are seen the growth of concepts that extend the ideas presented in this post, like Data Mesh, Low Code Tools, and Micro-Frontends. Also, Azure’s teams just released a data product called Azure Synapse Link, that enable HTAP scenarios in your Data Architecture.
How to use polyglot persistence
Unfortunately, polyglot persistence cannot be downloaded; it must be designed for the specific data architecture used by an enterprise. However, it has the flexibility to be used with SQL, NoSQL or hybrid database systems.
Example of polyglot persistence
An e-commerce store is a good example of where an organization might apply polyglot persistence. An online store uses many types of data for the shopping cart alone -- such as transactional, session, inventory, completed orders and customer profiles.
What is polyglot persistence?
Polyglot persistence shares its origins with how the term Polyglot programming is defined. Polyglot programming is a term coined by Neal Ford in 2006, and expresses the idea that computer applications should be written in a mix of different programming languages, in order to take advantage of the fact that different languages are suitable for tackling different problems. Complex applications combine different types of problems, so picking the right language for each job may be more productive than trying to solve all aspects of the problem using a single language. This same concept can be applied to databases, that an application can communicate with different databases, using each for what it is best at to achieve an end goal, hence the term polyglot persistence .
Can a graph database be used for big data?
A graph database might solve the problem of relationships in case of Big Data, but it might not solve the problem of database transactions, which are provided by relational database management systems. Instead, a NoSQL document database might be used to store unstructured data for that particular part of the problem.
What is polyglot persistence?
The term polyglot persistence is used to describe solutions that use a mix of data store technologies. Therefore, it's important to understand the main storage models and their tradeoffs. Selecting the right data store for your requirements is a key design decision.
How are data stores categorized?
Data stores are often categorized by how they structure data and the types of operations they support. This article describes several of the most common storage models. Note that a particular data store technology may support multiple storage models. For example, a relational database management systems ...
What is a column family database?
A column-family database organizes data into rows and columns. In its simplest form, a column-family database can appear very similar to a relational database, at least conceptually. The real power of a column-family database lies in its denormalized approach to structuring sparse data.
What are the two types of information in a graph?
A graph database stores two types of information, nodes and edges. Edges specify relationships between nodes. Nodes and edges can have properties that provide information about that node or edge, similar to columns in a table. Edges can also have a direction indicating the nature of the relationship.
What is data analytics?
Data analytics stores provide massively parallel solutions for ingesting, storing, and analyzing data. The data is distributed across multiple servers to maximize scalability. Large data file formats such as delimiter files (CSV), parquet, and ORC are widely used in data analytics. Historical data is typically stored in data stores such as blob storage or Azure Data Lake Storage Gen2, which are then accessed by Azure Synapse, Databricks, or HDInsight as external tables. A typical scenario using data stored as parquet files for performance, is described in the article Use external tables with Synapse SQL.

Logical Or Polyglot Data Model?
A Polyglot Data Model For Your Polyglot Data
- There is a need for a data model which allows complex data types and denormalization, yet can be easily translated into vastly different syntaxes on the physical side. We call it a "Polyglot Data Model", a term inspired by the brilliant Polyglot Persistence approach promoted by Pramod Sadalage and Martin Fowler in their 2013 book NoSQL Distilled: A...
Data Model vs Schema Design
- A data model is an abstraction describing and documenting the information system of an enterprise. Data models provide value in understanding, communication, collaboration, governance, ... They help document the context and meaning of the data. But the value of data models at a technical level is in the artifacts they help create: schemas. A schema is a “consum…