
Use the following procedure to view the Cassandra schema, which shows the replication factor for each Edge keyspace:
- Log in to a Cassandra node.
- Run the following command: > /opt/apigee/apigee-cassandra/bin/cassandra-cli -h $ (hostname -i) <<< "show schema;" Where $ (hostname -i) resolves to the IP address of the Cassandra node. Or you can replace $ (hostname -i) with the IP address of the node.
- Log in to a Cassandra node.
- Run the following command: > /opt/apigee/apigee-cassandra/bin/cassandra-cli -h $(hostname -i) <<< "show schema;"
What is replication factor in Cassandra keyspace?
The total number of replicas for a keyspace across a Cassandra cluster is referred to as the keyspace's replication factor. A replication factor of one means that there is only one copy of each row in the Cassandra cluster. A replication factor of two means there are two copies of each row, where each copy is on a different node.
Why does Cassandra store replicas on multiple nodes?
Cassandra stores replicas on multiple nodes to ensure reliability and fault tolerance. A replication strategy determines the nodes where replicas are placed. Cassandra stores replicas on multiple nodes to ensure reliability and fault tolerance. A replication strategy determines the nodes where replicas are placed.
How to get the RF details in Cassandra?
In the versions 3.0 + Cassandra you can get the RF details from the system_schema keyspace in the system_schema.keyspaces replication column. Show activity on this post.
How do I find the replication factor of a cluster?
A cluster doesn't have a replication factor, however your keyspaces does. If you want to look at the replication factor of a given keyspace, simply execute SELECT * FROM system_schema.keyspaces; and it will print all replication information you need. Show activity on this post.
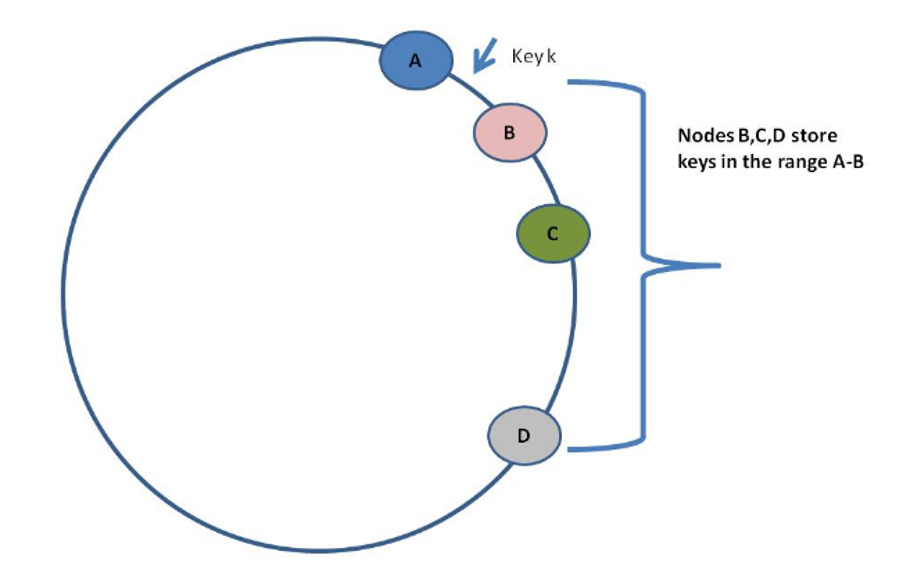
What is the replication factor?
The Replication Factor (RF) is equivalent to the number of nodes where data (rows and partitions) are replicated. Data is replicated to multiple (RF=N) nodes. An RF of one means there is only one copy of a row in a cluster, and there is no way to recover the data if the node is compromised or goes down.
How does Cassandra replicate data?
Cassandra replicates rows in a column family on to multiple endpoints based on the replication strategy associated to its keyspace. The endpoints which store a row are called replicas or natural endpoints for that row. Number of replicas and their location are determined by replication factor and replication strategy.
How do I check my consistency level in Cassandra?
To set the consistency level for your current session, use the CONSISTENCY command from the cassandra shell (CQLSH). To see your current consistency level, just run CONSISTENCY; from the shell: ty@cqlsh> consistency; Current consistency level is ONE.
How is replication handled in Cassandra?
A replication strategy determines the nodes where replicas are placed. Cassandra stores replicas on multiple nodes to ensure reliability and fault tolerance. A replication strategy determines the nodes where replicas are placed. The total number of replicas across the cluster is referred to as the replication factor.
How many replication class types are there in Cassandra?
There are two kinds of replication strategies in Cassandra.
What are all the different types of replication strategies in Cassandra?
In this article, we will discuss Different strategy class options supported by Cassandra such that SimpleStrategy, LocalStrategy, NetworkTopologyStrategy are three Replication strategy in which we generally used Simple and NetworkTopology Strategy in which LocalStrategy is used for system only.
What is the default consistency level in Cassandra?
ONEFor example, using the Java driver, call QueryBuilder. insertInto with setConsistencyLevel to set a per-insert consistency level. The consistency level defaults to ONE for all write and read operations.
How do you find a quorum in Cassandra?
In Quorum, we check the majority of replicas (which simply means the number of replication factors). for example, if we have a replication factor of 3 in 2 data centers then how many their replicas will be there. so, there will be 6 and the majority is 4.
How do you maintain consistency in Cassandra?
Often you can choose CL. QUORUM at read and write time to ensure consistency and tolerate node failures. For example at RF=3 a QUORUM needs (3/2)+1=2 nodes available, so R+W>N will be 4>3 - your requests are consistent AND you can tolerate a single node failure.
What is replication factor in Kafka?
A replication factor is the number of copies of data over multiple brokers. The replication factor value should be greater than 1 always (between 2 or 3). This helps to store a replica of the data in another broker from where the user can access it.
What does Read_repair_chance do in Cassandra?
read_repair_chance (and dclocal_read_repair_chance ) is configured for each table, defaulting to 0.1 (10% chance). When it occurs (only with read consistency levels higher than ONE ), Apache Cassandra will verify the consistency of the replica with all other nodes not involved in the read request.
Does Cassandra use leaderless replication?
Riak, Voldemort, Cassandra are open source data stores with leaderless replication models, inspired by Dynamo.
How does Cassandra distribute data?
It accomplishes this using partitions. Each node owns a particular set of tokens, and Cassandra distributes data based on the ranges of these tokens across the cluster. The partition key is responsible for distributing data among nodes and is important for determining data locality.
How does Cassandra store data?
When a write occurs, Cassandra stores the data in a memory structure called memtable, and to provide configurable durability, it also appends writes to the commit log on disk. The commit log receives every write made to a Cassandra node, and these durable writes survive permanently even if power fails on a node.
Does Cassandra use leaderless replication?
Riak, Voldemort, Cassandra are open source data stores with leaderless replication models, inspired by Dynamo.
How does Cassandra Sharding work?
DynamoDB and Cassandra – Consistent Hash Sharding With consistent hash sharding, data is evenly and randomly distributed across shards using a partitioning algorithm. Each row of the table is placed into a shard determined by computing a consistent hash on the partition column values of that row.
When to set replication strategy in Cassandra?
In Cassandra, You set the replication strategy at the keyspace level when creating the keyspace or later by modifying the keyspace.
Can you change replication factor in a keyspace?
first, you can create any keyspace and then you can change the replication factor or if you have existing keyspace then you can change in the same way.
Can you change the keyspace name in Cassandra?
In Cassandra, You can’t alter the name of a keyspace. It is always a good practice after changing the replication factor or any modification you can execute the repair command. You can execute the following CQL query for full repair. nodetool repair -full. Attention reader! Don’t stop learning now.
Where to find RF details in Cassandra?
In the versions 3.0 + Cassandra you can get the RF details from the system_schemakeyspace in the system_schema.keyspacesreplicationcolumn.
How to check replication factor?
If you want to look at the replication factor of a given keyspace, simply execute SELECT * FROM system_schema.keyspaces;and it will print all replication information you need.
Is there a default value for replication factor?
There is no default value for this setting. When you create a keyspace you have to specify the replication factor.
How to set up Cassandra replication?
To set up Cassandra Replication successfully, you need to set up three distinct nodes and run them as separate terminals before you associate them with a Cassandra cluster. You can implement Cassandra Replication successfully using the following steps: Step 1: Installing Java and Cassandra. Step 2: Setting up Cassandra Nodes.
What are the components of Cassandra?
The Cassandra architecture typically consists of the following components: 1 A node that stores the data. 2 A data centre that acts as a collection of nodes spread across numerous locations. 3 A cluster that contains multiple data centres. 4 Commit table, mem-table, SS table, and bloom filter to support the smooth functioning of internal architecture components.
What is Cassandra database?
Cassandra is a robust open-source NoSQL database/storage system that houses a highly distributed/ decentralised architecture that delivers high data availability and performance with nearly zero downtime. Leveraging its distributed nature and intuitive functionalities such as linear scalability, it allows users to handle petabytes of data and store it across numerous cloud-based environments while carrying out hundreds of data operations in parallel. Its internal architecture takes inspiration from Amazon Dynamo and Google’s BigTable data model and thus houses a replication model that has no single points of failure.
What is Cassandra query language?
Query Support: Cassandra allows users to query data using the Cassandra Query Language (CQL). CQL is highly similar to SQL, and hence, users need to spend a large amount of time to get familiar with it.
What is zero downtime Cassandra?
Zero-Downtime: Cassandra houses the support for high and real-time data availability by leveraging its distributed nature. It replicates data across numerous cloud-based data centres and switches automatically to a healthy node in case of failure, ensuring that data is always available to users.
What is data replication?
Data replication refers to the process of creating and storing multiple copies of data across various locations, thereby boosting the availability of data across a particular network. With replication in place, you can either replicate your entire database or a distinct portion of it, as per your data needs, either for an individual system or across numerous servers.#N#distinct
Can you use a select statement to create multiple replicas for Cassandra?
With your replication strategy now set up, you can use a select statement to create multiple replicas for your Cassandra instance as follows:
Author
Want to talk with an expert? Schedule a call with our team to get the conversation started.
About the Author
Kanthi Rekha is an experienced Cassandra DBA currently working as a Database Consultant with The Pythian Group. She is an avid learner and Datastax Certified Cassandra Architect and has a comprehensive understanding of distributed architecture technologies.
What are the three Replication strategies supported by Cassandra?
In this article, we will discuss Different strategy class options supported by Cassandra such that SimpleStrategy, LocalStrategy, NetworkTopologyStrategy are three Replication strategy in which we generally used Simple and NetworkTopology Strategy in which LocalStrategy is used for system only. let’s discuss one by one.
What is replication_factor in strategy_demo?
Let’s consider taking an example, strategy_demo is a keyspace name in which class is SimpleStrategy and replication_factor is 2 which simply means there are two redundant copies of each row in a single data center. let’s have a look.
Why does Cassandra store replicas?
Cassandra stores replicas on multiple nodes to ensure reliability and fault tolerance. A replication strategy determines the nodes where replicas are placed. The total number of replicas across the cluster is referred to as the replication factor. A replication factor of 1 means that there is only one copy of each row in the cluster.
What does replication factor 1 mean?
A replication factor of 1 means that there is only one copy of each row in the cluster. If the node containing the row goes down, the row cannot be retrieved. A replication factor of 2 means two copies of each row, where each copy is on a different node. All replicas are equally important; there is no primary or master replica.
How many replicas are there in a datacenter?
Three replicas in each datacenter: This configuration tolerates either the failure of one node per replication group at a strong consistency level of LOCAL_QUORUM or multiple node failures per datacenter using consistency level ONE.
How does NetworkTopologyStrategy place replicas in the same datacenter?
NetworkTopologyStrategy places replicas in the same datacenter by walking the ring clockwise until reaching the first node in another rack. NetworkTopologyStrategy attempts to place replicas on distinct racks because nodes in the same rack (or similar physical grouping) often fail at the same time due to power, cooling, or network issues.
Is there a master replica?
All replicas are equally important; there is no primary or master replica. As a general rule, the replication factor should not exceed the number of nodes in the cluster. However, you can increase the replication factor and then add the desired number of nodes later. Two replication strategies are available:
Can you have three replications in one datacenter?
Asymmetrical replication groupings are also possible. For example, you can have three replicas in one datacenter to serve real-time application requests and use a single replica elsewhere for running analytics.