
What is data typically stored in a traditional system?
What is typically stored in a traditional system such as a relational database or spreadsheet and accounts for about 20 percent of the data that surrounds us. structured data What type of data is not defined and does not follow a specified format and is typically free-form text such as emails, Twitter tweets, and text messages?
What is the difference between a database and a relational database?
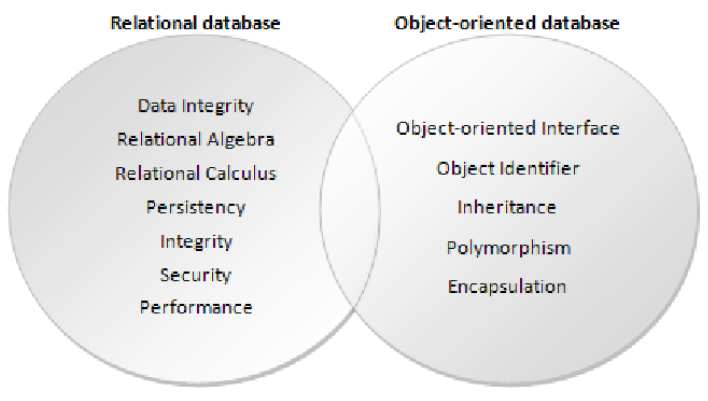
A database is a set of data stored in a computer. This data is usually structured in a way that makes the data easily accessible. What is a Relational Database? A relational database is a type of database. It uses a structure that allows us to identify and access data in relation to another piece of data in the database.
What is the structure of a database?
How Relational Databases Are Structured. The relational model means that the logical data structures—the data tables, views, and indexes—are separate from the physical storage structures. This separation means that database administrators can manage physical data storage without affecting access to that data as a logical structure.
Which of the following is an example of nontraditional data?
This nontraditional data is usually semi-structured and unstructured data. Examples include web logs, mobile web, clickstream, spatial and GPS coordinates, sensor data, RFID, video, audio, and image data.
What data type is typically found in databases and spreadsheets?
Structured data is data that adheres to a pre-defined data model and is therefore straightforward to analyse. Structured data conforms to a tabular format with relationship between the different rows and columns. Common examples of structured data are Excel files or SQL databases.
Why unstructured data are not stored in relational database systems?
Unstructured data is information that is not arranged according to a preset data model or schema, and therefore cannot be stored in a traditional relational database or RDBMS. Text and multimedia are two common types of unstructured content.
Which of the following are types of machine-generated structured data?
Machine-generated structured data includes sensor data, point-of-sale data, and web log data.
What are two sources of unstructured data?
Unstructured data just happens to be in greater abundance than structured data is. Examples of unstructured data are: Rich media. Media and entertainment data, surveillance data, geo-spatial data, audio, weather data.
Where is unstructured data stored?
Structured data is commonly stored in data warehouses and unstructured data is stored in data lakes. Both have cloud-use potential, but structured data allows for less storage space and unstructured data requires more.
Are relational databases good for unstructured data?
As for databases, structured data is usually stored in a relational database (RDBMS), while the best fit for unstructured data instead is so-called non-relational, or NoSQL databases.
Is stored in a traditional system such as a relational database or spreadsheet?
Structured data is typically stored in a traditional system such as a relational database or spreadsheet and accounts for about 20 percent of the data that surrounds us. is created by a machine without human intervention. Machine-generated structured data includes sensor data, point-of-sale data, and web log data.
What are three types of structured data?
These are 3 types: Structured data, Semi-structured data, and Unstructured data.Structured data – Structured data is data whose elements are addressable for effective analysis. ... Semi-Structured data – ... Unstructured data –
What are the various data types which are used for structured data?
We have mainly two types of structures or data storage models: Rectangular. Non-Rectangular.
What are structured unstructured and semi-structured data?
Structured data is stored is predefined format and is highly specific; whereas unstructured data is a collection of many varied data types which are stored in their native formats; while semi structured data that does not follow the tabular data structure models associated with relational databases or other data table ...
Which of the following is an example of structured data?
Answer: Relational Database. Explanation: Examples of structured data include numbers, dates, and groups of words and numbers called strings.
Which of the following is an example of structured data quizlet?
Examples of structured data would include numbers and dates. Unstructured data are basically the opposite of structured data and the files often include text and multimedia content. Examples of unstructured data would be videos and photos.
Can you store unstructured data in SQL?
The FileTables feature allows the user to store unstructured data (i.e. files, documents, images, etc.) in special tables in SQL Server called FileTables, but being able to access them from the file system.
Why NoSQL is suitable for unstructured data?
Flexibility: NoSQL databases generally provide flexible schemas that enable faster and more iterative development. The flexible data model makes NoSQL databases ideal for semi-structured and unstructured data.
Can SQL be used with unstructured data?
This is how SQL helps make queries. Speaking of databases for unstructured data, the most suitable option for this type of data will be non-relational databases, also known as NoSQL databases. NoSQL stands for “not only SQL.” These databases have various data models and they store data in a non-tabular way.
Why are NoSQL databases required for processing unstructured data?
NoSQL is particularly useful for storing unstructured data, which is growing far more rapidly than structured data and does not fit the relational schemas of RDBMS.
What is the key to keeping data accurate in a relational database?
A relational database won’t commit for one part until it knows it can commit for all three. This multifaceted commitment capability is called atomicity. Atomicity is the key to keeping data accurate in the database and ensuring that it is compliant with the rules, regulations, and policies of the business.
When did relational databases start?
Relational databases have been around since the 1970s.
What is SQL in database?
Over time, another strength of the relational model emerged as developers began to use structured query language (SQL) to write and query data in a database. For many years, SQL has been widely used as the language for database queries. Based on relational algebra, SQL provides an internally consistent mathematical language that makes it easier to improve the performance of all database queries. In comparison, other approaches must define individual queries.
Why was the relational database model created?
These data structures were inefficient, hard to maintain, and hard to optimize for delivering good application performance. The relational database model was designed to solve the problem of multiple arbitrary data structures.
What is relational model?
The relational model means that the logical data structures—the data tables, views, and indexes—are separate from the physical storage structures. This separation means that database administrators can manage physical data storage without affecting access to that data as a logical structure. For example, renaming a database file does not rename ...
What is atomicity in database?
Atomicity defines all the elements that make up a complete database transaction.
Why are duplicate rows not allowed in relational databases?
For example, an integrity rule can specify that duplicate rows are not allowed in a table in order to eliminate the potential for erroneous information entering the database.
What is the primary way businesses and organizations have stored and analyzed their data for the past 30 to 40 years?
Traditional data systems, such as relational databases and data warehouses , have been the primary way businesses and organizations have stored and analyzed their data for the past 30 to 40 years. Although other data stores and technologies exist, the major percentage of business data can be found in these traditional systems.
Why do organizations want to centralize data?
Organizations want to centralize a lot of their data for improved analytics and to reduce the cost of data movement. These centralized data repositories are referred to differently, such as data refineries and data lakes.
How much is Hadoop storage?
Solution—Local Storage: Hadoop can use the Hadoop Distributed File System (HDFS), a distributed file system that leverages local disks on commodity servers. Shared storage is about $1.20/GB, whereas local storage is about $.04/GB. Hadoop’s HDFS creates three replicas by default for high availability. So at 12 cents per GB, it is still a fraction of the cost of traditional shared storage.
What is schema on write?
Schema-on-write that requires data be validated against a schema before it can be written to disk. A significant amount of requirements analysis, design, and effort up front can be involved in putting the data in clearly defined structured formats. This can increase the time before business value can be realized from the data.
Why was Hadoop created?
Hadoop was created for a very important reason—survival. The Internet companies needed to solve this data problem to stay in business and be able to grow.
What is open source in Silicon Valley?
Silicon Valley is unique in that it has a large number of startup and Internet companies that by their nature are innovative, believe in open source, and have a large amount of cross-pollination in a very condensed area. Open source is a culture of exchanging ideas and writing software from individuals and companies around the world. Larger proprietary companies might have hundreds or thousands of engineers and customers, but open source has tens of thousands to millions of individuals who can write software and download and test software.
Why is business insight better than big data?
In some ways, business insight or insight generation might be a better term than big data because insight is one of the key goals for a big data platform. This type of data is raising the minimum bar for the level of information an organization needs to make competitive business decisions.
