Why should you retain data in Kafka?
By retaining data in Kafka, it can be easily reprocessed or backloaded into new systems. Today, as the amount of data stored in Kafka increases, users eventually hit a “retention cliff,” at which point it becomes significantly more expensive to store, manage, and retrieve data.
What is default retention time for segments in Kafka?
Default retention time for Segments is 7 days. Here are the parameters (in decreasing order of priority) that you can set in your Kafka broker properties file: In this policy, we configure the maximum size of a Log data structure for a Topic partition.
What is the use of Kafka?
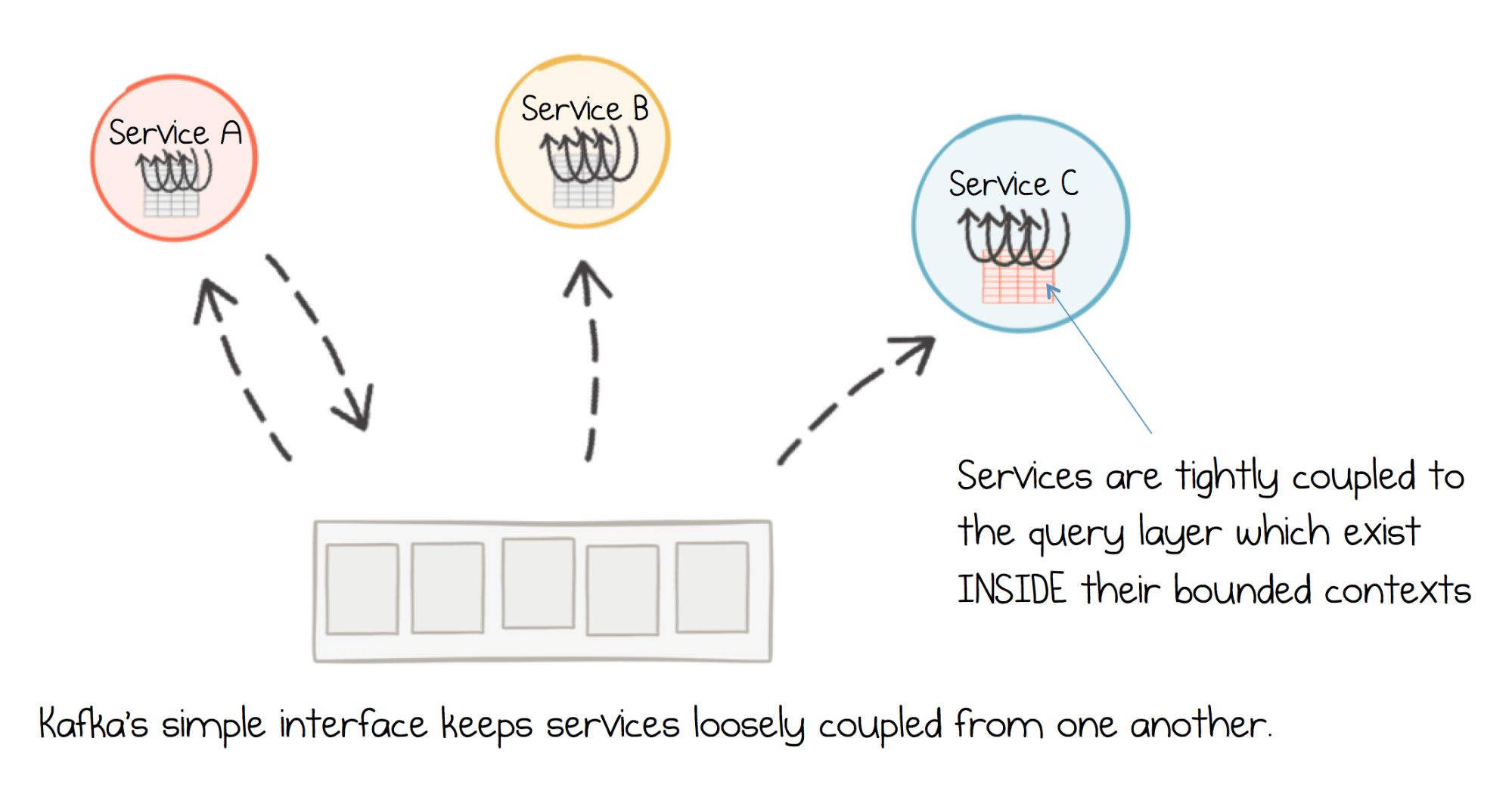
Kafka allows you to decouple data streams and systems: The Source System pushes data to Kafka, and then the Target System sources the data from Kafka. In this way, Kafka is used as data transportation mechanism. Because of this, it is generally used for two broad classes of applications:
What is Kafka tiered storage and how does it work?
Tiered Storage makes storing huge volumes of data in Kafka manageable by reducing this operational burden. The fundamental idea is to separate the concerns of data storage from the concerns of data processing. With this separation, it becomes much easier to scale each independently.
What makes Kafka a durable system?
Apache Kafka is able to handle many terabytes of data without incurring much at all in the way of overhead. Kafka is highly durable. Kafka persists the messages on the disks, which provides intra-cluster replication. This makes for a highly durable messaging system.
Does Kafka store data in memory or disk?
Data in Kafka is persisted to disk, checksummed, and replicated for fault tolerance. Accumulating more stored data doesn't make it slower. There are Kafka clusters running in production with over a petabyte of stored data.
Does Kafka need persistent storage?
Kafka is a stateful service, which means a Persistent Volume (PV) is required to prevent data loss from pod failure (in principal, Kafka tolerates N-1 pod failure with replication factor N, but using ephemeral storage for Kafka data is not recommended as multiple pods may run on the same host).
How does Kafka guarantee durability of the message in the event of a crash?
Kafka's replication protocol guarantees that once a message has been written successfully to the leader replica, it will be replicated to all available replicas. The producer-to-broker RPC can fail: Durability in Kafka depends on the producer receiving an ack from the broker.
How long does Kafka store data?
The short answer: Data can be stored in Kafka as long as you want. Kafka even provides the option to use a retention time of -1. This means “forever”.
Where is Kafka data stored?
The basic storage unit of kafka is partition. We can define, where kafka will store these partitions by setting logs. dirs param.
What is retention period in Kafka?
log.retention.hours The most common configuration for how long Kafka will retain messages is by time. The default is specified in the configuration file using the log. retention. hours parameter, and it is set to 168 hours, the equivalent of one week.
How do I check Kafka retention?
So, log.retention.ms would take the highest precedence.3.1. Basics. First, let's inspect the default value for retention by executing the grep command from the Apache Kafka directory: $ grep -i 'log.retention.[hms].*\=' config/server.properties log.retention.hours=168. ... 3.2. Retention Period for New Topic.
How much data can Kafka hold?
With 5 brokers it makes autoscaling the Kafka cluster to 4 vCPU and 12 GB memory we are able to sustain 200 million events per hour or 55,000 events per second simple.
What are the levels of data or message durability provided by Kafka at least once delivery guarantees?
Exactly once delivery: The message will be delivered exactly one time. Failures and retries may occur, but the consumer is guaranteed to only receive a given message once.
How Kafka guarantee exactly once?
A batch of data is consumed by a Kafka consumer from one cluster (called “source”) then immediately produced to another cluster (called “target”) by Kafka producer. To ensure “Exactly-once” delivery, the producer creates a new transaction through a “coordinator” each time it receives a batch of data from the consumer.
How does Kafka guarantee at least once?
At least once An application sends a batch of messages to Kafka. The application never receives a response so sends the batch again. In this case it may have been the first batch was successfully saved, but the acknowledgement was lost, so the messages end up being added twice.
Can Kafka store data forever?
>Kafka can perfectly keep your data around forever. In the sense that you can fiddle with it to the point where it doesn't purge things automatically, sure. But RDBMS provides more than the promise that it won't delete your data after a set period of time.
What is Kafka storage?
Kafka's storage unit is a partition A partition is an ordered, immutable sequence of messages that are appended to. A partition cannot be split across multiple brokers or even multiple disks.
What data structure does Kafka use?
Kafka is essentially a commit log with a simplistic data structure. The Kafka Producer API, Consumer API, Streams API, and Connect API can be used to manage the platform, and the Kafka cluster architecture is made up of Brokers, Consumers, Producers, and ZooKeeper.
How topics are stored in Kafka?
Topics are partitioned, meaning a topic is spread over a number of "buckets" located on different Kafka brokers. This distributed placement of your data is very important for scalability because it allows client applications to both read and write the data from/to many brokers at the same time.
Why is it important to have a storage layer in Kafka?
The most important goal for us was to ensure correctness. It is critical that the storage layer for Confluent Platform runs reliably and predictably and returns correct results , especially since the storage layer touches many of the most critical operations in Kafka. If data stored in Kafka is not durable or cannot be correctly consumed, then little else matters.
What is retention cliff in Kafka?
Today, as the amount of data stored in Kafka increases, users eventually hit a “retention cliff,” at which point it becomes significantly more expensive to store, manage, and retrieve data. To work around this, operators and application developers typically use an external store like Amazon S3 as a sink for long-term storage.
What is tiered storage in Kafka?
Tiered Storage makes storing huge volumes of data in Kafka manageable by reducing this operational burden. The fundamental idea is to separate the concerns of data storage from the concerns of data processing. With this separation, it becomes much easier to scale each independently.
Why is tiered storage transparent?
It was crucial to make Tiered Storage completely transparent to application developers so that they do not need to rewrite their applications. This means all Kafka features are supported seamlessly and transparently within the broker, including but not limited to transactional processing, exactly once processing, the ability to fetch data from the closest replica, etc.
How to make Confluent Platform more scalable?
Improved scalability and elasticity. To make Confluent Platform more scalable and elastic, it needs to be able to scale and balance workloads very quickly. Adding or removing brokers requires shifting partitions between brokers, which can be a time-consuming operation.
Why is reading data from remote storage important?
An important consideration is where this read from remote storage happens so that we do not end up blocking other requests, especially requests that are trying to produce to or consume from the tail of the log. With our implementation, reading data from Tiered Storage will have more desirable caching and I/O characteristics, as the I/O path for real-time produce and consume traffic is now completely independent of lagging consume traffic.
What happens when you use a tiered storage?
When using Tiered Storage, the majority of the data is offloaded to the remote store. When rebalancing, only a small subset of the data on the broker’s local disk must be replicated between replicas. This results in large operational improvements by reducing the time and cost to rebalance, expand or shrink clusters, or replace a failed broker.
How does Kafka control the frequency of segment data?
Kafka has server and per-topic configuration parameters that allow the frequency of flushing of segment data to disk to be controlled by the number of messages that have been received or by how long a message has been in the segment. In general, you should not override the default of allowing the operating system to decide when to flush the segment data to disk, but instead you should rely on replication for the durability of your data.
How does Kafka split data?
The data in a topic partition is split into log segments. For each log segment, there is a file on disk. One of the segments is the active segment into which messages are currently written. Once the size or time limit of the active segment is reached, the corresponding file is closed and a new one is opened. By splitting the data of a topic partition into segments, Kafka can purge and compact messages from the non-active segments.
What is a Kafka deployment?
A Kafka deployment consists of 1 or more Kafka broker processes in a Kafka cluster
How many Kafka clusters are there?
There is one Kafka cluster per instance of the Event Streams on IBM Cloud service in a multi-zone region.
Does Kafka write to disk?
To provide high performance, Kafka does not write data to disk immediately by default. The risk of data loss can be mitigated by replicating the data over more than one broker. The duration over which data is retained can be controlled by time or by maximum size of data.
Does IBM Event Streams use a per topic basis?
IBM Event Streams on IBM Cloud uses the default settings for flushing log segment data and does not allow it to be changed on a per-topic basis.
Does Kafka flush data to disk?
When the data is written to a log segment, by default it is not flushed to disk immediately. Kafka relies on the underlying operating system to lazily flush the data to disk, which improves performance. Although this might appear to increase the risk of data loss, in most cases, each topic partition will be configured to have more than 1 replica. So, the data will exist on more than one broker.
What is consumer offset in Kafka?
Kafka stores the offsets at which a consumer-group has been reading. The consumer offsets are committed in a Kafka topic named __consumer_offsets, and are NOT saved in metadata managed by Zookeeper. The consumer offset is the only metadata retained on a per-consumer basis, and it is controlled by the consumer. When a consumer in a group has processed data received from Kafka, it should be committing the offsets.
What is Kafka used for?
In this way, Kafka is used as data transportation mechanism. Because of this, it is generally used for two broad classes of applications: Building real-time streaming data pipelines that reliably get data between systems or applications.
What is a broker in Kafka?
On startup, a broker is marked as the coordinator for the subset of consumer groups that receive the RegisterConsumer Request from consumers and returns the RegisterConsumer Response containing the list of partitions they should own. The coordinator also starts failure detection to check if the consumers are alive or dead. When the consumer fails to send a heartbeat to the coordinator broker before the session timeout, the coordinator marks the consumer as dead and a rebalance is set in place to occur. This session time period can be set using the session.timeout.ms property of the Kafka service. The heartbeat.interval.ms property makes healthy consumers aware of the occurrence of a rebalance so as to re-send RegisterConsumer requests to the coordinator.
How many servers does Zookeeper have?
Zookeeper by design operates in a cluster with an odd number of Zookeeper servers, such as 3, 5, 7. One of these servers is a leader (handles writes) the rest of the servers are followers (handle reads). This makes the Zookeeper extremely fault-tolerant and it ought to be, as Kafka heavily depends on it.
What is Kafka protocol?
Kafka has a protocol that groups messages together. This allows network requests to group messages together and reduces network overload, the server in turn persists chunk of messages in one go, and consumer fetch larger linear chunks at once. Linear reads/writes on a disk are fast.
How to add messages to a topic in Kafka?
To add messages to a topic, we can use the console producer kafka-console-producer --broker-list <broker_hosts> --topic <topic_name> command. Here, <broker_hosts> is a connection string for brokers in the form <host>:<port>. Multiple broker hosts can be provided in a comma-separated form to allow fail-over.
What is the communication protocol in Kafka?
In Kafka, the communication between the clients and the servers is done with TCP protocol. As part of the main Kafka project, only the Java clients are maintained, but clients are available in other languages are available as independent open-source projects.
Understanding Kafka
Kafka is an Open-Source software program that lets you store, read, and analyze streaming data. It is free for everyone to use and is supported by a large community of users and developers who consistently contribute to new features, updates, and support.
Key Features of Kafka
With Apache Kafka, users can scale in all four dimensions: Event Producer, Event Processor, Event Consumer, and Event Connector. You can scale effectively with Kafka without experiencing downtime.
Top 6 Kafka Alternatives
Kafka is a widely used publish-subscribe-messaging service known for managing large volumes of information, handling both online and offline messages. However, Kafka has some shortcomings such as slow speeds, message tweaking, lesser message paradigms, and more, thereby increasing the usage of Kafka Alternatives.
Conclusion
In this article, you learned about Kafka, its features, and some top Kafka Alternatives. Even though Kafka is widely used, the technology segment has advanced to the point where other options can overshadow Kafka’s cons. There are various options available for choosing a stream processing solution.

Motivation Behind Tiered Storage

Goals For Implementing Tiered Storage
- We set out with several goals for implementing Tiered Storage within the heart of Kafka’s storage sub-system.
Implementation of Tiered Storage
- So how does Tiered Storage really work under the hood? At a high level, the idea is very simple: move bytes from one tier of storage to another. There are three main tasks to perform: tier eligible data to remote storage, retrieve tiered data when requested, and garbage collect data that is past retention or has been deleted otherwise. All of this happens seamlessly in the broker and require…
Final Thoughts
- At Confluent, we are committed to our mission to build a complete event streaming platform and help companies rearchitect themselves around this paradigm shift. As we continue to make Confluent Platform more reliable and scalable, Tiered Storage takes us further along this journey by making the platform elastic, more cost effective, easier to manage operationally, and viable f…
Ready to Get started?
- If you’d like to know more, you can download the Confluent Platformto get started with Tiered Storage and a complete event streaming platform built by the original creators of Apache Kafka. You can also learn more about Tiered Storage in the documentation and try the demo. Along with us, an amazing team of distributed systems engineers and product managers worked for over a …
Topic Partitions and Log Segments
Acknowledgements
- A producer client can choose how many replicas to wait to receive the data in memory (although not necessarily written to disk) before the write is considered complete. You use the ACKs setting in the producer client configuration. A producer sending messages has the following options for waiting for messages to be received by the Kafka: 1. It doesn’t wait for a reply (ACKs=0) 2. It wai…
Data Retention
- Data retention can be controlled by the Kafka server and by per-topic configuration parameters. The retention of the data can be controlled by the following criteria: 1. The size limit of the data being held for each topic partition: 1.1. log.retention.bytesproperty that you set in the Kafka broker properties file 1.2. retention.bytesproperty that ...
How Persistence Is configured in IBM Event Streams on IBM Cloud
- IBM Event Streams on IBM Cloud has many different plans to choose from, but the Enterprise plan offers the best options where persistence is concerned. The Enterprise plan offers significantly more partitions and storage space for maximum retention periods. For more information on IBM Event Streams on IBM Cloud plans, see "Choosing your plan" in the documentation. The Enterpri…
Summary
- To provide high performance, Kafka does not write data to disk immediately by default. The risk of data loss can be mitigated by replicating the data over more than one broker. The duration over which data is retained can be controlled by time or by maximum size of data.