How do categorical variables deal with missing values?
- Ignore observations of missing values if we are dealing with large data sets and less number of records has missing values.
- Ignore variable, if it is not significant.
- Develop model to predict missing values.
- Treat missing data as just another category.
How do I handle missing values in categorical data?
How do I handle missing values in categorical data? Most people just fill it in with the most common category (aka the “mode”). My personal favorite is to create a new category called “MISSING”. If you want to take it to the next level, use a decision tree to impute the missing value.
How to predict missing values in a regression model?
The regression or classification model can be used for the prediction of missing values depending on the nature (categorical or continuous) of the feature having missing value. Takes into account the covariance between the missing value column and other columns. This method works very well with categorical, continuous, and non-numerical features.
What is the best way to create a missing value category?
Most people just fill it in with the most common category (aka the “mode”). My personal favorite is to create a new category called “MISSING”. If you want to take it to the next level, use a decision tree to impute the missing value.
How do you deal with missing values in statistics?
– Generally, replacing the missing values with the mean/median/mode is a crude way of treating missing values. Depending on the context, like if the variation is low or if the variable has low leverage over the response, such a rough approximation is acceptable and could give satisfactory results.
How do you handle data with missing values?
There are 2 primary ways of handling missing values:Deleting the Missing values.Imputing the Missing Values.
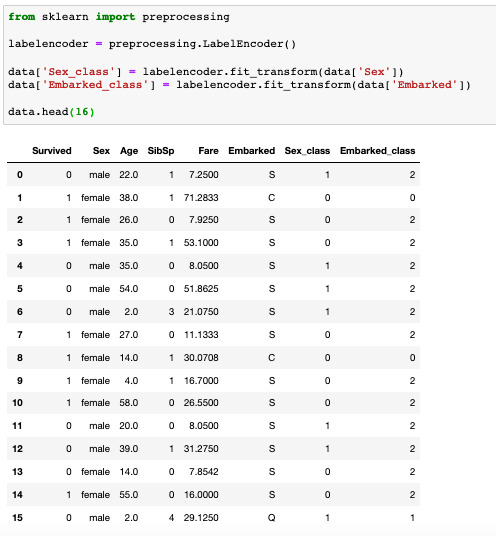
How do you handle missing values for categorical variables in R?
For the Categorical Variables, we are going to apply the “mode” function which we have to build it since it is not provided by R. Now that we have the “mode” function we are ready to impute the missing values of a dataframe depending on the data type of the columns.
How do you deal with categorical values?
How to Deal with Categorical Data for Machine LearningOne-hot Encoding using: Python's category_encoding library. Scikit-learn preprocessing. Pandas' get_dummies.Binary Encoding.Frequency Encoding.Label Encoding.Ordinal Encoding.
How do you handle missing or corrupted data in a dataset?
how do you handle missing or corrupted data in a dataset?Method 1 is deleting rows or columns. We usually use this method when it comes to empty cells. ... Method 2 is replacing the missing data with aggregated values. ... Method 3 is creating an unknown category. ... Method 4 is predicting missing values.
How do you deal with categorical variables with many values?
One standard way to solve this problem is a matrix factorization . You basically assign different numerical vectors to each row and each column and then you calculate the value in the cell by applying a function to the vectors corresponding to the selected row and column.
How do you treat categorical variables in regression?
Categorical variables require special attention in regression analysis because, unlike dichotomous or continuous variables, they cannot by entered into the regression equation just as they are. Instead, they need to be recoded into a series of variables which can then be entered into the regression model.
What is handling categorical data?
Categorical data is simply information aggregated into groups rather than being in numeric formats, such as Gender, Sex or Education Level. They are present in almost all real-life datasets, yet the current algorithms still struggle to deal with them. Take, for instance, XGBoost or most SKlearn models.
What is the mode of missing values?
We first impute missing values by the mode of the data. The mode is the value that occurs most frequently in a set of observations. For example, {6, 3, 9, 6, 6, 5, 9, 3} the Mode is 6, as it occurs most often.
What is strategy in a data set?
strategy : The data which will replace the NaN values from the dataset. The strategy argument can take the values – ‘mean' (default), ‘median’, ‘most_frequent’ and ‘constant’.
What is the most interesting approach to predicting missing values?
The most interesting approach is surely the predicting of missing values with a classification algorithm. This will give us the opportunity not to waste a good chunk of the dataset, and thus a large amount of information. If our predictions will be accurate enough, with this technique we should have the best scoring metrics.
Which method is more effective to assign missing values with the most frequent data?
Certainly more effective method is to assign the missing values with the most frequent data: the mode. But be careful that this could lead to an unbalanced dataset if the missing values were a considerable number.
Can you delete a feature from a dataset?
Our considerations are driven by metrics. Deleting the feature from the dataset should be our last resort. Replacing null data with the most frequent ones or deleting the rows can be a convenient solution in case we have few missing data or a very large dataset. On the contrary, in case we have a lot of missing values or a small dataset, a prediction/clustering could save us valuable information that would otherwise be lost.
When missing values are from categorical columns (string or numerical) then the missing values can be replaced with the most?
When missing values is from categorical columns (string or numerical) then the missing values can be replaced with the most frequent category . If the number of missing values is very large then it can be replaced with a new category.
What is the missing value replaced by?
The missing values are replaced by the mean value in the above example, in the same way, it can be replaced by the median value.
Why is there a lot of missing data?
The real-world data often has a lot of missing values. The cause of missing values can be data corruption or failure to record data. The handling of missing data is very important during the preprocessing of the dataset as many machine learning algorithms do not support missing values.
What is the purpose of replacing the mean, median, and mode of remaining values in a column?
This method can prevent the loss of data compared to the earlier method. Replacing the above two approximations (mean, median) is a statistical approach to handle the missing values .
What is regression model?
The regression or classification model can be used for the prediction of missing values depending on the nature (categorical or continuous) of the feature having missing value.
What is a model trained with the removal of all missing values?
A model trained with the removal of all missing values creates a robust model.
Can k-NN ignore missing values?
The k-NN algorithm can ignore a column from a distance measure when a value is missing. Naive Bayes can also support missing values when making a prediction. These algorithms can be used when the dataset contains null or missing values.
