
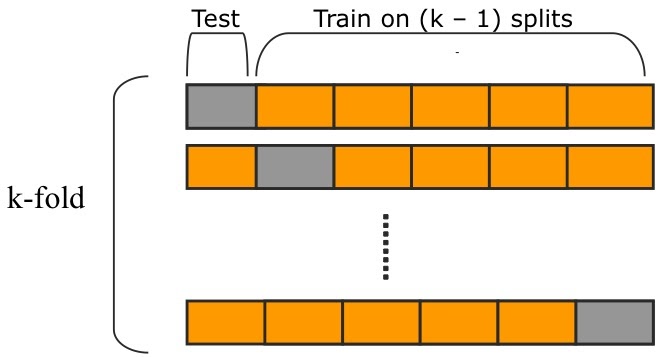
- Randomly divide a dataset into k groups, or “folds”, of roughly equal size.
- Choose one of the folds to be the holdout set. ...
- Repeat this process k times, using a different set each time as the holdout set.
- Calculate the overall test MSE to be the average of the k test MSE's.
How do I get k-fold cross-validation?
Accordingly, you can change k for 3 or 10 to get 3-folds cross-validation or 10-fold cross-validation. Play around with the number of folds to get an impression of the number of folds suitable for your data at hand. For k-fold cross-validation, we randomly subset our data in k folds of roughly equal size.
How to evaluate a machine learning model using k-fold cross validation?
To check whether the developed model is efficient enough to predict the outcome of an unseen data point, performance evaluation of the applied machine learning model becomes very necessary. K-fold cross-validation technique is basically a method of resampling the data set in order to evaluate a machine learning model.
What is the difference between LOOCV and k-fold cross-validation?
For models that take a long time to fit, k-fold cross-validation can compute the test MSE much quicker than LOOCV and in many cases the test MSE calculated by each approach will be quite similar if you use a sufficient number of folds. Repeated K-fold Cross-Validation: This is where k-fold cross-validation is simply repeated n times.
How does k-fold cross-validation affect bias and variance?
In general, the more folds we use in k-fold cross-validation the lower the bias of the test MSE but the higher the variance. Conversely, the fewer folds we use the higher the bias but the lower the variance.
How to do k fold cross validation?
What is RMSE in math?
What is the R-squared of a model?
What is the MAE of a model?
What are the three metrics in the output?
See 2 more
About this website
How do I run k-fold cross-validation in R?
Steps involved in the K-fold Cross Validation in R:Treat that subset as the validation set.Use all the rest subsets for training purpose.Training of the model and evaluate it on the validation set or test set.Calculate prediction error.
How do you calculate k-fold cross-validation?
k-Fold Cross-ValidationShuffle the dataset randomly.Split the dataset into k groups.For each unique group: Take the group as a hold out or test data set. Take the remaining groups as a training data set. ... Summarize the skill of the model using the sample of model evaluation scores.
How does cross-validation work in R?
Briefly, cross-validation algorithms can be summarized as follow:Reserve a small sample of the data set.Build (or train) the model using the remaining part of the data set.Test the effectiveness of the model on the the reserved sample of the data set. If the model works well on the test data set, then it's good.
What does CV lm do in R?
Description. This function gives internal and cross-validation measures of predictive accuracy for ordinary linear regression. The data are randomly assigned to a number of `folds'. Each fold is removed, in turn, while the remaining data is used to re-fit the regression model and to predict at the deleted observations.
How does k-fold cross-validation work explain with example?
K-fold Cross-Validation is when the dataset is split into a K number of folds and is used to evaluate the model's ability when given new data. K refers to the number of groups the data sample is split into. For example, if you see that the k-value is 5, we can call this a 5-fold cross-validation.
What is the best K for cross-validation?
The key configuration parameter for k-fold cross-validation is k that defines the number folds in which to split a given dataset. Common values are k=3, k=5, and k=10, and by far the most popular value used in applied machine learning to evaluate models is k=10.
When should you use k-fold cross-validation?
Cross-validation is usually used in machine learning for improving model prediction when we don't have enough data to apply other more efficient methods like the 3-way split (train, validation and test) or using a holdout dataset.
What steps are in cross-validation procedure?
Here's the generic procedure: Divide data set at random into training and test sets. Fit model on training set. Test model on test set. Compute and save fit statistic using test data (step 3). Repeat 1 - 4 several times, then average results of all step 4.
How do I validate a regression model in R?
Validating Machine Learning Models with RData.Holdout Validation.Build, Predict and Evaluate the Model.K-fold Cross-Validation.Repeated K-fold Cross-Validation.Leave-One-Out Cross-Validation (LOOCV)
What library is CV GLM in R?
the boot libraryThe cv. glm() function is part of the boot library. The cv. glm() function produces a list with several components.
Can we use cross-validation for regression?
Cross Validation is a very necessary tool to evaluate your model for accuracy in classification. Logistic Regression, Random Forest, and SVM have their advantages and drawbacks to their models. This is where cross validation comes in.
What package is CV GLM?
boot packageThe cv. glm() function is part of the boot package. The cv. glm() function produces a list with several components.
How do you interpret residual standard error?
The smaller the residual standard error, the better a regression model fits a dataset. Conversely, the higher the residual standard error, the worse a regression model fits a dataset.
What does Pr (>| t |) mean?
Pr(>|t|) gives you the p-value for that t-test (the proportion of the t distribution at that df which is greater than the absolute value of your t statistic).
What does lm mean in statistics?
linear regression modelIn this post we describe how to interpret the summary of a linear regression model in R given by summary(lm). We discuss interpretation of the residual quantiles and summary statistics, the standard errors and t statistics , along with the p-values of the latter, the residual standard error, and the F-test.
What does coef () do in R?
coef is a generic function which extracts model coefficients from objects returned by modeling functions.
K-fold Cross Validation in R Programming - GeeksforGeeks
Implement the K-fold Technique on Classification. Classification machine learning models are preferred when the target variable consist of categorical values like spam, not spam, true or false, etc. Here Naive Bayes classifier will be used as a probabilistic classifier to predict the class label of the target variable.. Step 1: Loading the dataset and other required packages
Repeated K-fold Cross Validation in R Programming
Repeated K-fold is the most preferred cross-validation technique for both classification and regression machine learning models. Shuffling and random sampling of the data set multiple times is the core procedure of repeated K-fold algorithm and it results in making a robust model as it covers the maximum training and testing operations.
How to Perform Cross Validation for Model Performance in R
In statistics, we often build models for two reasons: To gain an understanding of the relationship between one or more predictor variables and a response variable. To use a model to predict future observations.
Introduction to K-Fold Cross-Validation in R - Analytics Vidhya
This plot shows that our dataset slightly imbalanced but still good enough. It has a 46:54 ratio. You should start to worry if your dataset has more than 60% of the data in one class.
Creating folds for k-fold CV in R using Caret - Stack Overflow
Stack Overflow for Teams is moving to its own domain! When the migration is complete, you will access your Teams at stackoverflowteams.com, and they will no longer appear in the left sidebar on stackoverflow.com.. Check your email for updates.
What is the purpose of machine learning?
The prime aim of any machine learning model is to predict the outcome of real-time data. To check whether the developed model is efficient enough to predict the outcome of an unseen data point, performance evaluation of the applied machine learning model becomes very necessary. K-fold cross-validation technique is basically a method of resampling the data set in order to evaluate a machine learning model. In this technique, the parameter K refers to the number of different subsets that the given data set is to be split into. Further, K-1 subsets are used to train the model and the left out subsets are used as a validation set.
What is train control function?
In this step, the trainControl () function is defined to set the value of the K parameter and then the model is developed as per the steps involved in the K-fold technique. Below is the implementation.
How many rows are there in a dataset?
According to the above information, the dataset contains 250 rows and 9 columns. The data type of independent variables is < dbl> which comes from double and it means the double-precision floating-point number. The target variable is of <fct> data type means factor and it is desirable for a classification model. Moreover, the target variable has 2 outcomes, namely Down and Up where the ratio of these two categories is almost 1:1, i.e., they are balanced. All the categories of the target variable must be in approximately equal proportion to make an unbiased model. For this purpose, there are many techniques like:
What language is used to implement the K-fold method?
To implement all the steps involved in the K-fold method, the R language has rich libraries and packages of inbuilt functions through which it becomes very easy to carry out the complete task. The following are the step-by-step procedure to implement the K-fold technique as a cross-validation method on Classification and Regression machine learning models.
Why is it necessary to inspect a data set?
It will give a clear idea about the structure as well as the various kinds of data types present in the data set. For this purpose, the data set must be assigned to a variable. Below is the code to do the same.
When to use a Naive Bayes classifier?
Here Naive Bayes classifier will be used as a probabilistic classifier to predict the class label of the target variable.
Where is the value of the K parameter defined?
The value of the K parameter is defined in the trainControl () function and the model is developed according to the steps mentioned in the algorithm of the K-fold cross-validation technique. Below is the implementation.
How many rows are in a fold?
Let’s say that we have 100 rows of data. We randomly divide them into ten groups of folds. Each fold will consist of around 10 rows of data. The first fold is going to be used as the validation set, and the rest is for the training set. Then we train our model using this dataset and calculate the accuracy or loss. We then repeat this process but using a different fold for the validation set. See the image below.
What is the lowest accuracy of a boxplot?
We can see that each of the folds achieves an accuracy that is not much different from one another. The lowest accuracy is 72.58% , and also in the boxplot, we do not see any outliers. Meaning that our model was performing well across the k-fold cross-validation.
Why is the distribution between two labels not too much different?
Here we want to confirm that the distribution between the two label data is not too much different. Because imbalanced datasets can lead to imbalanced accuracy. This means that your model will always predict towards one label only, either it will always predict 0 or 1.
How many times does a k-fold work?
While the validation set approach is working by splitting the dataset once, the k-Fold is doing it five or ten times . Imagine you are doing the validation set approach ten times using a different group of data.otherother
How to determine if a model is performing well on each fold?
We can determine that our model is performing well on each fold by looking at each fold’s accuracy. In order to do this, make sure to set the savePredictions parameter to TRUE in the trainControl () function.
Why do we use the train function?
Here we use the Naive Bayes method and we set the tuneLength to zero because we focus on evaluating the method on each fold. We can also set the tuneLength if we want to do the parameter tuning during the cross-validation. For example, if we use the K-NN method, and we want to analyze how many K is the best for our model.
Why do we use boxplots in a graph?
We can also plot it to the graph so it’ll be easier to analyze. In this case, we used the boxplot to represent our accuracies.
What is repeated K fold?
Repeated K-fold is the most preferred cross-validation technique for both classification and regression machine learning models. Shuffling and random sampling of the data set multiple times is the core procedure of repeated K-fold algorithm and it results in making a robust model as it covers the maximum training and testing operations. The working of this cross-validation technique to evaluate the accuracy of a machine learning model depends upon 2 parameters. The first parameter is K which is an integer value and it states that the given dataset will be split into K folds (or subsets). Among the K folds, the model is trained on the K-1 subsets and the remaining subset will be used to evaluate the model’s performance. These steps will be repeated up to a certain number of times which will be decided by the second parameter of this algorithm and thus it got its name as Repeated K-fold i.e., the K-fold cross-validation algorithm is repeated a certain number of times.
What is a tree dataset in R?
Once all packages are imported, its time to load the desired dataset. Here “trees” dataset is used for the regression model, which is an inbuilt dataset of R language. moreover, in order to build a correct model, it is necessary to know the structure of the dataset. All these tasks can be performed using the below code.
Why is it important to explore datasets in R?
Exploration of the dataset is also very important as it gives an idea if any change is required in the dataset before using it for training and testing purposes. Below is the code to carry out this task.
What happens to the algorithm with each repetition?
With each repetition, the algorithm has to train the model from scratch which means the computation time to evaluate the model increases by the times of repetition.
What is the target variable of a dataset?
The target variable of the dataset is “Direction” and it is of the desired data type that is the factor (<fct>) data type. The values present in the dependent variable are Down and Up and they are in approximately equal proportion. If there is a case of class imbalance in the target variable then the following methods are used to correct this:
What happens in each repetition of a data sample?
In each repetition, the data sample is shuffled which results in developing different splits of the sample data.
What is the first step in R?
As the first step, the R environment must be loaded with all essential packages and libraries to perform various operations. Below is the code to import all the required libraries.
How to do k fold cross validation?
One commonly used method for doing this is known as k-fold cross-validation , which uses the following approach: 1. Randomly divide a dataset into k groups, or “folds”, of roughly equal size. 2. Choose one of the folds to be the holdout set. Fit the model on the remaining k-1 folds.
What is RMSE in math?
RMSE: The root mean squared error. This measures the average difference between the predictions made by the model and the actual observations. The lower the RMSE, the more closely a model can predict the actual observations.
What is the R-squared of a model?
Rsquared: This is a measure of the correlation between the predictions made by the model and the actual observations. The higher the R-squared, the more closely a model can predict the actual observations.
What is the MAE of a model?
MAE: The mean absolute error. This is the average absolute difference between the predictions made by the model and the actual observations. The lower the MAE, the more closely a model can predict the actual observations.
What are the three metrics in the output?
Each of the three metrics provided in the output (RMSE, R-squared, and MAE) give us an idea of how well the model performed on previously unseen data.
Steps Involved in The K-Fold Cross Validation in R
- Split the data set into K subsets randomly
- For each one of the developed subsets of data points
- Repeat the above step K times i.e., until the model is not trained and tested on all subsets
- Generate overall prediction error by taking the average of prediction errors in every case
Implement The K-Fold Technique on Classification
- Classification machine learning models are preferred when the target variable consist of categorical values like spam, not spam, true or false, etc. Here Naive Bayesclassifier will be used as a probabilistic classifier to predict the class label of the target variable.
Implement The K-Fold Technique on Regression
- Regressionmachine learning models are used to predict the target variable which is of continuous nature like the price of a commodity or sales of a firm. Below are the complete steps for implementing the K-fold cross-validation technique on regression models.
Advantages of K-Fold Cross-Validation
- Fast computation speed.
- A very effective method to estimate the prediction error and the accuracy of a model.
Disadvantages of K-Fold Cross-Validation
- A lower value of K leads to a biased model and a higher value of K can lead to variability in the performance metrics of the model. Thus, it is very important to use the correct value of K for the...
Example Data & Add-On Packages
- Install and load the class, caret, and data.tablepackage. Note that for the data.table package, we have an extra blog post here. We create some example data. For the generation, we use a binomial logistic regression model, an extensive description of which can be found in Agresti (2012) Categorical Data Analysis. Have a look at the previous output of the RStudio console. It s…
Example: K-Fold Cross-Validation with K-Nearest Neighbor
- We take the generated data from above as given and want to use k-nearest neighbor (kNN) to predict whether new observations should be classified as 1 or 0 based on their auxiliary information X. For example, we might aim for imputing missing information with kNN, as explained in our blog post here. For kNN, we have to decide for k, the number of ne...
Video & Further Resources
- I have recently released a video tutorial on the Statistics Globe YouTube channel, which illustrates the R programming code of this article. You can find the video below. The YouTube video will be added soon. Besides the video, you could have a look at the related tutorials on my homepage. A selection of posts can be found below: 1. Mean Imputation for Missing Data (Example in R & SP…