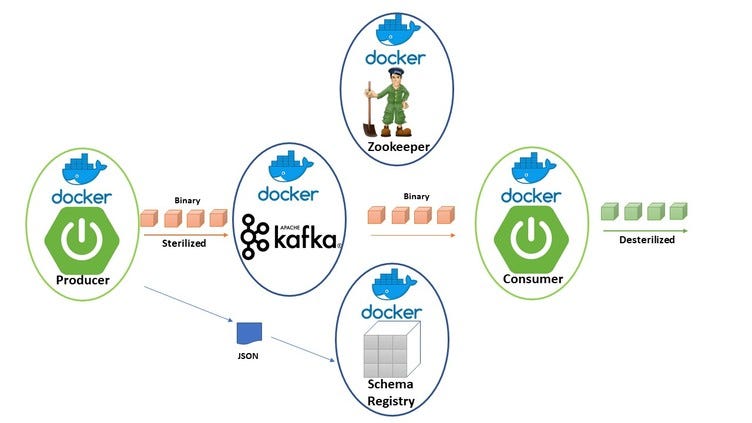
KafkaConsumer module is imported from the Kafka library to read data from Kafka. sys module is used here to terminate the script. The same hostname and port number of the producer are used in the script of the consumer to read data from Kafka. The topic name of the consumer and the producer must be the same that is ‘First_topic’. Next, the consumer object is initialized with the three arguments.
Full Answer
How to implement real-time data streaming in Kafka?
Real-time data streaming can be implemented by using Kafka to receive data between the applications. It has three major parts. These are producer, consumer, and topics. The producer is used to send a message to a particular topic and each message is attached with a key.
How do I get the timestamp of a Kafka consumer record?
You can use it via KafkaConsumer#offsetsForTime (). This will return the corresponding offsets and you can feed them into KafkaConsumer#seek (). You can just consume the data and check the records timestamp field via ConsumerRecord#timestamp () to see when you can stop processing. Note, that data is strictly ordered by offsets but not by timestamp.
What is the kafkaconsumer client in Java?
In this chapter we discussed the Java KafkaConsumer client that is part of the org.apache.kafka.clients package. At the time of writing, Apache Kafka still has two older clients written in Scala that are part of the kafka.consumer package, which is part of the core Kafka module.
How do I commit offsets in Kafka consumer?
The KafkaConsumer API provides multiple ways of committing offsets. The easiest way to commit offsets is to allow the consumer to do it for you. If you configure enable.auto.commit=true, then every five seconds the consumer will commit the largest offset your client received from poll ().

How do I get data from a Kafka server?
1.3 Quick StartStep 1: Download the code. Download the 2.0. ... Step 2: Start the server. ... Step 3: Create a topic. ... Step 4: Send some messages. ... Step 5: Start a consumer. ... Step 6: Setting up a multi-broker cluster. ... Step 7: Use Kafka Connect to import/export data. ... Step 8: Use Kafka Streams to process data.
How do I retrieve data from Kafka topic?
Short AnswerProvision your Kafka cluster.Initialize the project.Write the cluster information into a local file.Download and setup the Confluent CLI.Create a topic with multiple partitions.Produce records with keys and values.Start a console consumer to read from the first partition.More items...
How can I get data from Kafka consumer?
8:1624:46Learning How to Consume Data from Kafka - YouTubeYouTubeStart of suggested clipEnd of suggested clipOrder of messages by default. And we can demonstrate. This by using the built-in kafka consoleMoreOrder of messages by default. And we can demonstrate. This by using the built-in kafka console consumer script which runs a small consumer as a shell script. It looks at kafka.
Can we query data from Kafka?
Yes, you can do it with interactive queries. You can create a kafka stream to read the input topic and generate a state store ( in memory/rocksdb and synchronize with kafka ). This state store is queryable by key ( ReadOnlyKeyValueStore ).
How do I see messages in Kafka tool?
In the tab “Properties” you can choose Key and message content type. If you added Avro plugin, as was described above you'll see Avro type as well. Choose the type used for your messages and go to the “Data” tab. Now you can see all messages that are in the selected topic.
Is Kafka pull or push?
Since Kafka is pull-based, it implements aggressive batching of data. Kafka like many pull based systems implements a long poll (SQS, Kafka both do). A long poll keeps a connection open after a request for a period and waits for a response.
How do I access Kafka?
1.3 Quick StartStep 1: Download the code. Download the 0.9. ... Step 2: Start the server. ... Step 3: Create a topic. ... Step 4: Send some messages. ... Step 5: Start a consumer. ... Step 6: Setting up a multi-broker cluster. ... Step 7: Use Kafka Connect to import/export data.
What is Kafka fetch?
Kafka consumers use a pull model to consume data. This means that a consumer periodically sends a request to a Kafka broker in order to fetch data from it. This is called a FetchRequest.
How do I open a Kafka file?
Starting the Kafka serverOpen the folder where Apache Kafka is installed. cd
How do I query a Kafka message?
The only fast way to search for a record in Kafka (to oversimplify) is by partition and offset. The new producer class can return, via futures, the partition and offset into which a message was written. You can use these two values to very quickly retrieve the message.
What is interactive query?
Interactive Query (also called Apache Hive LLAP, or Low Latency Analytical Processing) is an Azure HDInsight cluster type. Interactive Query supports in-memory caching, which makes Apache Hive queries faster and much more interactive.
Is KTable in memory?
KTable is fully stored in RocksDB (== in memory) When KTable receive null-value record it deletes record from RocksDB (== memory freed up)
How do I export messages from Kafka topic?
How to Better Manage Apache Kafka by Exporting Kafka Messages via Control CenterCreate Kafka messages (with key and value) directly from within Control Center.Export Kafka messages in JSON or CSV format via Control Center.Improved topic inspection by showing the last time that a message was produced to a topic.More items...•
How do I read a Kafka topic in Python?
Create a file named consumer1.py with the following python script. KafkaConsumer module is imported from the Kafka library to read data from Kafka. sys module is used here to terminate the script. The same hostname and port number of the producer are used in the script of the consumer to read data from Kafka.
How do I copy data from one Kafka topic to another?
Click on a source topic, select target topic, and click “Start Copying” button. That's it. Kafka Magic will try copying up to 'Max Results' messages from source to target using default schema assignments for the topics.
How do I transfer data with Kafka?
Sending data to Kafka TopicsThere are following steps used to launch a producer:Step1: Start the zookeeper as well as the kafka server.Step2: Type the command: 'kafka-console-producer' on the command line. ... Step3: After knowing all the requirements, try to produce a message to a topic using the command:More items...
How to set Kafka to wait?
By setting fetch.min.bytes, you tell Kafka to wait until it has enough data to send before responding to the consumer. fetch.max.wait.ms lets you control how long to wait. By default, Kafka will wait up to 500 ms. This results in up to 500 ms of extra latency in case there is not enough data flowing to the Kafka topic to satisfy the minimum amount of data to return. If you want to limit the potential latency (usually due to SLAs controlling the maximum latency of the application), you can set fetch.max.wait.ms to a lower value. If you set fetch.max.wait.ms to 100 ms and fetch.min.bytes to 1 MB, Kafka will receive a fetch request from the consumer and will respond with data either when it has 1 MB of data to return or after 100 ms, whichever happens first.
How to scale data consumption from a Kafka topic?
The main way we scale data consumption from a Kafka topic is by adding more consumers to a consumer group. It is common for Kafka consumers to do high-latency operations such as write to a database or a time-consuming computation on the data.
What is a consumer group in Kafka?
Kafka consumers are typically part of a consumer group. When multiple consumers are subscribed to a topic and belong to the same consumer group, each consumer in the group will receive messages from a different subset of the partitions in the topic. Let’s take topic T1 with four partitions.
What is consumer API?
At the heart of the consumer API is a simple loop for polling the server for more data. Once the consumer subscribes to topics , the poll loop handles all details of coordination, partition rebalances, heartbeats, and data fetching, leaving the developer with a clean API that simply returns available data from the assigned partitions. The main body of a consumer will look as follows:
Does Kafka have partition policies?
Kafka has two built-in partition assignment policies , which we will discuss in more depth in the configuration section. After deciding on the partition assignment, the consumer group leader sends the list of assignments to the GroupCoordinator, which sends this information to all the consumers.
What is Kafka messaging?
Kafka is an open-source distributed messaging system to send the message in partitioned and different topics. Real-time data streaming can be implemented by using Kafka to receive data between the applications. It has three major parts. These are producer, consumer, and topics.
How to create consumer1.py?
Create a file named consumer1.py with the following python script. KafkaConsumer module is imported from the Kafka library to read data from Kafka. sys module is used here to terminate the script. The same hostname and port number of the producer are used in the script of the consumer to read data from Kafka. The topic name of the consumer and the producer must be the same that is ‘ First_topic ’. Next, the consumer object is initialized with the three arguments. Topic name, group id and server information. for loop is used here to read the text send from Kafka producer.
Can different types of data be sent from the producer on a particular topic that can be read by the consumer?
Different types of data can be sent from the producer on a particular topic that can be read by the consumer. How a simple text data can be sent and received from Kafka using producer and consumer is shown in this part of this tutorial.
Can Kafka read JSON?
JSON formatted data can be sent by the Kafka producer and read by Kafka consumer using the json module of python. How JSON data can be serialized and de-serialized before sending and receiving the data using the python-kafka module is shown in this part of this tutorial.
What is Kafka Connect?
Kafka Connect is a brilliant solution for bringing your data into Kafka for further processing and analytics.
Is there a predicate in Kafka Connect?
Note: Since Kafka 2.6, predicates have been added to the Kafka Connect API. We plan to implement conditions as predicates in the future.
Can you have multiple tasks in Kafka?
Multiple tasks and ports. You may find that one instance of the connector is not sufficient to consume a large amount of data. To address this, you can configure multiple tasks. Multiple tasks may happen to run on the same Kafka Connect worker, so to avoid port conflicts, you can define multiple ports:
Can you run multiple Kafka clusters?
To implement a highly available data receiving service, you can run multiple Kafka Connect clusters that send data to the same Kafka cluster. This allows you to perform connector maintenance with zero downtime in receiving the data: